# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
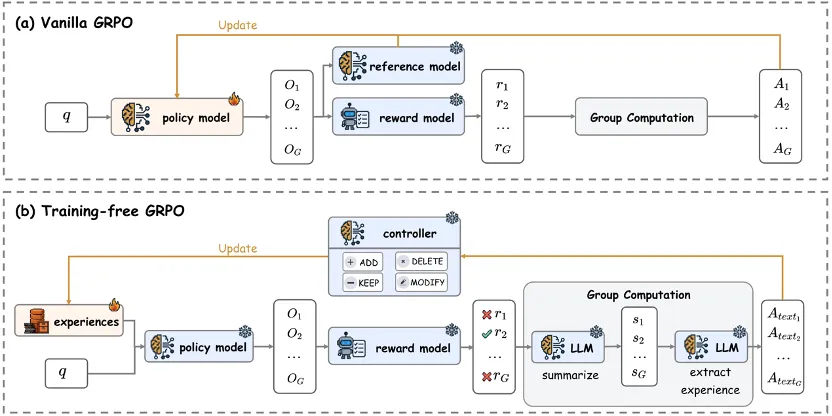
年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
GRPO 的核心思路很简单却强大:
这种「多路径并行 + 组内优势」的机制,虽然比传统 PPO 等方法更加简洁,但仍然需要优化模型参数,💰 太贵了!
这让 GRPO 虽然强大,却几乎只能由巨头来玩,中小团队和个人开发者根本「玩不起」。
能不能不改模型参数,也来跑一遍 GRPO?
腾讯优图的一篇最新论文就提出了一个非常有意思的答案:既然更新参数这么贵,那就不更新参数,直接把 GRPO 的「学习过程」搬进上下文空间!

Training-Free GRPO 是把 GRPO 训练的整个范式迁移到了上下文学习之中:
举个例子,对于训练集里这道数学几何题,模型会生成多个不同的解答路径(Rollout),可能会出现不同的解题路径,有的做对了有的做错了。
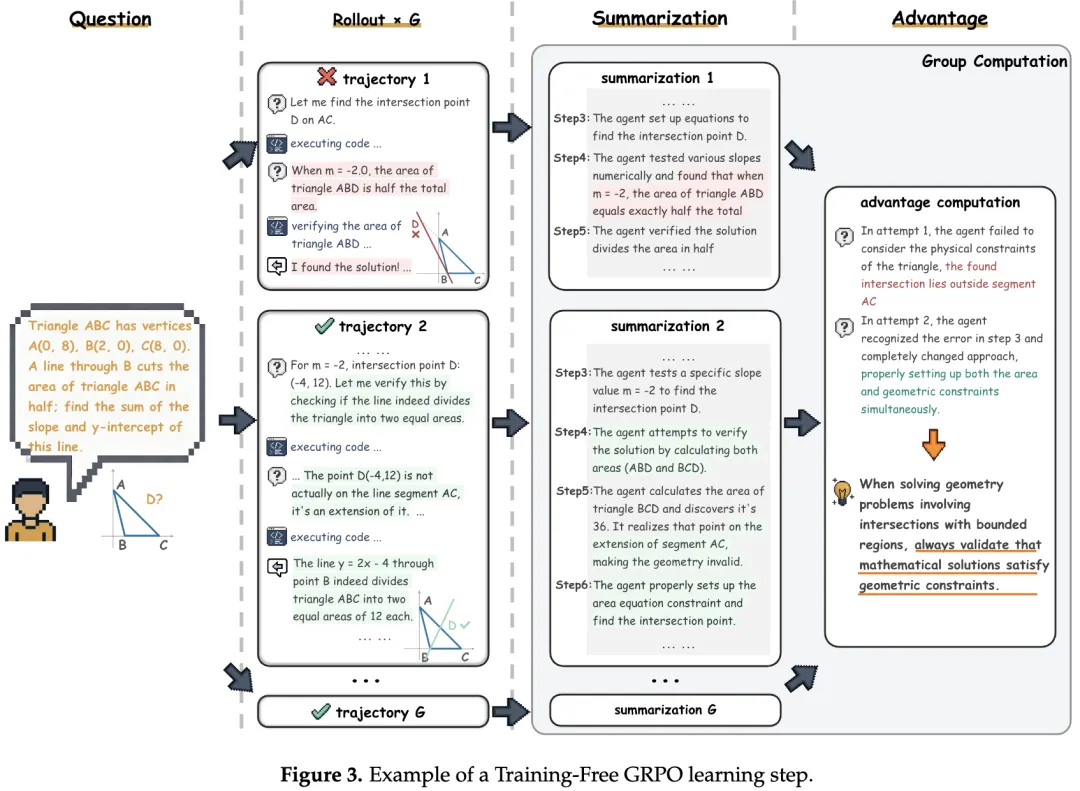
随后,模型总结不同解法的过程与正确性,从而比较同一组内的不同解答。这个过程自然提炼出文本型组内优势:总结出有的做法为什么对,有的做法为什么错。比如例子里:
在一个迭代里,得到每道题的文本型组内优势后,模型就把当前批次的优势都更新文本型 LoRA 里,也就是对经验库进行增删改,沉淀学习到的经验。
在数学推理上,仅用 100 个训练样本,花费约 8-18 美元,就能在已经足够强大的 671B 模型上继续提升性能。
无论是否采用代码工具(CI,code interpreter)帮助解题,在 AIME 榜单上的 Mean@32 指标都能实现提升。
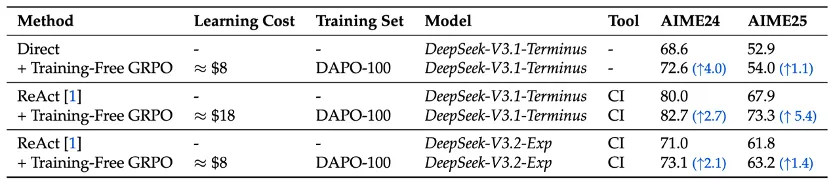
令人惊喜的是,在三个轮次中,训练集和测试集的平均工具调用次数均有所减少。这表明 Training-Free GRPO 不仅能够鼓励正确的推理和行动,还能教会代理找捷径,更高效明智地使用工具。
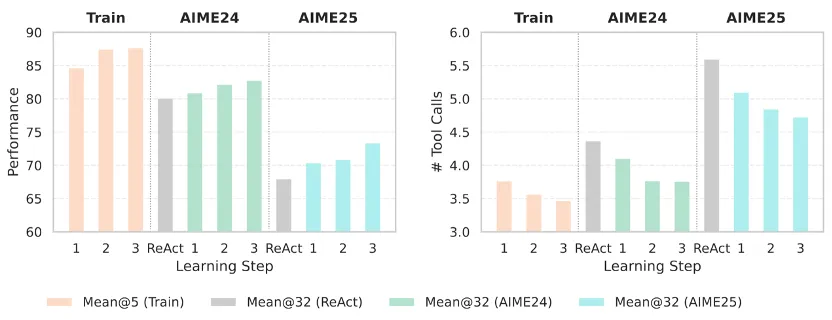
而在网页搜索场景中,Training-Free GRPO 同样无需更新模型参数,即可在 DeepSeek-V3.1-Terminus 强悍水平之上,实现了 4.6% 的 Pass@1 显著提升。

多路径探索、group advantage、多轮迭代、完全独立的训练与测试集……这些 GRPO 的精华一项不少,全部在上下文层面重现了出来。
不用训练模型参数,仅需少量数据,并且全程只靠 API 随用随付!
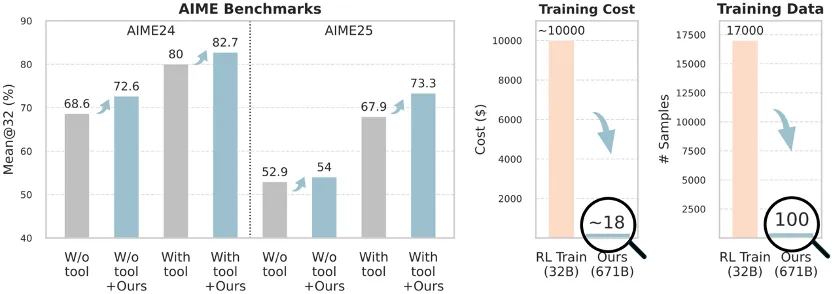
只需 8~18 美元以及 100 条训练数据,就能在 671B LLM 上跑完多轮的强化学习训练!远远低于 32B 模型的训练成本。
与 Self-Refine 这类就地改写不同,Training-Free GRPO 是在独立数据集上多轮迭代训练的,对测试集里的 Out-of-Domain (OOD) 数据都有显著提升。
并且,参数微调后的 32B 级别模型往往只能胜任特定窄域任务,可能需要多个专用模型来覆盖完整业务需求,显著增加了系统复杂度和维护成本。而 Training-Free GRPO 只需要一个统一的模型和 API 就可以泛化到不同的场景!
过去我们默认,强化学习就意味着参数更新。虽然前期有一些上下文空间优化的探索如 Self-Refine、Reflexion、TextGrad 等,但 Training-Free GRPO 与他们不同,完全对齐了参数空间 RL 训练的流程和细节:
本文方法已开源,欢迎 Star 和试用!
预告:Training-Free GRPO 将作为一个新功能集成到 Youtu-Agent 框架中,帮助开发者们进一步提升各种自定义场景的效果。
注:成本计算基于 DeepSeek API 官方定价,实际可能因使用情况而有所波动。
文章来自于“机器之心”,作者“机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
