
具身智能最缺的“空间常识”,被这套隐空间强化学习一次性补全 | ECCV‘26
具身智能最缺的“空间常识”,被这套隐空间强化学习一次性补全 | ECCV‘26大规模视频扩散模型,画面越来越真,却总在“物理定律”上栽跟头。
来自主题: AI技术研报
5284 点击 2026-07-29 13:49
 搜索
搜索
大规模视频扩散模型,画面越来越真,却总在“物理定律”上栽跟头。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。
很多人认为这个数字不是随便挑的:美国政府向 Anthropic 下发出口管制指令、切断 Fable 5 与 Mythos 5 境外访问权限的那一刻,正是美国东部时间下午 5 点 21 分。「5 点 21」这个数字上的重复,被多家媒体解读为一次刻意设计的呼应。智谱选择在这个节点站出来,相当于当着全世界开发者的面说了一句话:你们担心的「模型随时可能被收回」,开源这边没有这个问题。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
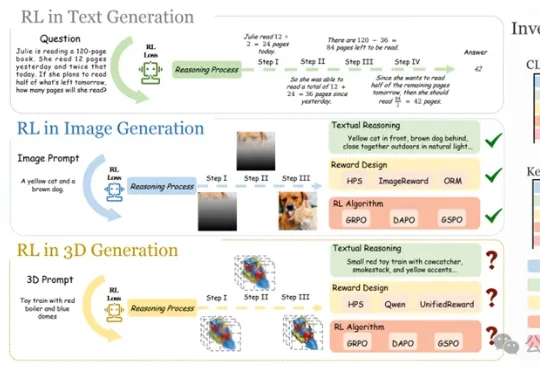
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
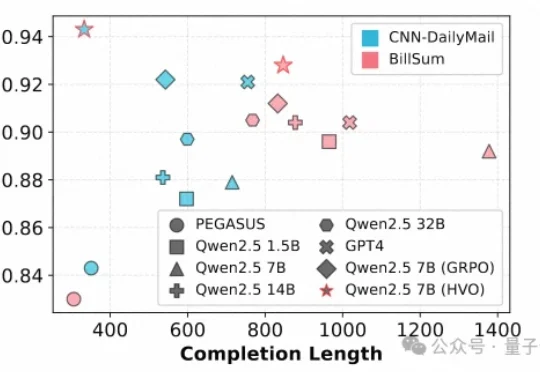
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
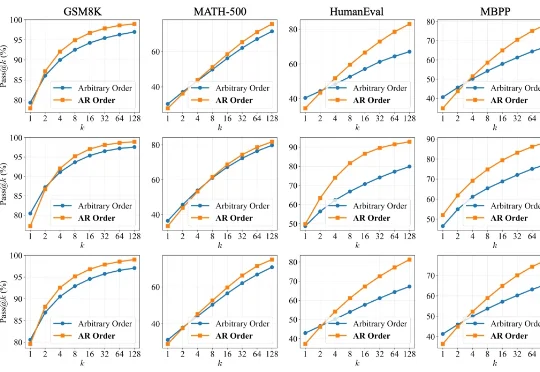
扩散语言模型(Diffusion LLMs, dLLMs)因支持「任意顺序生成」和并行解码而备受瞩目。直觉上,打破传统自回归(AR)「从左到右」的束缚,理应赋予模型更广阔的解空间,从而在数学、代码等复杂任务上解锁更强的推理潜力。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。

DeepSeek 一发布模型,总会引起业内的高度关注与广泛讨论,但也不可避免的暴露出一些小 Bug。