# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型在强化学习过程中,终于知道什么经验更宝贵了!
来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO——
通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。

实验结果显示,与传统的在线策略RLVR(基于可验证奖励的强化学习)方法相比,ExGRPO在不同基准上均带来了一定程度的性能提升。
尤其在一些极具挑战性的任务(如AIME数学竞赛题)上,提升效果更为明显,证明了ExGRPO在攻克复杂推理难题上的有效性。
而且该研究也揭示了一些有趣的现象,比如滚雪球效应。
不过在展开之前,我们先来回答一个核心问题——
2025年初以来,赋能大模型推理能力的技术路线以基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards)为主导。
简单来说,就是让模型像个学生一样,不断地“刷题”(生成推理步骤),然后由“判卷老师”(奖励模型)来打分,模型根据分数高低调整自己的“解题思路”。
但RLVR存在一个天然缺陷:经验浪费。
在标准的RLVR训练中,模型生成的推理轨迹(Rollouts)只会被使用一次,之后就被丢弃。这意味着模型从来不会回头复盘,甚至不记得自己是如何答对或答错的。
以现实世界作比,它们像一个只做新题、从不复习的学生。每当模型做完一道题,无论这道题的解法多么精妙、多么有启发性,都可能都会在一次参数更新后,把这次宝贵的“解题经验”忘得一干二净。
这种“学完就忘”的模式,由于Rollout代价昂贵不仅导致了计算资源浪费,也让训练过程变得非常不稳定。
因此,学会“温故而知新”,让模型根据“错题本”,把每一次宝贵的成功经验都内化为自己的能力对训练效率和能力提升都至关重要。
值得注意的是,强化学习著名学者David Silver和Richard S. Sutton在《Welcome to the Era of Experience》的Position Paper中提到:
人类数据正在用尽,经验将是下一个超级数据源,是能够为AI带来能力提升的下一个突破口。
但是,一个看似简单却被忽视的问题是:
既然经验这么重要,那么什么样的经验才值得反复学习?在大模型全面铺开应用的当下,面对经验这个超级数据源的增长,其量级和高复杂性之高是我们不得不考虑的因素。
针对这一挑战,ExGRPO框架应运而生。
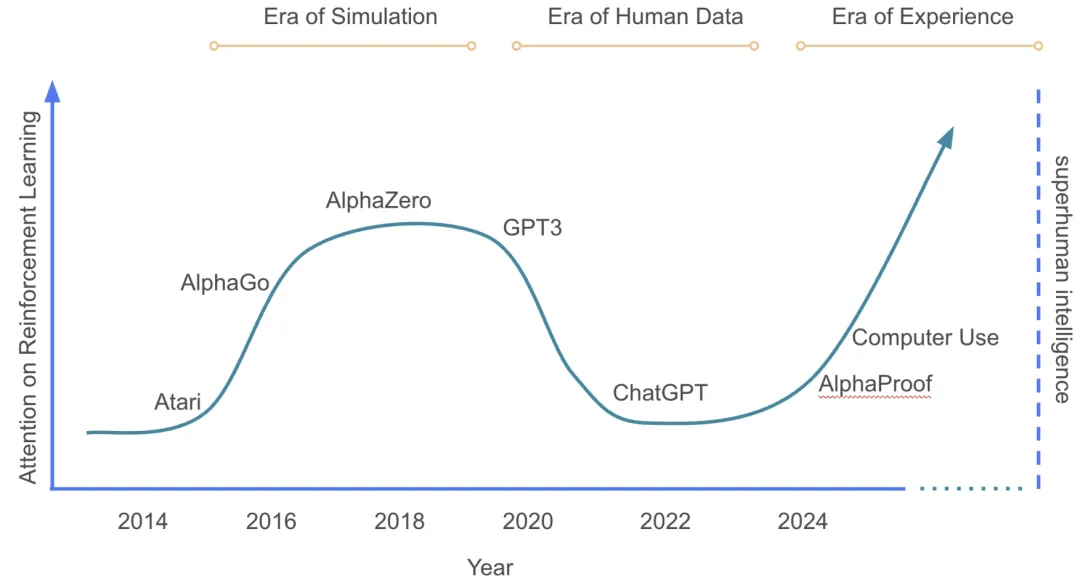
图1. 主流人工智能范式的简要时间轴示意图。纵轴表示该领域总投入和计算资源中专注于强化学习(RL)的比例。截取自David Silver, Richard S. Sutton. Welcome to the Era of Experience.
在设计一个“复习”系统前,我们首先要搞清楚一个根本问题:
对一个正在学习推理的模型来说,什么样的“解题经验”才是最有价值的?是不是所有做对的题目都值得反复回味?
为了找到答案,该工作进行了一系列有趣的探索性实验(见图2),并发现,一份“高质量”的经验,其价值体现在两个关键维度上:问题的难度和解题路径的质量。
作者把模型在训练中遇到的问题,根据它当下的“正确率”动态地分成了三类:简单题(正确率>75%)、中等题(25%-75%)和难题(<25%)。
然后,分别只用这三类问题来进行On-Policy RLVR训练模型。
结果一目了然:只刷“中等难度”问题的模型,最终性能提升最大。
这也符合一般直觉,简单题模型通常已经掌握了,反复练习边际效益递减,容易“学废”;对于难题,远超模型当前能力,强行学习容易让模型“受挫”,产生胡乱猜测的坏习惯。
而中等难度的题恰好处于模型的最近发展区,既有挑战性,又能通过努力解决,是学习效率最高的甜蜜点。
另一方面,同样是做对一道题,解题过程(下文也称为轨迹)的质量也千差万别。
有的解法思路清晰、一步到位;有的则绕来绕去、充满了不确定性,甚至可能是蒙对的。如何量化这种解题思路的质量呢?
外部的强模型也许是一个选择,但是在训练中使用代价过高并且会拖慢速度。
为了找到可靠的在线代理指标,作者以较强能力的Qwen3-32B模型作为参考:评价推理过程的对错,并看看有没有内源性的在线指标能够和外部Judge的判断正相关。
在此,作者发现推理轨迹的Token平均熵是一个优秀的指标,在所有做对的题目中,那些推理过程逻辑更正确的解法,其对应的熵值显著更低。
进一步地,高熵轨迹很多时候只是幸运的瞎猜,反复学习这些轨迹不仅没有帮助,反而可能污染模型的逻辑能力。
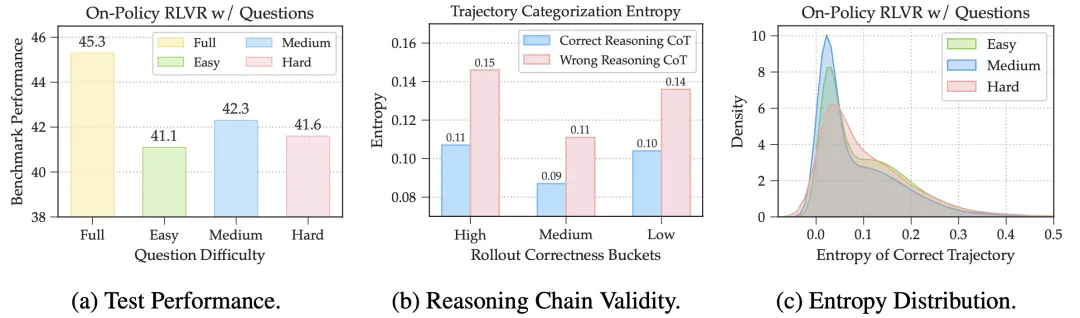
图2:模型经验=问题+对应推理过程。什么才是“好问题”和“好推理过程”? (a) 使用中等难度问题训练的模型性能最佳。(b) 逻辑正确的推理过程通常表现出更低的熵值。 (c) 中等难度推理正确的熵值也更密集于低熵值区域。
这样符合我们的认知直觉:在人类学习中,难度适中的题目、逻辑清晰的解法,往往是最高效的学习材料。太简单的题目让人停滞不前,太难的题目则令人无从下手。
基于上述洞见,作者设计了ExGRPO框架,包含了两个核心部件:经验管理和混合经验优化。
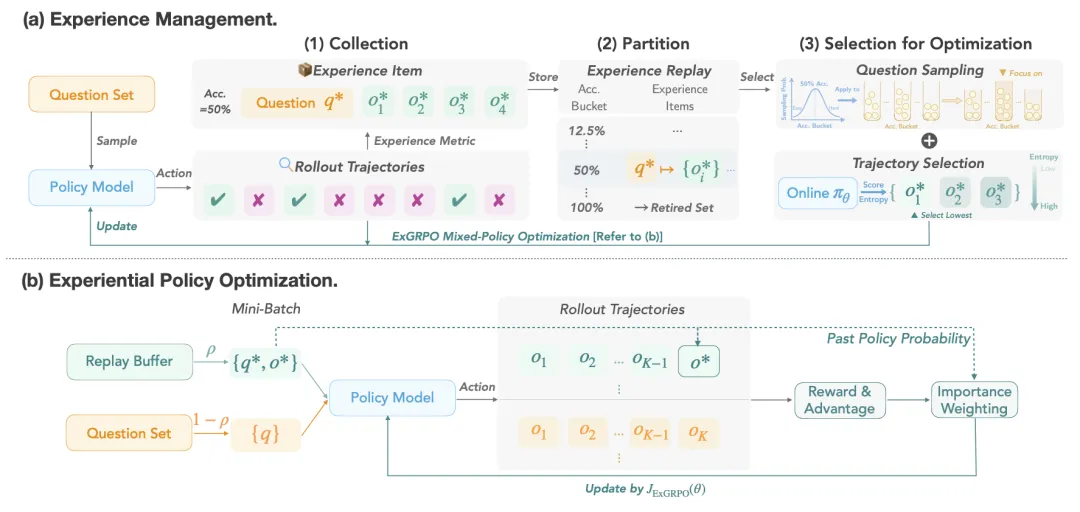
△图3:ExGRPO框架概览:经验管理 + 策略优化
作者将模型经验定义为问题+对应推理过程,分两个层级进行经验的管理和挑选,具体它分为三步:
1、经验收集:ExGRPO会建立一个“经验回放池”,像一个巨大的“错题本”,专门收集模型在训练过程中所有成功的推理案例。这也是传统强化学习和先前相关工作中均拥有的基础机制。
2、经验划分与存储:根据每个问题最新的“在线正确率”,将经验池中的问题动态地划分到不同的“难度分区”里。这就像给错题本按章节和难度进行分类。这样,所有经验都被贴上了“简单”、“中等”、“困难”的标签,管理起来一目了然。
同时,为了防止模型在简单问题上“刷分”而产生过拟合,ExGRPO还拥有一个“退休机制”(Retired Set),将模型已经完全掌握(例如连续多次全部成功解答)的问题移出学习队列,让模型始终聚焦于更具挑战性的任务。
3、经验筛选:按照之前分析实验得到的启示和洞见,ExGRPO从两个层次挑选经验:
通过这套精细化管理,确保了每次复习的都是最高质量的黄金经验。
选好了复习材料,接下来就是如何复习经验了。
ExGRPO采用了一种混合策略的优化目标,除了对重要性采样进行修正外,在每一次训练迭代中,Mini-Batch中一部分计算资源用于让模型探索全新的问题(On-policy),另一部分则用于学习从经验池中精心筛选出的经验(Off-policy)。
巧妙地平衡了探索新知(On-Policy Exploration)和复习旧识(Experience Exploitation)。

图4:ExGRPO混合策略优化目标。ρ代表经验在Mini-Batch优化中的混合比例。
这种“一半时间学新,一半时间复习”的模式,让模型既能不断拓展认知边界,又能持续巩固和内化已有的成功经验,从而在保证训练稳定性的同时,极大地提升了学习效率。
此外,作者还引入了策略塑形(Policy Shaping)机制,确保模型在复习过往成功经验时,不会变得过于僵化,丧失探索创新的能力。
作者在6个不同规模(1.5B到8B)和架构(Qwen、Llama)的模型(Base、Instruct)上,对ExGRPO进行了全面的测试,涵盖了从AIME、MATH等数学推理的 benchmark,到GPQA、MMLU-Pro等通用推理benchmark。
与传统的在线策略RLVR方法相比,平均所有模型和测试集,ExGRPO相对于On-Policy方法(Dr. GRPO),分别带来了+3.5和+7.6个点的分布内、分布外性能提升。
尤其在一些极具挑战性的任务(如AIME数学竞赛题)上,提升效果更为明显,证明了ExGRPO在攻克复杂推理难题上的有效性。
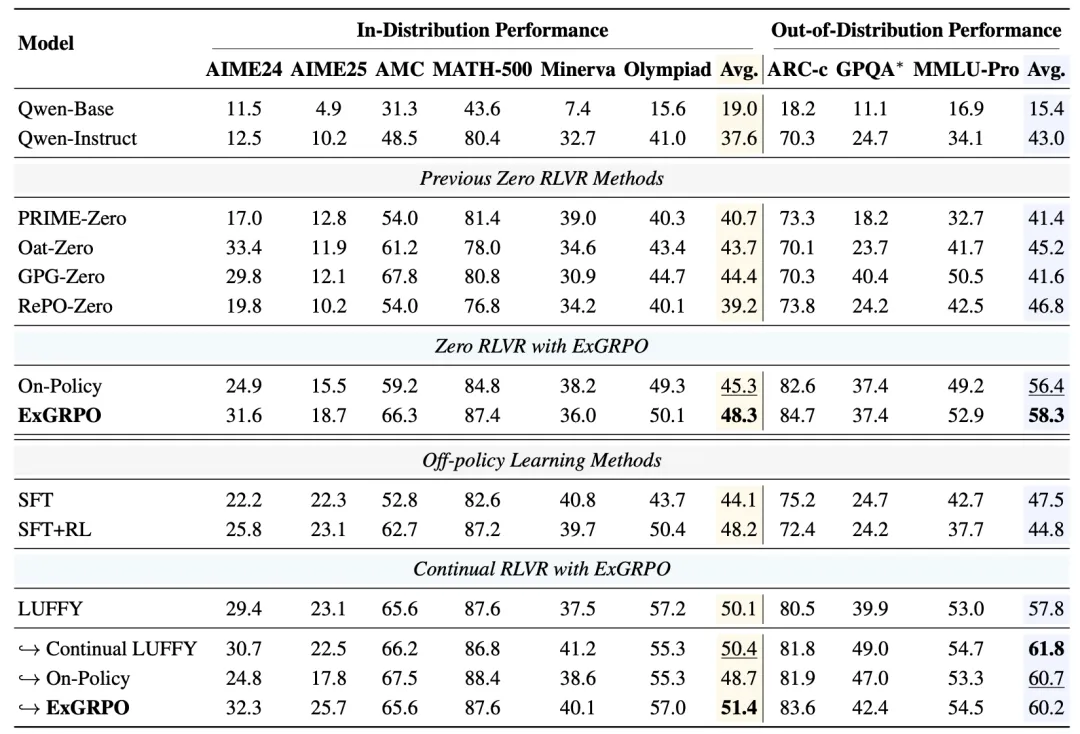
△表1:ExGRPO在多个数学与通用推理基准上的性能表现
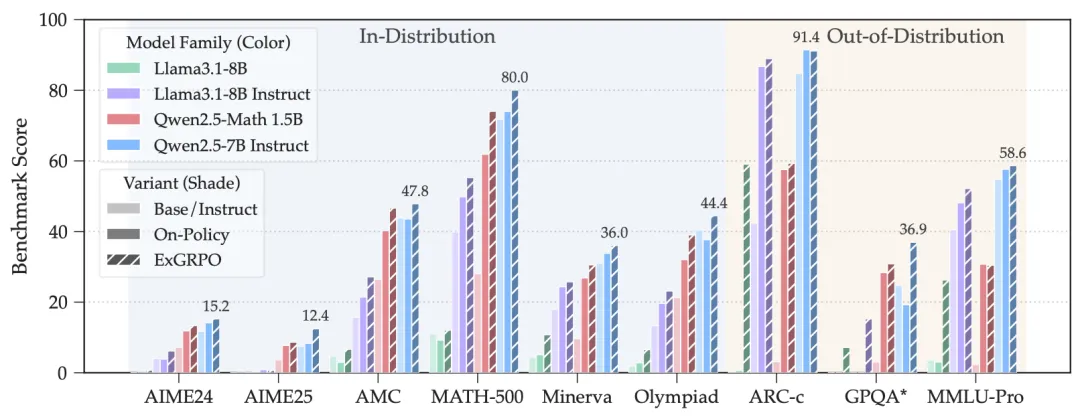
△图5:ExGRPO在不同模型架构和尺寸上的泛化能力
即使是在已经很强的模型(如经过外部R1轨迹数据作为RLVR引导的LUFFY)上进行持续学习,ExGRPO依然能带来稳定的性能增益,而标准的在线RL方法反而会导致性能下降。
此外,作者发现对于像Llama-3.1 8B Base基模,由于其初始推理能力较弱,标准的On-Policy强化学习方法根本无法进行有效训练,很快就会训练崩溃。
而ExGRPO凭借其经验回放机制,能够捕捉到早期偶然的lucky hits,并将其作为宝贵的学习信号反复利用,最终成功地将模型“救活”并稳定地提升其性能。
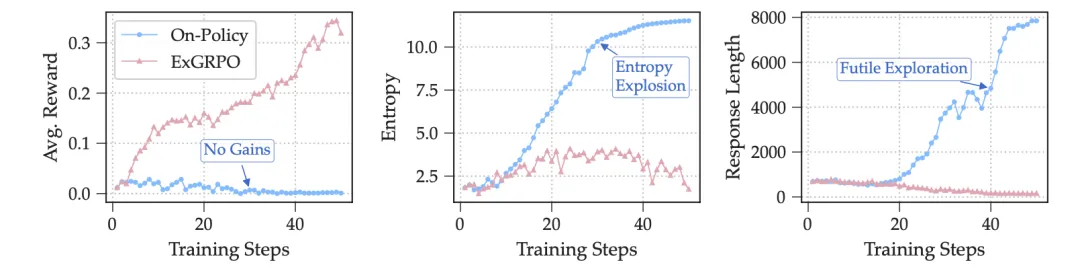
图6:在Llama-3.1 8B训练过程中On-Policy与ExGRPO的学习动态对比。ExGRPO能够稳定训练并获得更高的奖励,而On-Policy则容易出现训练崩溃。
此外,该研究也揭示了一些有趣的现象,比如滚雪球效应。高熵的经验中,经常包含着一些看似正确但逻辑上有瑕疵的步骤(比如在数学题里滥用代码块来黑箱计算)。
如果让模型反复学习这些经验,就会像滚雪球一样,让错误的推理习惯根深蒂固。ExGRPO的经验筛选机制,切断了这种错误学习的路径。
正如强化学习领域的先驱David Silver和Richard Sutton所言:
我们正处于一个新时期的风口浪尖,在这个时期,经验将成为能力提升的主要媒介。
团队表示,ExGRPO的核心贡献,是为模型推理能力的提升,提供了一套系统性的、基于经验的学习框架。有理由相信, Principled Experience Management(有原则的经验管理)将成为未来构建更强大、更高效的AI模型训练生态中的关键一环。
它不再让宝贵的成功经验付诸东流,而是通过智能地识别、管理和重放高价值经验,像错题本一般,让模型真正拥有了“温故而知新”的能力。
这不仅显著提升了训练的效率和稳定性,也为我们打开了通往更强大、更通用的人工智能的一扇新窗。
论文:https://arxiv.org/pdf/2510.02245
Code:https://github.com/ElliottYan/LUFFY/tree/main/ExGRPO
模型:https://huggingface.co/collections/rzzhan/exgrpo-68d8e302efdfe325187d5c96
文章来自于微信公众号“量子位”。


