# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何让一个并不巨大的开源大模型,在面对需要多步检索与复杂逻辑整合的问题时,依然像 “冷静的研究员” 那样先拆解、再查证、后归纳,最后给出可核实的结论?
近期,来自埃默里大学,佐治亚理工大学,罗格斯大学,纽约州立大学奥尔巴尼分校,得克萨斯大学西南医学中心的研究团队发布 AceSearcher 模型,一个让同一语言模型在推理时兼任 “问题分解者(Decomposer)” 与 “答案求解者(Solver)” 的合作式自博弈框架:它以两阶段训练(SFT→RFT)为骨架,把 “会拆题、会找料、会整合” 的完整能力链拧成了一根绳。更重要的是,这不是单纯的 “又一个新模型”,而是一个更优的框架:它把公开的推理数据集引入到检索增强的训练流程中,让模型真正学会如何把推理与检索结合起来,显著提升了复杂检索任务的效果。
在三大类推理密集任务、十个数据集上,它拿到了平均 EM +7.6% 的优势;32B 版本在文档级金融推理上,表现可对标 685B 的 DeepSeek-V3,但参数量却不到 5%。

现实世界的问题,常常不是 “一问一答” 能解决:线索散落在不同文档,需要多跳检索把证据拼齐,还要在此基础上进行跨段落乃至跨文档的整合推理。传统 RAG 在这里容易 “卡壳”—— 单步检索召回不足、推理链整合不稳、推理时扩展又容易带来延迟和资源开销。

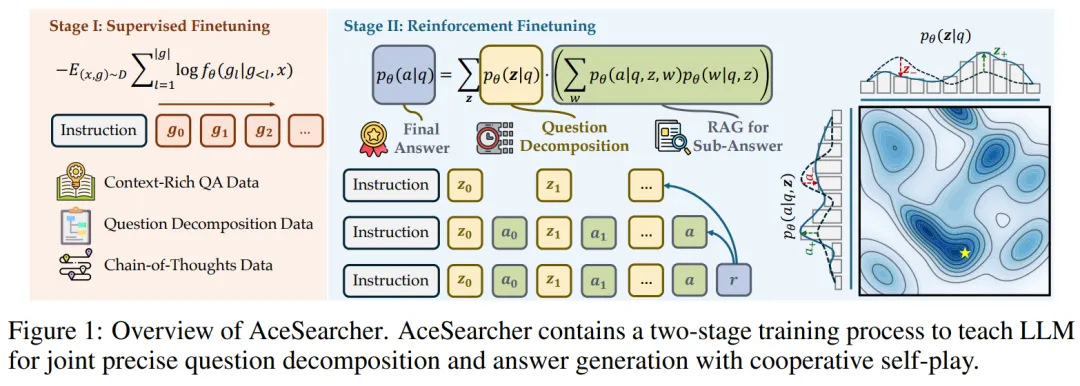
一、Stage I:监督微调(SFT)——“打底三件套”:会搜、会拆、会想
SFT 阶段的训练集是一个覆盖面很广的混合拼盘(约 18 万样本),包括:
1. 上下文丰富的 QA(NQ、SQuAD、DROP、NarrativeQA、Quoref、ROPES、FEVER、TAT-QA),让模型学会在证据上作答;
2. 问题分解数据(GSM8K、ConvFinQA、StrategyQA),让模型学会把复杂问题拆成子目标;
3. 链式推理数据(GSM8K、TabMWP、IfQA、MathInstruct 等 CoT/PoT),让模型形成多步推理的 “肌肉记忆”。
这一步的关键是:AceSearcher 首次系统地把这些公开的推理数据集,与检索增强任务结合起来。我们希望模型不仅学会了 “如何在上下文中找答案”,更学会了 “如何通过推理去驱动检索、再通过检索去支撑推理”。这是它与以往 RAG 方法最大的差别之一。
二、Stage II:偏好强化微调(RFT)—— 只看 “最终答案”,也能学会 “更好的过程”
现实里很难拿到 “中间推理步骤” 的标注。AceSearcher 的 RFT 阶段因此选择只用最终答案来给奖励:

实现上还有两个细节很 “工程”:

在这里,利用推理数据集预训练出来的 “分解与推理能力”,在 RFT 阶段通过最终答案奖励被进一步固化和迁移到复杂检索任务,形成了推理与检索的真正耦合。
论文的评测覆盖三个任务大类,共十个公开数据集:
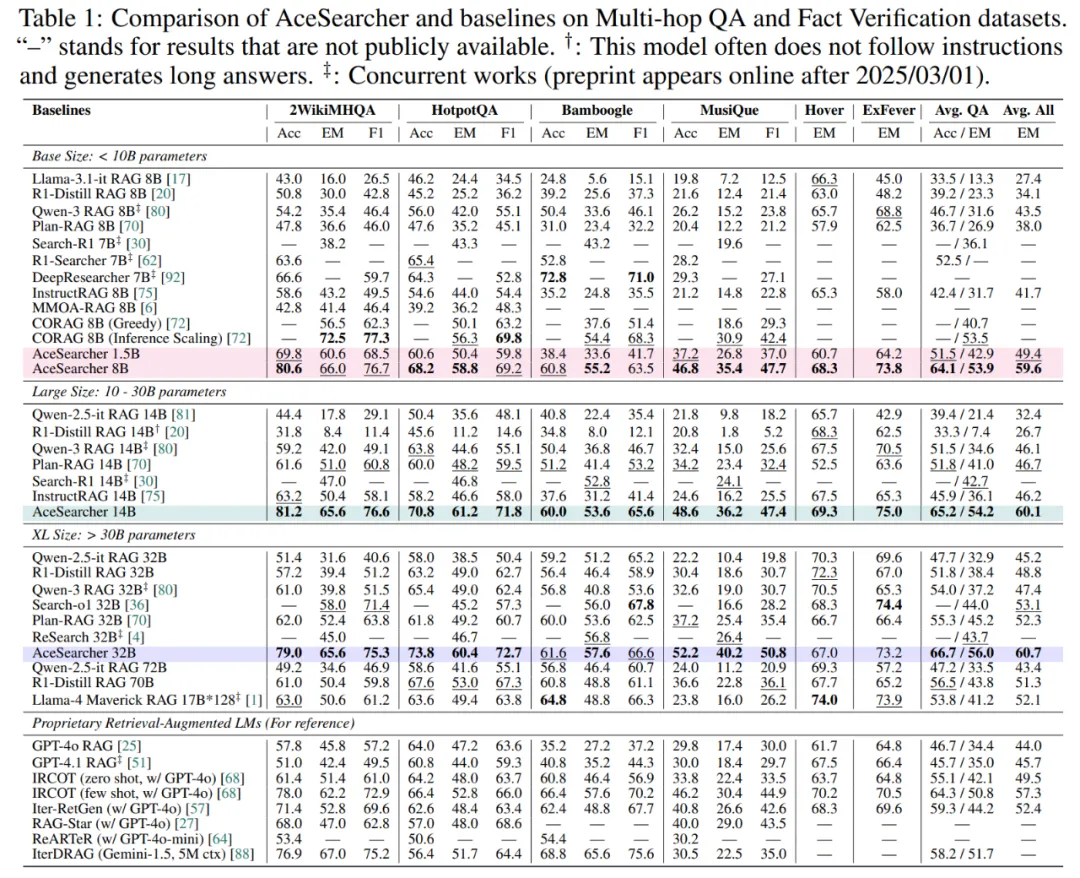
1)多跳 QA / 事实验证:平均提升 7.6%,小中模型亦能 “越级”
在六个数据集的综合评测中(2WikiMHQA、HotpotQA、Bamboogle、MusiQue、HOVER、ExFEVER),AceSearcher 全面优于近期开源 / 闭源基线;其中 32B 版本的综合得分达到 60.7,相对多种强基线的平均 EM 最高可增 7.6%。更具代表性的是 “参数效率”:1.5B 版本已可对标 / 超越 8B 级基线,8B 版本还压过 70B 级模型。
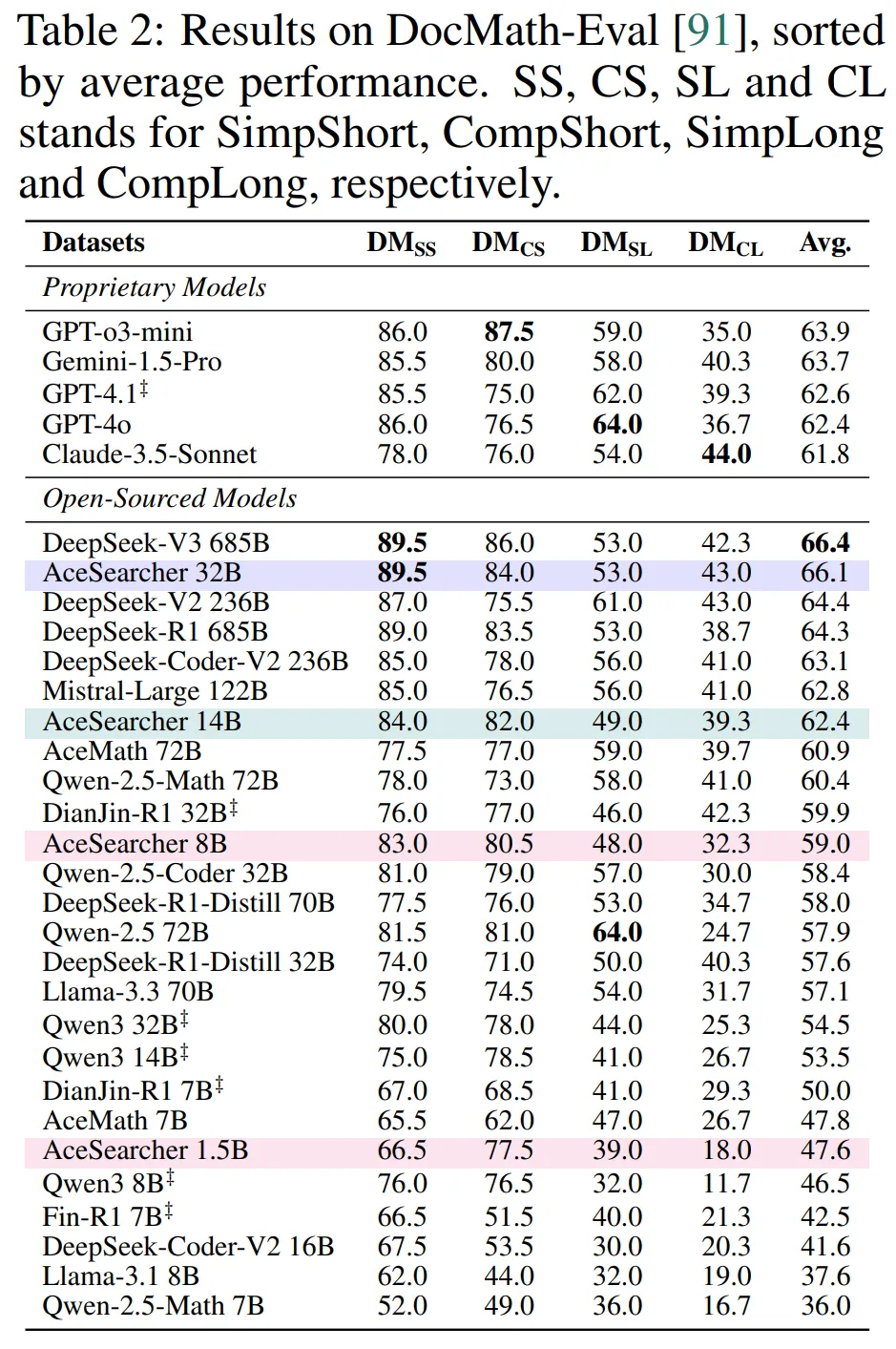
2)文档级推理:32B ≈ DeepSeek-V3@685B(≈1/20 参数)
在 DocMath-Eval 上,AceSearcher-32B 的平均准确率与 DeepSeek-V3(685B) 几乎持平;14B 版本还超过了若干 72B 级模型;8B 相对同量级 / 略大模型亦有明显优势。这表明 “分解→检索→整合” 的统一范式,能在长文档与表格混合的复杂情境里保持稳健的泛化。
3)效率与可扩展性:少量数据就能 “拉满”,推理 - 时间性价比更优
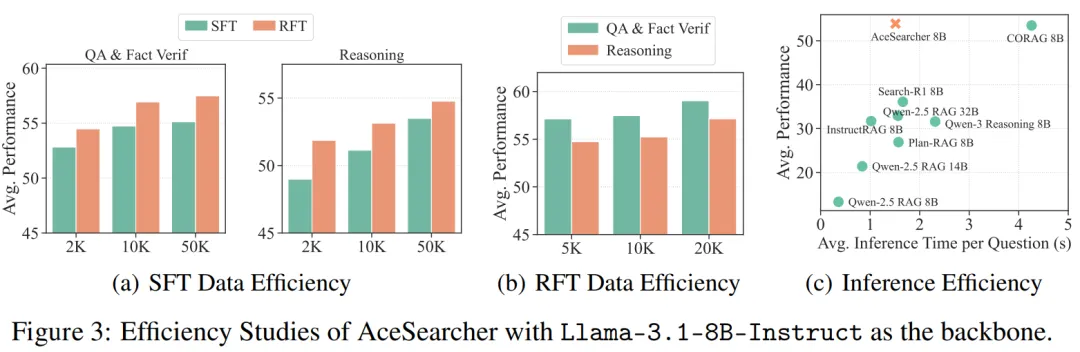
系统消融清晰地回答了这个问题:

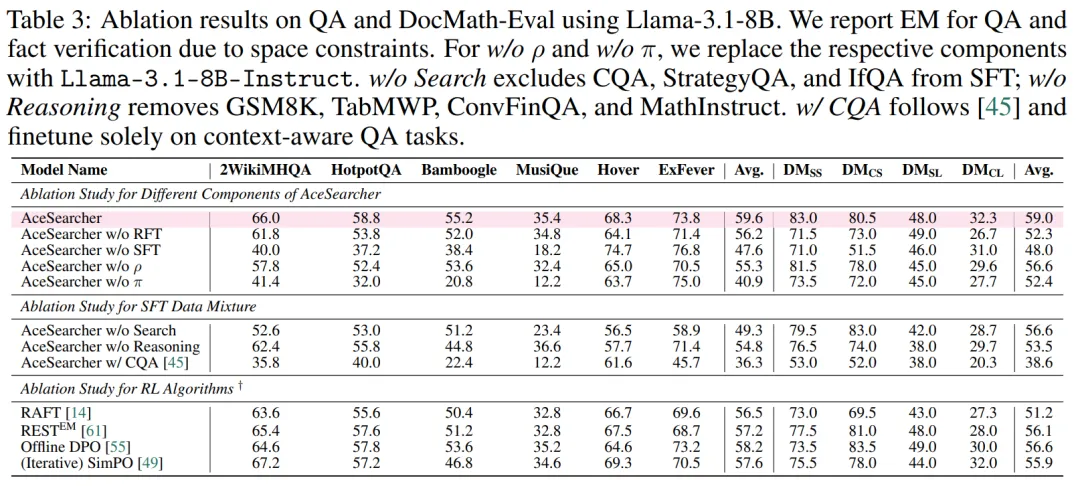
AceSearcher 证明了:聪明的训练范式胜过盲目扩参。接下来有三条有潜力的路:
1. 检索 - 推理联合优化:目前检索器固定,未来可尝试把检索表征、重排与生成策略联学,进一步提高 “证据命中→推理稳定” 的闭环质量;
2. 极端时延场景的工程优化:在保持性能的前提下做缓存、动态步长与早停机制;
3. 更广任务类型:从多跳问答 / 事实验证 / 长文档,扩展到对话式信息采集、实时工具使用、跨模态检索等。
文章来自于“机器之心”,作者“机器之心”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
