# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。

DiDi-Instruct 蒸馏得到的 “学生” 模型与教师模型、GPT-2 的文本生成效率对比。
DiDi-Instruct 提出了一种独创的概率分布匹配的后训练策略,可以将原本需要 500 步以上的昂贵的扩散语言 “教师”(diffusion Large Language Model, dLLM)模型,蒸馏成一个仅需 8-16 步生成整个文本段落的 “学生” 模型。在 OpenWebText 标准数据集上,DiDi-Instruct 语言模型既实现了超过 64 倍以上的推理加速,又在性能上同时显著超越了被蒸馏的教师扩散语言模型(dLLM,1024 步生成)和自回归的 GPT2 模型(1024 步生成)。DiDi-Instruct 算法同时提升了大语言模型的推理效率和推理效果。为极端高效的大语言模型落地提供了新的方案。

近年来,以自回归(ARMs)范式为核心的大语言模型(如 ChatGPT,DeepSeek 等模型)取得了巨大成功。然而,自回归模型逐词串行生成的固有瓶颈,使其在长文本生成时面临难以逾越的延迟 “天花板”,即使强大的并行计算硬件也无计可施 。作为一种新兴的替代范式,扩散语言模型(后文将用 dLLM 指代)应运而生。dLLM 将文本生成重塑为一个从完全噪声(或掩码)序列中迭代去噪、恢复出完整文本的过程 。这一模式天然支持并行化语言段落生成,相较于自回归模型生成速度更快。然而尽管如此,现有最好的 dLLM 在同等模型尺寸下为了达到与 GPT-2 相当的性能,仍然需要多达上百次模型迭代。这个困境不禁让人疑惑:是否存在模型在极端少的迭代次数下(如 8-16 次迭代)下能显著超越 1024 次迭代的 GPT 模型?
在上述研究背景下,本篇文章提出了 DiDi-Instruct。简而言之,DiDi-Instruct 是一个 dLLM 的后训练算法。一个 dLLM 通过 DiDi-Instruct 算法训练蒸馏之后,可以将原本的 1024 次推理次数压缩至 8 到 16 步,同时可以显著提升的 dLLM 的建模效果。
DiDi-Instruct 的理论来源于连续扩散模型中的一个经典单步蒸馏算法:Diff-Instruct。从理论上看,DiDi-Instruct 训练算法的核心思想是最小化一个少采样步数的 “学生” 模型与多采样步数的 “教师” dLLM 模型在整个离散 Token 去噪轨迹上分布的积分 KL 散度(Integral Kullback-Leibler Divergence)。该目标把不同时间的 KL 以权重积分汇总,避免只对齐末端样本而训练不稳的问题,从而让学生以一种全局、全过程匹配的方式,高效 “学习” 教师的精髓。一旦积分 KL 散度被优化至收敛(接近 0 值),少步生成的 “学生” 模型便在概率意义上吸收了 "教师 dLLM" 的知识。
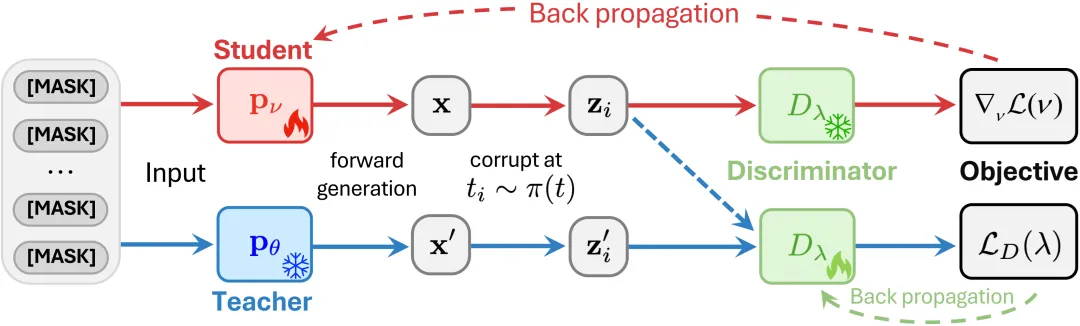
DiDi-Instruct 流程示意:学生模型(Student)与教师模型(Teacher)从全掩码序列重建 “干净文本”,并同时进行加噪处理。随后,判别器(Discriminator)对两者输出进行区分并给出奖励分数,用作学生模型的更新信号,使其在后续生成中逼近教师分布。经过反复迭代,Student 能以更少步数获得接近 Teacher 的生成质量。
然而,想要直接优化积分 KL 散度面临诸多例如离散文本不可微分等理论困难。针对这些挑战,DiDi-Instruct 提出了一套系统性的解决方案,其关键创新包括:

DiDi-Instruct 后训练算法。

奖励驱动的祖先采样算法。
研究团队在公开的 OpenWebText 数据集上进行了详尽的实验,结果出人出人意料:经过 DiDi-Instruct 后训练的语言模型在效率和效果上得到了双重提升。
1. 性能与质量新标杆:DiDi-Instruct 在生成质量和效率上均达到了新的 SOTA 水平。该工作系统性地将 DiDi-Instruct 与 GPT-2、MDLM、DUO、SDTT 等多个基准模型进行了比较。结果显示,在 OpenWebText 数据集上,DiDi-Instruct 在 8 到 128 步的所有函数评估次数(NFEs)设置下,其困惑度(Perplexity)指标全面且持续地优于所有基准模型。一个尤为亮眼的成果是,仅需 16 步函数评估,DiDi-Instruct 生成的文本质量 Perplexity(PPL)就已经超越了需要 1024 步才能完成生成的教师模型,相比最强的基线模型提升超过 30%。同时,这些性能增益是在几乎没有熵损失(约 1%)的情况下实现的,充分保证了生成内容的多样性。
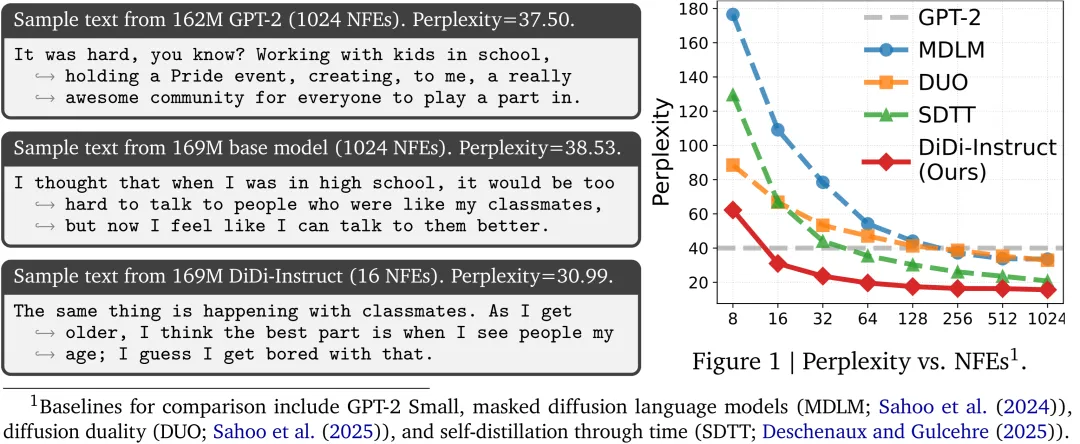
DiDi-Instruct 蒸馏所得学生模型与基准模型在不同函数评估次数(NFEs)下的文本生成困惑度(PPL)对比。
2. 训练效率大幅提升:DiDi-Instruct 不仅生成质量高,其训练(蒸馏)过程也极为高效。出人意料的时候,整个蒸馏框架的训练仅需在单张 NVIDIA H100 GPU 上运行约 1 小时即可完成。相比之下,其他同类蒸馏方法(基线模型)通常需要超过倍以上的训练时间。这意味着 DiDi-Instruct 将训练效率提升了超过 20 倍,极大地降低了开发者迭代和部署高性能生成模型的门槛。
3. 跨领域通用性验证:研究团队在报告中指出,DiDi-Instruct 的蒸馏框架是为离散扩散模型设计的,并不局限于语言模型。为了验证这一点,团队将其成功应用于一个完全不同的领域:无条件蛋白质序列生成。他们使用一个预训练的蛋白质语言扩散模型(DPLM)作为教师模型进行蒸馏。结果表明,蒸馏后的学生模型保留了教师模型生成可变长度序列的能力,同时大幅降低了推理成本。更重要的是,学生模型在极少步数下即可生成结构合理的高置信度蛋白质结构。这一跨领域实验有力地证实了 DiDi-Instruct 作为通用离散序列生成加速框架的巨大潜力。
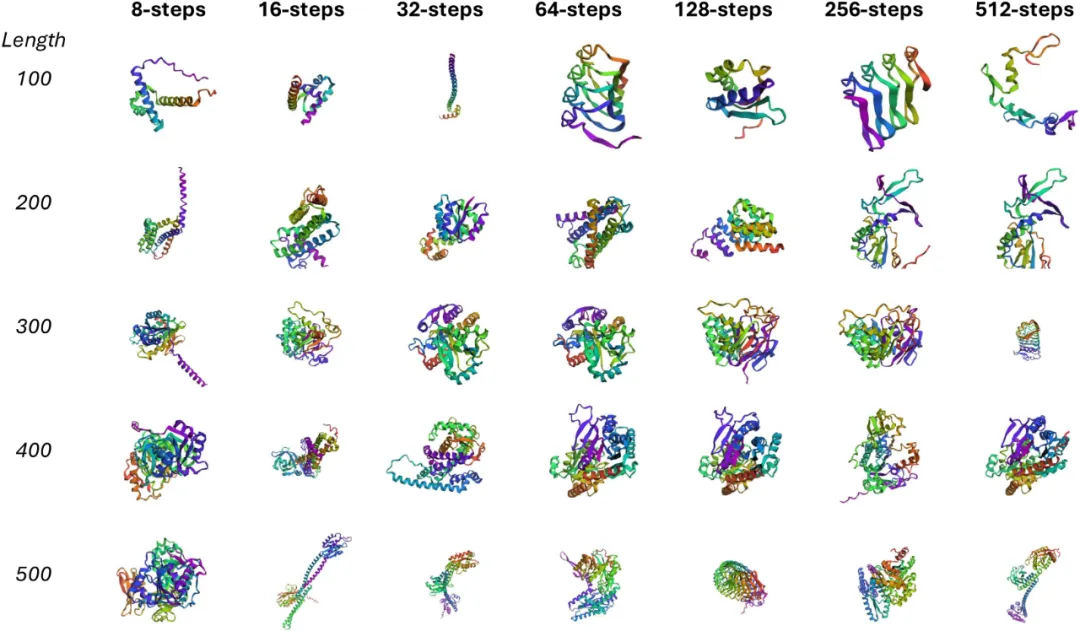
由 DiDi-Instruct 蒸馏得到的学生模型生成的 高置信度蛋白质序列(pLDDT > 70)。
4. 深入消融实验,探究各组件的核心贡献:为了科学地验证每个创新组件的必要性和贡献,研究团队还进行了详尽的 “逐项累加”(cumulative)和 “逐一剔除”(leave-one-out)的消融研究。这些实验揭示了模型性能的关键驱动因素:
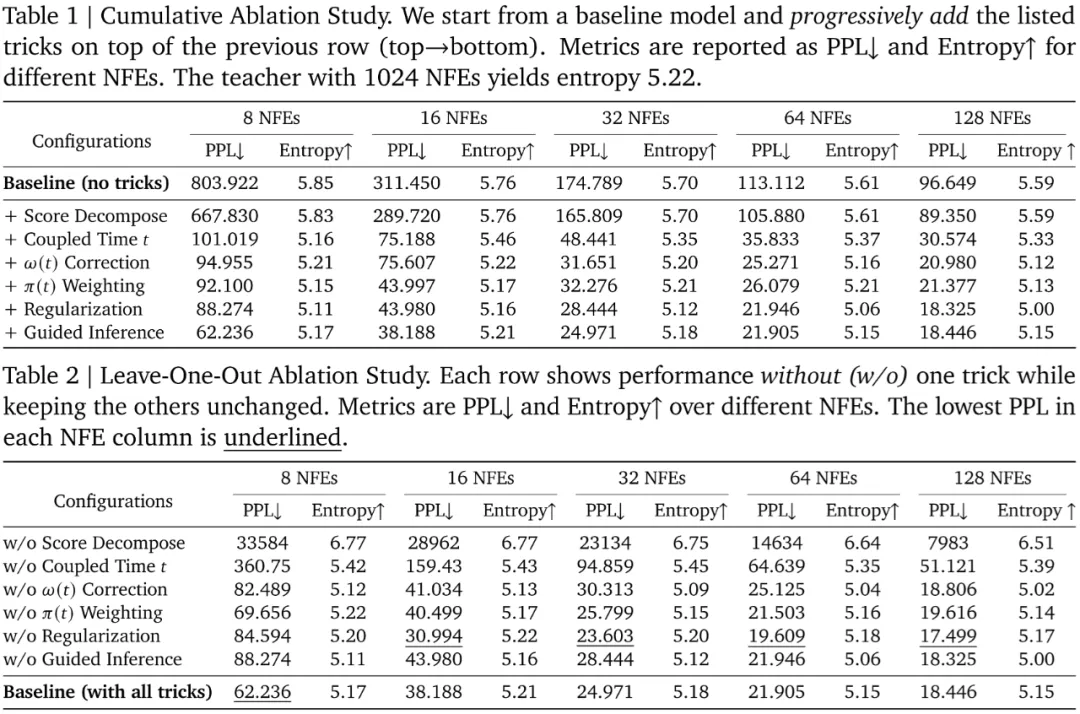
“逐项累加” 消融实验结果见表 1,“逐一剔除” 消融实验结果见表 2。
DiDi-Instruct 的提出,不仅是离散扩散模型加速技术的一次技术突破,也为广泛的大语言模型的极限加速,对齐和强化学习提供了新的思路。它首次成功地将分布匹配蒸馏思想应用于基于掩码的离散扩散模型,并建立了一套集 “分布匹配目标、稳定训练、高效推理” 于一体的完整框架。这项工作展示了通过系统性的算法与框架设计,可以克服现阶段大语言模型在生成效率上的瓶颈,使其成为下一代 AI 内容生成中(多模态生成、代码生成、生物序列设计等领域)极具竞争力的选项。我们非常期待将 DiDi-Instruct 应用于最前沿的超大规模的扩散语言模型的效果。
本论文第一作者郑昊阳,目前于美国普渡大学攻读博士学位,导师为林光老师。林光是普渡大学的 Moses Cobb Stevens 教授兼理学院副院长。论文的两位通讯作者罗维俭和邓伟分别是小红书 hi-lab 的多模态研究员和纽约摩根士丹利的机器学习研究员。
文章来自于“机器之心”,作者“机器之心”。


【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
