# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
为了从根本上解决VAE带来的诸多限制,EPG中提出通过自监督预训练(SSL Pre-training)与端到端微调(End-to-End Fine-tuning)相结合的方式,彻底去除了生成模型对VAE的依赖。

其核心优势在于:
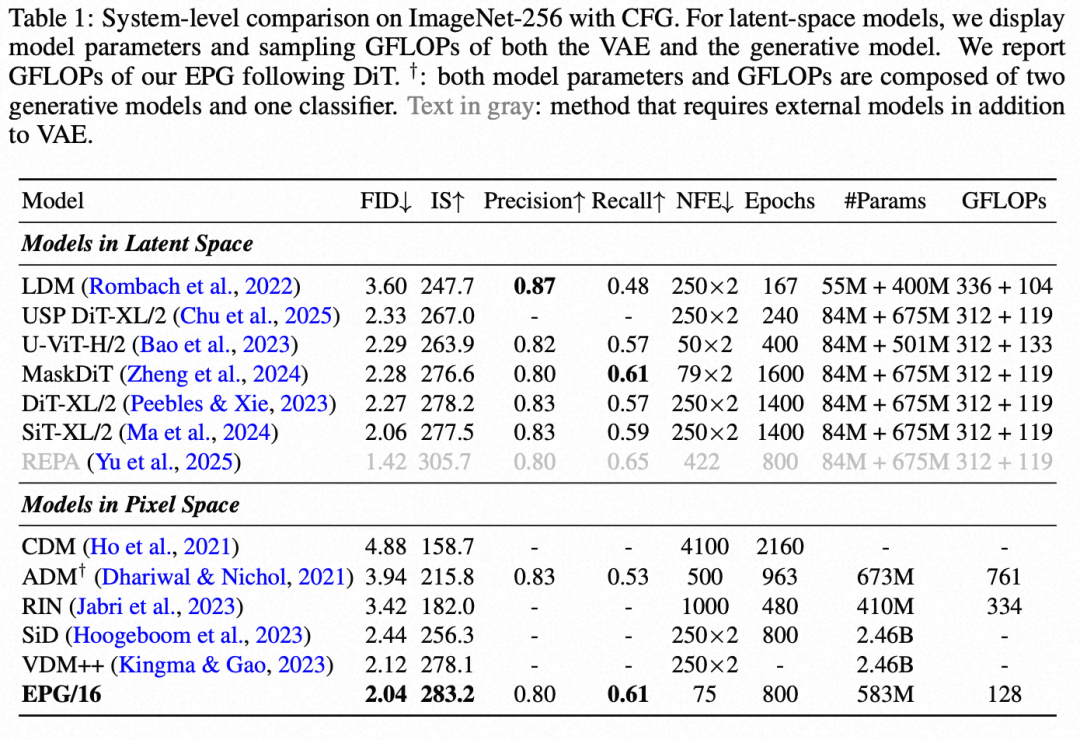
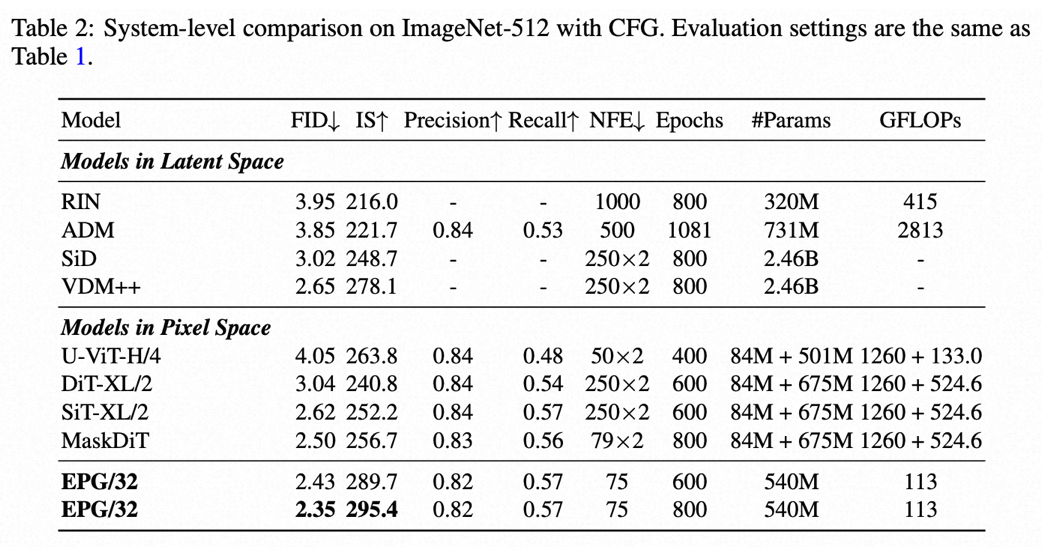
训练效率与生成效果双重突破:在ImageNet-256和512数据集上,EPG在训练效率远超基于VAE的主流模型DiT/SiT的同时,仅仅通过75次模型前向计算就取得了更优的生成质量,FID分别达到了2.04和2.35。

首次实现像素空间的一致性模型训练:在不依赖VAE及预训练的扩散模型权重的前提下,EPG首次成功在像素空间中端到端地训练了一致性模型(Consistency Model),在ImageNet-256上仅需单步即可取得8.82的FID。
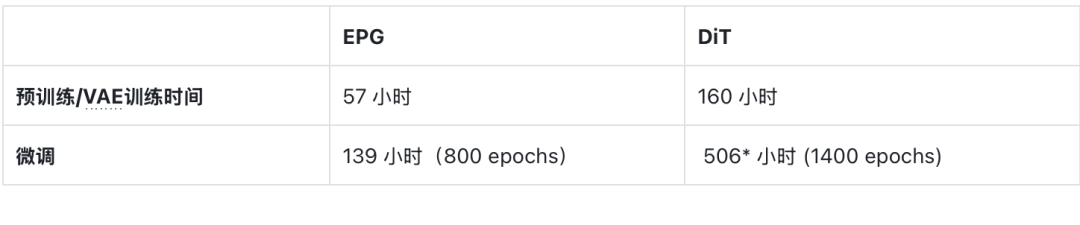
△在8xH200上测得的训练开销。*: 基于官方代码预估
EPG的核心思想借鉴了计算机视觉领域经典的“预训练-微调”范式,将复杂的生成任务解耦为两个更易于处理的阶段。
第一阶段:自监督预训练 (SSL Pre-training) —— 解耦表征学习与像素重建
EPG的核心洞察在于,生成模型本质上需要从带噪图像中学习高质量的视觉表征。受此启发,EPG创新地将学习表征与重建像素解耦为两个独立的学习阶段。
在第一阶段,模型仅需利用自监督表征学习算法,从带噪图像中提取高质量的视觉特征。这一阶段只训练模型的前半部分网络——编码器(Encoder)。然而,现有表征学习方法难以直接应用于噪声图像,尤其当噪声完全覆盖图像内容时。
为解决此问题,EPG提出了一种简洁而高效的解决方案:让模型在干净图像上学习“标准”表征,再通过一致性损失将该表征对齐(传递)给带噪图像的表征。具体地,文中选取ODE采样路径上的相邻两点作为带噪图像对,以保证每个带噪版本都能学习到唯一的、与干净图像对齐的表征。
此阶段的预训练损失函数包含两部分:a. 对比损失 (Contrastive Loss):从干净图像中学习高质量的初始表征。 b. 表征一致性损失 (Representation Consistency Loss):将带噪图像的表征与干净图像的表征对齐。
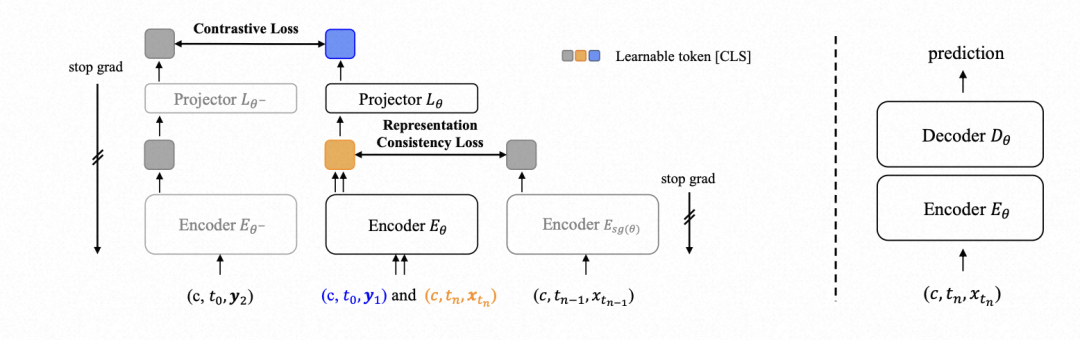
△训练方法总览。
(左图)预训练方法。c是一个可学习表征,t0, tn, tn-1为时间步条件,y1,y2为每一次训练所采样图片x0进行数据增强后的图像,xtn, x_tn-1为ODE采样路径上时序上相邻的两点。θ是网络参数,θ^-是\theta的EMA版本,sg表示stop gradient操作。(右图)端到端微调方法。预训练结束后,仅使用Eθ 加随机初始化的解码器D_θ进行端到端微调。
第二阶段:端到端微调 (End-to-End Fine-tuning) —— 无缝衔接下游生成任务
预训练阶段完成后,EPG的微调过程十分直接:将预训练好的编码器(Eθ)与一个随机初始化的解码器(Dθ)拼接,然后直接使用扩散模型或一致性模型的损失函数进行端到端微调。
EPG的训练框架与经典的图像分类任务框架高度相似,这极大地简化了生成模型的训练流程,降低了开发和应用下游生成任务的门槛。
EPG在ImageNet-256和ImageNet-512两大标准数据集上验证了其有效性。
将去噪训练作为微调目标(扩散模型)的生成效果:
将一致性训练作为微调目标(单步生成)的生成效果:
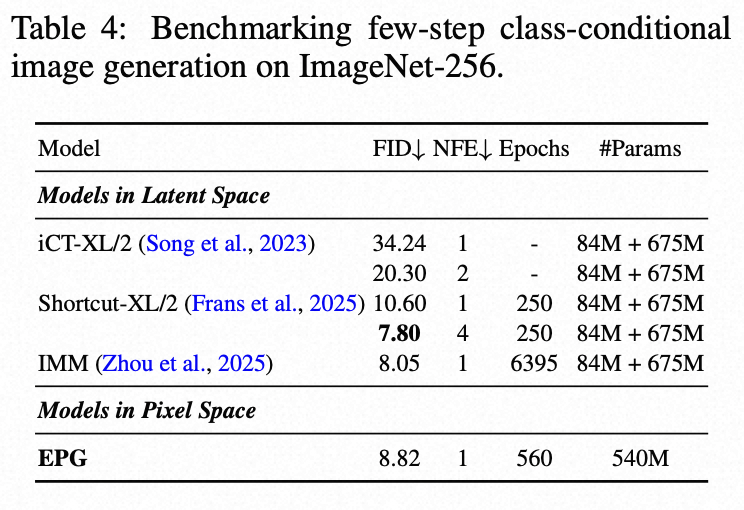
训练效率与生成质量:
实验证明,EPG框架不仅完全弥补了以往像素空间训练与隐空间训练在效率和效果上的差距,更在同等计算资源下实现了超越。这为未来在更高分辨率、更大数据集上的训练,乃至视频生成等领域,提供了极具参考价值的解决方案。
推理性能:
基于EPG训练的扩散模型,在推理时仅需75次模型前向计算即可达到最优效果,步数远低于其他方法。此外,EPG的骨干网络采用Vision Transformer(ViT)且Patch Size为16x16,在256x256图像上的单张生成速度可媲美DiT;在512x512图像上(使用32x32的Patch Size),其生成速度依然能和在256x256的速度保持一致,展现了优异的可扩展性。
EPG框架的提出,为像素空间生成模型的训练提供了一条简洁、高效且不依赖VAE的全新路径。
通过“自监督预训练 + 端到端微调”的两阶段策略,EPG成功地将复杂的生成任务分解为目标明确的表征学习和像素重建两个步骤。这不仅使其在训练效率和最终生成质量(FID低至2.04)上全面超越了依赖VAE的DiT等主流模型,更重要的是,EPG首次在完全不依赖任何外部预训练模型(如VAE或DINO)的情况下,实现了像素空间内一致性模型的端到端训练,取得了单步生成8.82 FID的优异成绩。
这项工作不仅为图像生成领域带来了性能与效率的双重提升,也为视频生成、多模态统一模型等前沿方向提供了极具潜力的基础框架。EPG所代表的“去VAE化”、端到端的训练范式,将进一步推动生成式AI的探索与应用,降低开发门槛,激发更多创新。
论文链接:
https://arxiv.org/pdf/2510.12586
代码仓库链接:
https://github.com/AMAP-ML/EPG
文章来自于“量子位”,作者 “允中”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
