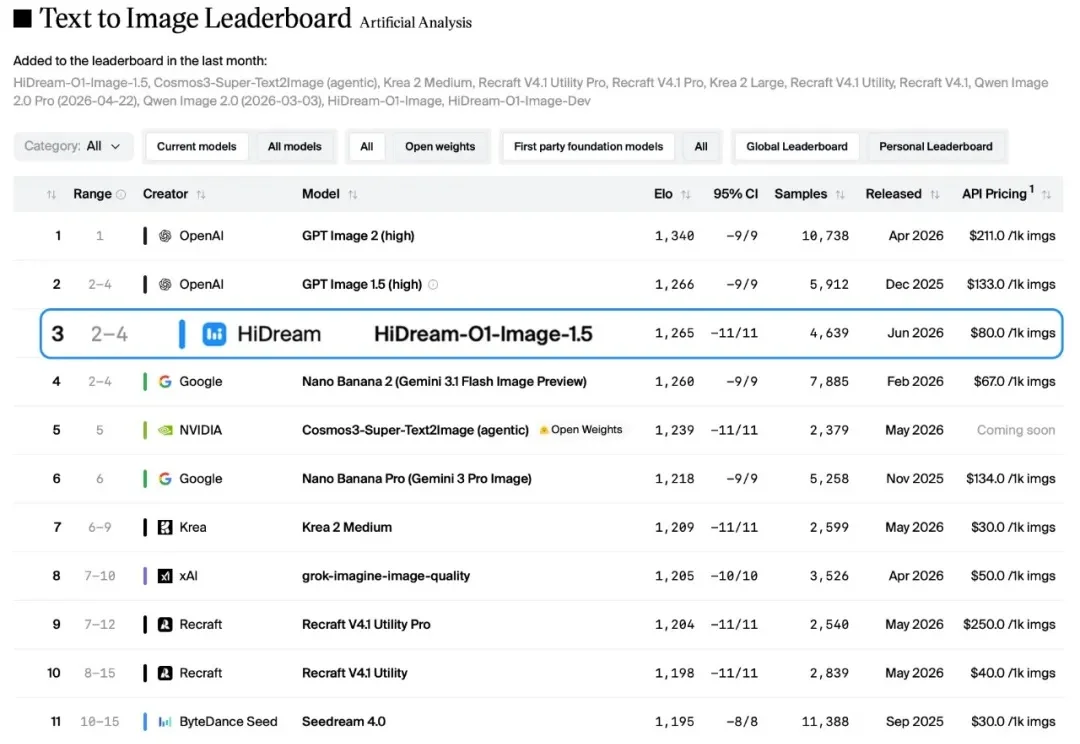
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?
HiDream-O1-Image-1.5 刷新国产图像生成模型纪录:砍掉 VAE,是图像模型的未来吗?文生图的"慢思考",到底有没有用?
来自主题: AI资讯
6591 点击 2026-06-11 10:41
 搜索
搜索
文生图的"慢思考",到底有没有用?
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
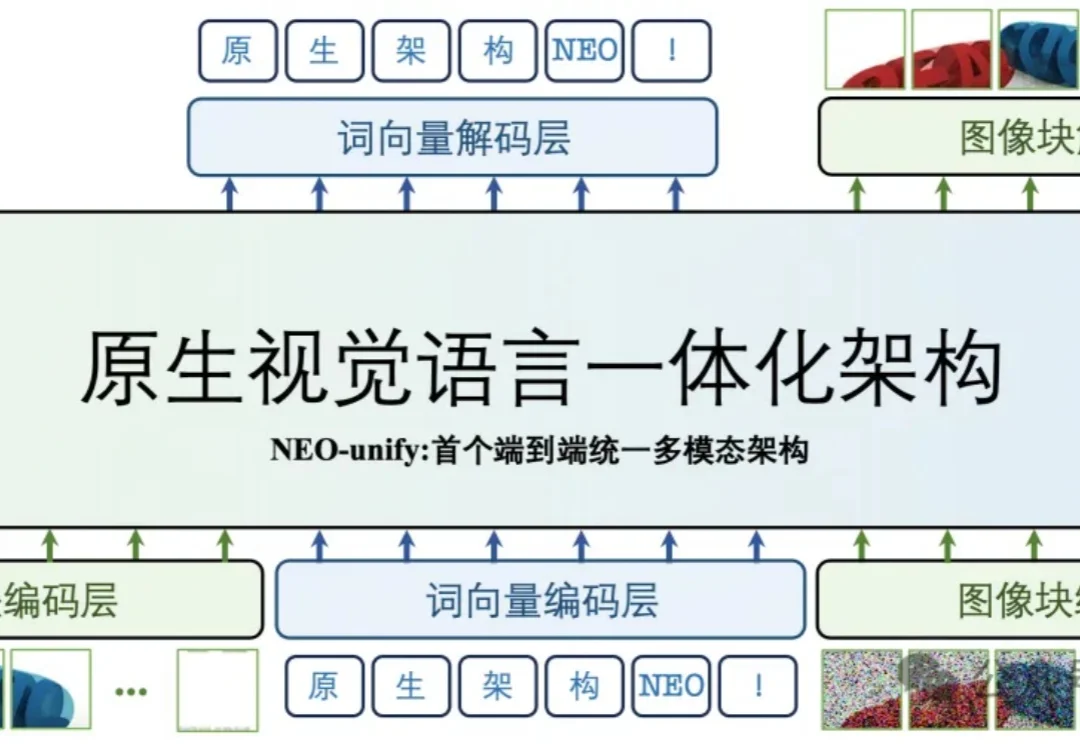
多模态大模型的研发范式,正在被彻底重构。
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视

让静态3D模型「动起来」一直是图形学界的难题:物理模拟太慢,生成模型又不讲「物理基本法」。近日,北京大学团队提出DragMesh,通过「语义-几何解耦」范式与双四元数VAE,成功将核心生成模块的算力消耗降低至SOTA模型的1/10,同时将运动轴预测误差降低了10倍。

MiniMax 海螺视频团队「首次开源」了 VTP(Visual Tokenizer Pre-training)项目。他们同步发布了一篇相当硬核的论文,它最有意思的地方在于 3 个点:「重建做得越好,生成反而可能越差」,传统 VAE 的直觉是错的
AI绘图圈的朋友们肯定都知道这个产品。FLUX。这次,发布了4款基础模型和1个VAE模型,其中2款是不开源的。分别是Pro和Flex,这两个最强大的模型,是闭源的。而其中2款模型是开源的,一个dev,目前已经开源了。
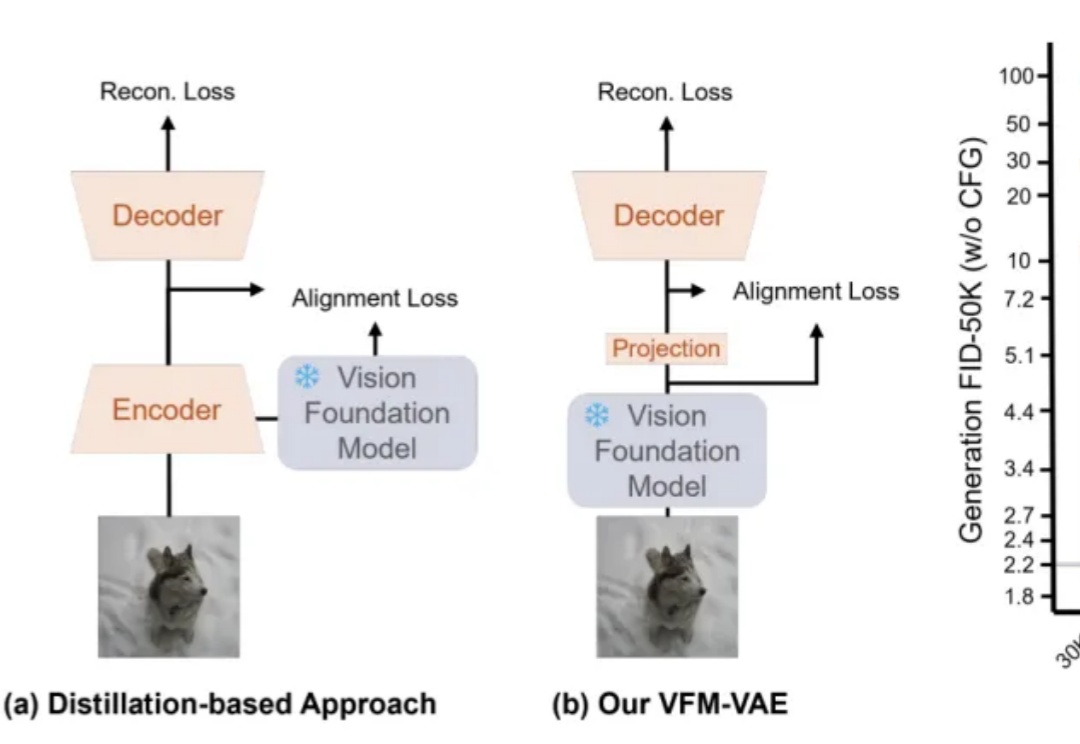
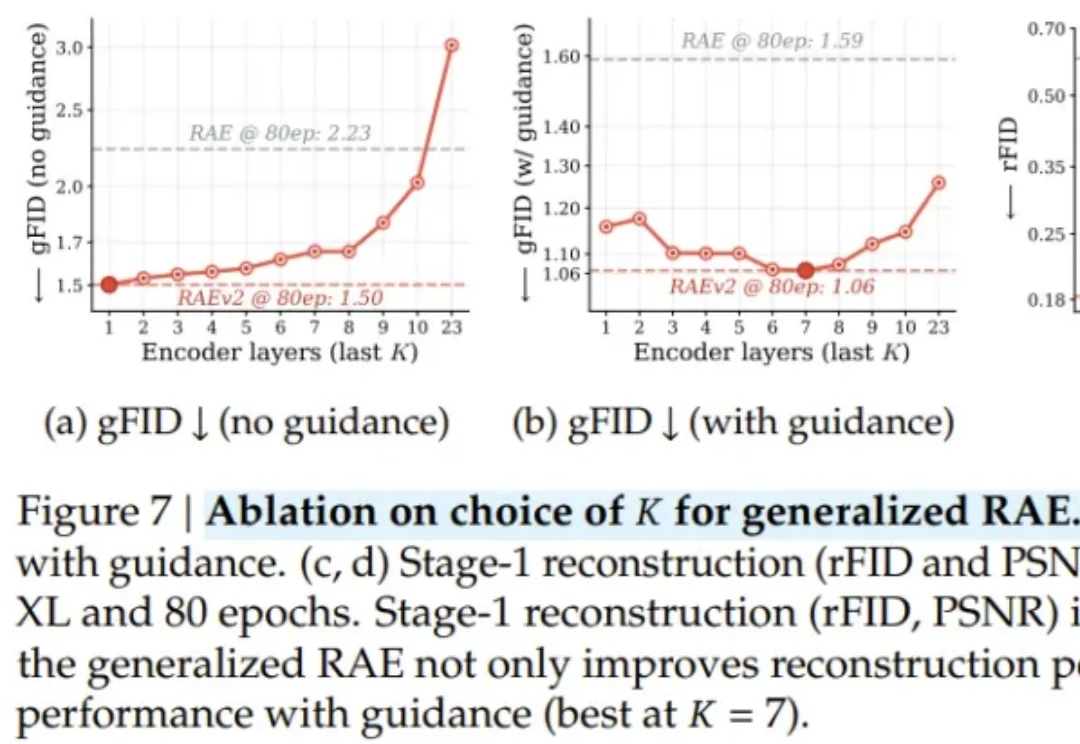
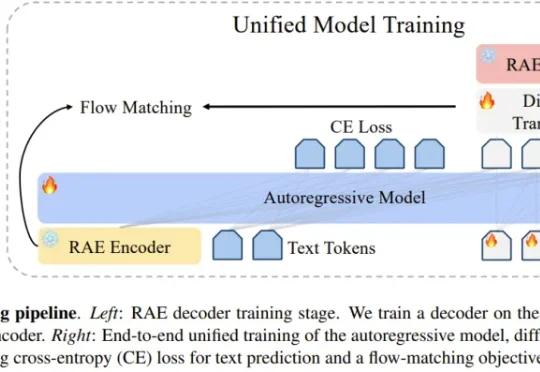
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
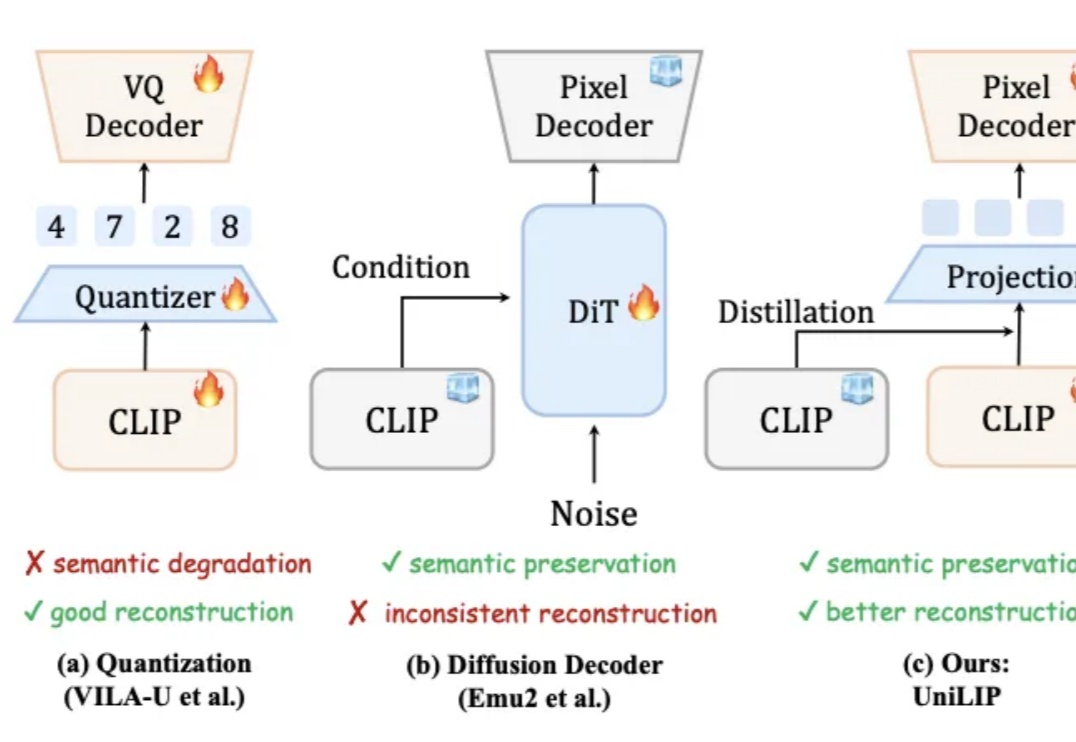
统一多模态模型要求视觉表征必须兼顾语义(理解)和细节(生成 / 编辑)。早期 VAE 因语义不足而理解受限。近期基于 CLIP 的统一编码器,面临理解与重建的权衡:直接量化 CLIP 特征会损害理解性能;而为冻结的 CLIP 训练解码器,又因特征细节缺失而无法精确重建。例如,RAE 使用冻结的 DINOv2 重建,PSNR 仅 19.23。

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题: