这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。 (原论文题目见文末,点击阅读原文可直接跳转至原文链接, Published on arxiv on 02 Nov 2025, by Nanyang Technological University)
代码地址:https://github.com/QwenQKing/Prompt-R1
第一阶段:识别核心概念
论文的motivation分析
这篇论文的出发点非常实际,直指当前在使用大语言模型(LLMs)时遇到的一个普遍痛点:普通人并不擅长写出能让 LLM 发挥全部潜力的“完美提示(Prompt)”。
想象一下,你手里有一台性能超强的超级计算机(就像 GPT-5 这样的大模型),但你给它的指令却是模糊不清、缺乏步骤的。那么,即使它能力再强,也无法给你满意的答案,尤其是在处理需要多步推理、逻辑严密的复杂问题时。
现有的解决方案各有弊端:
- 人工设计提示(如思维链 CoT):虽然有效,但需要专家知识,且对于不同任务需要重新设计,不够自动化和自适应。
- 微调(Fine-tuning)大模型:效果好,但成本极高,需要大量的计算资源和标注数据,而且对于那些只提供 API 接口的商业模型(比如 GPT-5)来说,这条路根本走不通。
- 已有的自动提示优化方法:往往专注于单轮交互,或者是一些复杂的、非端到端的优化方法,不够灵活和高效。
因此,作者的动机就是:能不能创造一个“智能助手”,让它代替人类,去和那个强大的大模型进行沟通? 这个智能助手自己就是一个小规模的语言模型,它更便宜、更容易训练。它的任务就是学习如何通过多轮对话,一步步地引导那个强大的大模型,最终解决复杂的难题。这就像是为超级计算机配了一个专业的、会自动学习和进步的操作员。
论文主要贡献点分析
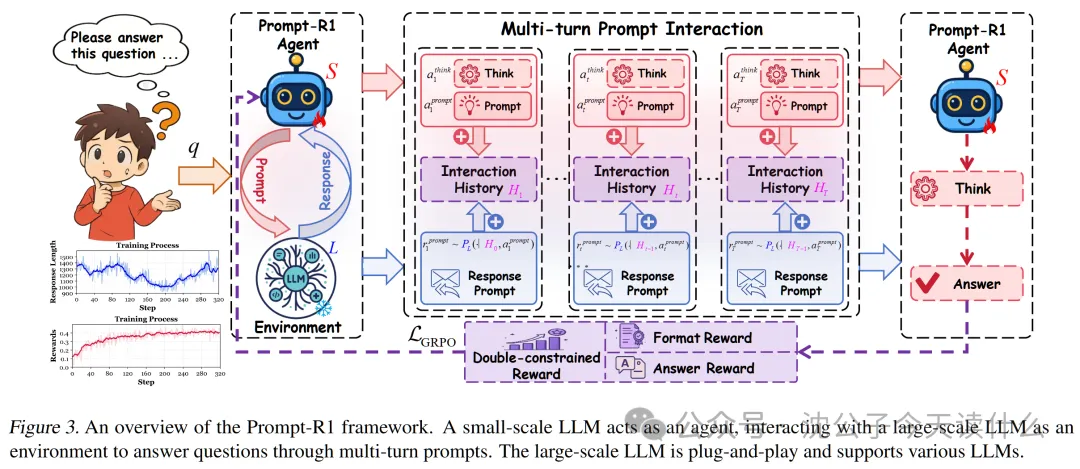
- 列出论文声称的主要创新点 — 包含四个方面:①提出了 Prompt-R1 框架——这是一个创新的协作式自动提示框架,定义了一种新的工作模式:让一个小规模 LLM 扮演"代理(Agent)"的角色,负责思考和生成提示;让一个大规模 LLM 扮演"环境(Environment)"的角色,负责执行复杂的推理和生成回应。②采用了端到端的强化学习(RL)——整个"小模型引导大模型"的过程,可以通过强化学习进行端到端的训练和优化,这意味着小模型能够从交互的最终结果(答案是否正确、过程是否规范)中学习,并不断迭代优化自己的"提问策略"。③设计了双重约束的奖励函数(Dual-constrained Reward)——为了让强化学习的"奖惩"机制更有效,作者精心设计了一个奖励函数,它不仅奖励最终答案的正确性,还奖励生成过程的规范性(比如格式要对,不能生成空内容等),确保了学习过程的稳定和高效。④实现了即插即用(Plug-and-play)的灵活性——经过训练的小模型 Agent,不仅可以和训练时使用的大模型协作,还可以无缝切换到其他不同的大模型上,并且同样能提升它们的表现,这极大地增强了该方法的通用性和实用价值。
- 找出支撑这些创新的关键技术或方法 — 包括三个核心技术:
- 协作式 Agent-Environment 架构 — 这是整个框架的基石。将两个 LLM 的角色进行功能划分,是实现自动协作的前提。
- 强化学习算法(GRPO) — 论文采用了 Group Relative Policy Optimization (GRPO) 算法。这是一种相对稳定高效的强化学习策略优化算法,适合处理语言生成这种高维、离散的动作空间。
- 自定义奖励函数设计 — 这是强化学习的灵魂。双重约束的设计,特别是将格式奖励和答案奖励结合的"门控机制",是确保 Agent 学到有效策略的关键。
- 性能显著提升 — 在多个公开数据集上,Prompt-R1 框架显著超越了包括直接使用大模型、思维链(CoT)以及其他自动提示优化方法在内的基线模型。
- 证明了框架的通用性与迁移能力 — 实验证明,用一个大模型(如 GPT-4o-mini)训练出的 Agent,可以成功地与其他多种大模型(如 Deepseek-V3, Llama-4 等)协作,并提升它们的性能。这有力地支撑了其"即插即用"的论断。
- 验证了低成本训练的可行性 — 实验还表明,即使使用一个免费的、本地部署的开源大模型作为训练"环境",训练出的 Agent 也能取得与使用昂贵 API 模型训练相媲美的效果。这大大降低了该技术的应用门槛。
理解难点识别
- 分析哪些概念/方法是理解论文的关键 — 包括三个关键概念:①Agent-Environment 范式在 LLM 交互中的应用——如何将经典的强化学习"代理与环境交互"模型,映射到两个 LLM 之间的纯文本对话上,是理解整个框架的第一步。②强化学习中的"轨迹(Trajectory)"与"策略(Policy)"——在文本生成任务中,什么是"状态",什么是"动作",什么是"策略"?这需要一个清晰的定义。③双重约束奖励函数(Double-constrained Reward)——这是论文技术细节的核心,也是最具挑战性的部分。理解它的设计思想、各个组成部分以及它们如何协同工作,是掌握本文精髓的关键。
- 找出这些概念中最具挑战性的部分 — 无疑是双重约束奖励函数以及它如何与 GRPO 优化目标相结合。具体来说,公式(12)、(14)、(15)定义的奖励机制,以及公式(17)定义的最终损失函数,是技术上最密集、最需要深入解释的部分。它决定了 Agent 学习的方向和效率。
- 确定需要重点解释的核心概念 — 核心概念是基于双重约束奖励的强化学习优化过程。
概念依赖关系
- 切入点:首先,需要建立一个直观的场景,来理解小模型 Agent 与大模型 Environment 的协作关系。这是整个故事的舞台。
- 核心机制:然后,引入强化学习作为这个 Agent 的“学习方法”。Agent 的目标就是学习一个最优的“提问策略”。
- 深入关键:最后,将焦点对准强化学习的核心引擎——双重约束奖励函数。这是整个学习过程的导航系统,告诉 Agent 什么样的行为是“好”的,什么样的行为是“坏”的。
第二阶段:深入解释核心概念
设计生活化比喻:菜鸟侦探与传奇法医
- **菜鸟侦探小 P (Prompt-R1 Agent, 小模型)**:他充满热情,逻辑清晰,但经验不足,缺乏直接破案所需的广博知识。他的任务是主导整个调查过程。
- **传奇法医老 G (Large-scale LLM, 大模型)**:他是一位知识渊博、能力超群的法医专家。你给他任何物证(Prompt),他都能给出一份详尽的分析报告(Response)。但他有个特点:非常“字面化”,你问什么,他就答什么,绝不多说一句废话。如果你问得不好,他的报告可能毫无价值。
- 警察局长(奖励系统 & 优化算法):他负责评估小 P 的工作,并在每次案件结束后对小 P 进行“绩效评估”,帮助他成长。
整个破案过程是这样的:小 P 接手一个案子(用户提出的复杂问题),他不能直接破案,但他可以不断地向法医老 G 提交物证,请求分析。比如,他先提交“案发现场的指纹”,老 G 给出分析报告。小 P 阅读报告后,结合案情思考,再提交“受害者的通讯记录”……通过这样一轮轮的互动,小 P 逐步拼凑出完整的证据链,最终在结案报告中指出真凶。
建立比喻与实际技术的对应关系
- 菜鸟侦探小 P 对应 **小规模 LLM (Agent, S)**:负责思考、规划、生成请求。
- 传奇法医老 G 对应 **大规模 LLM (Environment, L)**:拥有强大的知识和推理能力,负责响应请求。
- 案件卷宗 对应 **用户的初始问题 (q)**:整个任务的起点。
- 小 P 的思考笔记 对应 **Agent 的思考过程 (a_think)**:在生成下一个问题前的内部推理。
- 小 P 提交的“物证分析请求” 对应 **Agent 生成的 Prompt (a_prompt)**:这是与大模型的交互动作。
- 老 G 出具的“法医报告” 对应 **大模型的响应 (r_prompt)**:这是环境的反馈。
- 整个案件的调查档案 对应 **多轮交互历史 (H_t)**:记录了从开始到现在所有的“请求-报告”对。
- 小 P 的最终结案报告 对应 **Agent 生成的最终答案 (y)**。
- 警察局长的“绩效评估” 对应 **双重约束奖励函数 (R)**:这是整个学习过程的核心驱动力。
深入技术细节
“警察局长”的评估标准非常严格,分为两部分:“过程分” 和 “结果分”。
(1) 过程分 (Format Reward, R_fmt)
局长首先要看小 P 的调查过程是否专业、规范。不规范的流程会浪费警局资源。这对应论文中的“格式奖励”。
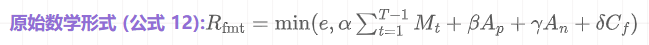

总结:过程分就是对侦探小 P 每一步工作的专业度打分,确保他不犯低级错误。
(2) 结果分 (Answer Reward, R_ans)
当然,过程再好,抓不到真凶也是白搭。所以“结果分”至关重要。
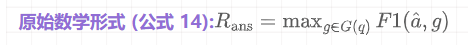

(3) 最终绩效:门控组合(Gated Composition)
局长如何结合“过程分”和“结果分”给出最终的总评价?他有一个非常严格的规定。

这种“门控”机制,迫使侦探小 P 优先学会“如何规范地工作”,在此基础上,再去追求“如何正确地破案”。这使得学习过程非常稳定和高效。
将技术细节与比喻相互映射
- GRPO 优化算法 (警察局长的"培训方法") — 警察局长拿到小 P 一系列案件的"最终绩效"后,会用 GRPO 这个方法来对他进行培训。
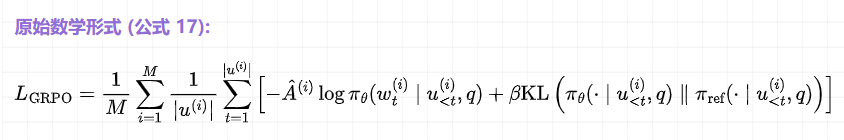

总结
- Prompt-R1 的核心,就是训练一个“菜鸟侦探”(小模型),让它学会如何通过一系列精妙的、有逻辑的“分析请求”(Prompts),来引导“传奇法医”(大模型)一步步揭示真相。
- 成功的关键,在于“警察局长”那套赏罚分明的“绩效评估体系”(双重约束奖励)。它通过一个巧妙的“门控”机制,强制侦探必须先学会规范地工作(过程分),然后才能因成功破案(结果分)而获得奖励。
- 最终的学习,是通过回顾一系列案件的好坏(GRPO算法),来不断强化侦探的优秀决策,修正其错误行为,让他最终成长为一名真正的“神探”。
第三阶段:详细说明流程步骤
推理流程 (解决新问题)



训练流程 (教会 Agent 如何解决问题)
训练流程的目标是优化 Agent (小模型 S) 的参数,让它在推理时能做出更好的决策。它包含了完整的推理流程,并在最后增加了一个学习和更新的步骤。



第四阶段:实验设计与验证分析
1. 主实验设计解读:核心论点的验证
- 核心主张:Prompt-R1 框架通过小模型与大模型的协作式强化学习,能够在多种复杂任务上显著超越现有方法。
- 数据集 — 作者选择了 8 个具有代表性的公开数据集进行训练和测试,涵盖了四大类任务:多跳推理 (Multi-hop Reasoning) 包括 2WikiMultihopQA 和 HotpotQA,这类任务要求模型整合来自多个文档片段的信息,极具挑战性;数学计算 (Mathematical Computation) 包括 GSM8K 和 DAPO Math,考验模型的逻辑推理和精确计算能力;标准问答 (Standard QA) 包括 MusiQue 和 PopQA,测试模型对事实知识的检索和理解;文本生成 (Text Generation) 包括 BookSum 和 WritingPrompts,评估模型的创造性和语言组织能力。合理性分析:这个选择非常合理,这些数据集都是各自领域的公认基准 (Benchmark),具有很高的权威性。同时,任务类型的多样性足以证明 Prompt-R1 的通用性,而不是只在某一类特定任务上有效。
- 评价指标 — 包括 EM (Exact Match) (精确匹配,最严格的指标,答案必须一字不差)、F1-score (衡量预测答案和标准答案之间的词语重叠度,更具鲁棒性) 和 SSim (Semantic Similarity) (用于文本生成任务,衡量语义上的相似度)。合理性分析:指标选择全面且专业,针对不同任务类型(如数学题要求精确用 EM、问答题内容宽泛用 F1、生成任务看质量用 SSim),使用了最合适的评价标准,保证了评估的公正性和准确性。
- 基线方法 (Baselines) — 包括基础模型 (GPT-4o-mini 作为 Agent 和 Qwen3-4B 作为大模型的原始表现)、简单优化 (SFT 监督微调 和 CoT 思维链提示)、高级自动提示优化 (APO) 方法 (OPRO, TextGrad, GEPA,这些是当前 SOTA 的竞争对手) 和同类 RL 方法 (GRPO 单独使用)。合理性分析:基线选择非常强大且全面,不仅包含了下限(基础模型)和经典的增强方法(SFT, CoT),更重要的是纳入了最直接的、最先进的竞争对手(APO方法)。这使得 Prompt-R1 的胜利更具说服力,证明了它不是"比最差的好",而是"比最好的还要好"。
- 结果与结论 — Table 2 是主实验的核心,数据显示在几乎所有任务和所有指标上,Ours (Prompt-R1) 都取得了最佳性能(加粗显示)。例如,在挑战最大的 2Wiki 多跳推理任务上,Prompt-R1 的 F1 分数达到了 54.41%,远高于基线 GPT-4o-mini 的 36.57% 和其他所有方法。结论:主实验强有力地证明了 Prompt-R1 的优越性和广泛适用性。通过协作式强化学习,它确实能够解锁大模型的更深层潜力,效果远超其他优化技术。
2. 消融实验分析:内部组件的贡献
- 目的:验证 Prompt-R1 的三大核心组件——**① LLM-as-Environment (与大模型交互),② Reinforcement Learning (强化学习),③ Prompt-R1 Agent (小模型代理)**——是否都是不可或缺的。
- 实验设计 (Table 4) — 作者设计了四个版本的模型进行对比:Prompt-R1 (Full) (完整版模型)、w/o Env. (移除大模型环境,即让小模型 Agent 单打独斗,不与大模型协作)、w/o R.L. (移除强化学习,可能退化为监督学习或一个固定的策略,失去了自适应学习能力) 和 w/o Agent (移除小模型代理,这其实就是基线,直接使用大模型)。"消融"掉某个部分,然后观察性能下降的幅度,下降得越多,说明这个部分越重要。
- 结果与结论 — 从 Table 4 可以清晰地看到,任何组件的移除都会导致性能的急剧下降。最惊人的下降发生在 w/o R.L. 上,例如在 HotpotQA 任务上,完整模型的 EM 为 **44.53%**,而移除强化学习后暴跌至 20.31%,这定量地证明了强化学习是整个框架的灵魂,是实现性能飞跃的关键。w/o Env. 的性能也远低于完整版,证明了小模型与大模型的协作是必要的,小模型本身不具备独立解决复杂问题的能力。结论:消融实验有力地证明了作者设计的每个模块都各司其职且至关重要,Prompt-R1 的成功是其整体架构协同作用的结果,而非单一技术的功劳。
3. 深度/创新性实验剖析:洞察方法的内在特性
实验一:模型的迁移与泛化能力 (RQ3, Figures 4 & 5)
- 实验目的:验证 Prompt-R1 的“**即插即用 (Plug-and-play)**”特性。一个训练好的 Agent 是否能与它从未见过的其他大模型良好协作?
- 实验设计:这个设计非常巧妙。作者将用 GPT-4o-mini 训练好的 Agent,分别“嫁接”到其他六个不同的大模型上(如 Deepseek-V3, Grok-4-Fast, LLaMA-4-Maverick 等)。然后对比这些大模型在“有 Agent 辅助”和“无 Agent 辅助”两种情况下的性能。
- 实验结论:
- Figure 4 的雷达图直观地展示了,对于所有六个 LLM,引入 Prompt-R1 Agent 后,其在各项任务上的性能范围(雷达图覆盖面积)都显著扩大了。
- Figure 5 的柱状图更清晰地量化了 OOD (Out-of-Distribution) 数据集上的平均性能提升。
- 深刻洞见:这个实验雄辩地证明了 Agent 学到的是一种通用的、可迁移的“沟通与引导策略”,而不是针对某个特定模型的“过拟合技巧”。这是 Prompt-R1 具有巨大实用价值的铁证。
实验二:训练成本与效益分析 (RQ5, Table 5 & Figure 6)
- 实验目的:探究训练环境的成本对最终效果的影响。是否必须使用昂贵的闭源 API 模型(如 GPT-4o-mini)作为“陪练”?还是说,使用免费的、本地部署的开源模型(GPT-OSS-20B)也能训练出优秀的 Agent?
- 实验设计:作者设立了两组对照实验,分别使用“高成本”和“零成本”的大模型作为训练环境,来训练两个不同的 Agent。然后全面比较这两个 Agent 的训练过程、最终性能以及它们在不同任务上的表现。
- 实验结论:
- Figure 6(a) 的训练曲线显示,高成本模型(蓝色)收敛更快但不稳定,而零成本模型(橙色)学习得更平稳。
- Table 5 的结果显示,使用零成本模型训练出的 Agent (Prompt-R1##),其性能与使用高成本模型训练出的 Agent (Prompt-R1**) 非常接近,甚至在某些指标上互有胜负。
- 深刻洞见:这个实验给出了一个令人振奋的结论:Prompt-R1 框架是经济可行的。研究者和开发者可以在不产生高昂 API 费用的情况下,利用本地开源模型复现和应用这项技术,这极大地降低了它的使用门槛,促进了技术民主化。
案例研究 (Case Study, Figure 9)
- 实验目的:通过一个具体的失败与成功案例,直观地展示 Prompt-R1 的推理过程到底比其他方法好在哪里。
- 实验设计:选择了一个所有基线方法都回答错误的“导演国籍”问题。详细展示了基线方法(包括 CoT)的错误推理链条,并与 Prompt-R1 的正确、结构化的多轮推理过程进行对比。
- 实验结论:
- 基线方法在事实检索上出现了“漂移”,错误地关联了不相关的导演信息。
- Prompt-R1 则展现了结构化的问题分解能力:先分别确认两部电影的导演,再分别查询他们的国籍,最后进行比较。这个过程逻辑清晰,步步为营,有效地避免了事实错误。
- 深刻洞见:案例研究让我们看到了“黑箱”内部。它生动地证明了 Prompt-R1 的多轮交互机制不仅仅是简单的信息叠加,而是一种更鲁棒、更有条理的结构化推理过程。
文章来自于“沈公子今天读什么”,作者“Tensorlong 看天下”。



