# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
作者彭若天是西湖大学和浙江大学联培博士生,任毅是不列颠哥伦比亚大学博士,郁昼亮是香港中文大学博士生,刘威杨是香港中文大学计算机系助理教授,温研东是西湖大学人工智能系助理教授
随着 Deepseek-R1,Kimi1.5 等模型展示了强化学习在提升大型语言模型复杂推理能力上的巨大潜力,使用可验证强化学习(RLVR)在数学、逻辑与编程等领域进行训练提升模型性能受到了广泛关注。
然而,尽管现有 RLVR 方法在提升模型的 pass@1 性能(单次尝试正确的概率)方面取得了显著成果,但其在 pass@K(K 次尝试中至少一次正确的概率,K>1)上的性能相比基础模型却下降了。
这一现象表明,虽然模型在「利用」(Exploitation)单一正确路径的能力有所增强,但牺牲了对多样化正确解的「探索」(Exploration)能力。
针对这一问题,研究团队从「模型预测下一个词的概率分布」这一新视角出发,深入研究了「探索」能力下降的内在机制。大量实验发现,经过现有 RLVR 算法训练后的模型,多数存在概率集中于单一推理路径的问题。
受该现象启发,研究团队提出一种简洁且高效的算法 ——SimKO (Simple Pass@K Optimization),显著优化了 pass@K(K=1 及 K>1)性能。
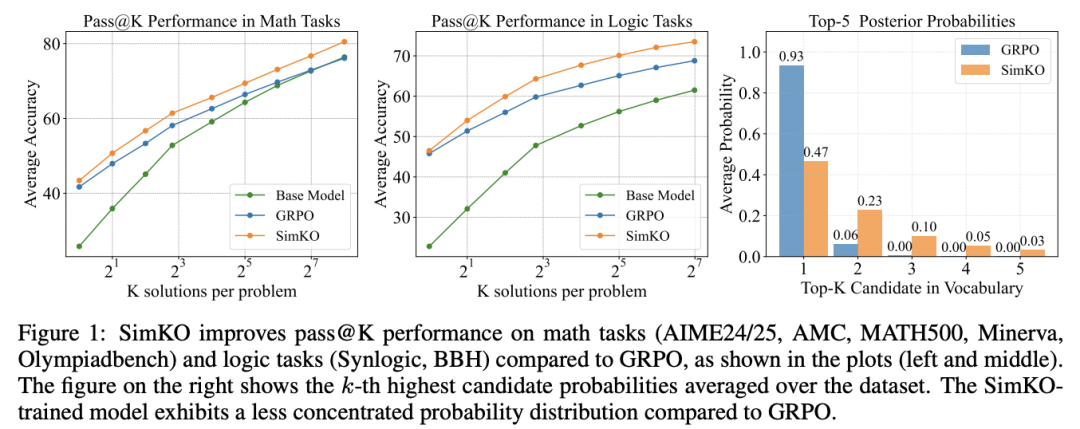
图 1
当前主流的大语言模型强化学习算法(如 GRPO、DAPO 等)采用 RLVR 范式,其训练方法可以直观理解为:模型对每个问题生成多个答案,对正确答案给予奖励,对错误答案施加惩罚。在理想的探索状态下,模型能够在多个潜在正确推理路径之间分配相对均匀的概率质量,不应将概率过度集中于某一条正确路径上,如图 2 (a) 和 (b) 所示。
同时,团队认为当前的用熵(Entropy)作为指标衡量多样性存在局限:熵无法具体反映概率分布的形态。如图 2(c)所示,两个具有相同熵值的分布,一个可能包含多个峰值,而另一个则可能高度集中于一个峰值。
因此,熵无法精确描述模型在推理过程中对不同推理路径的真实探索程度。
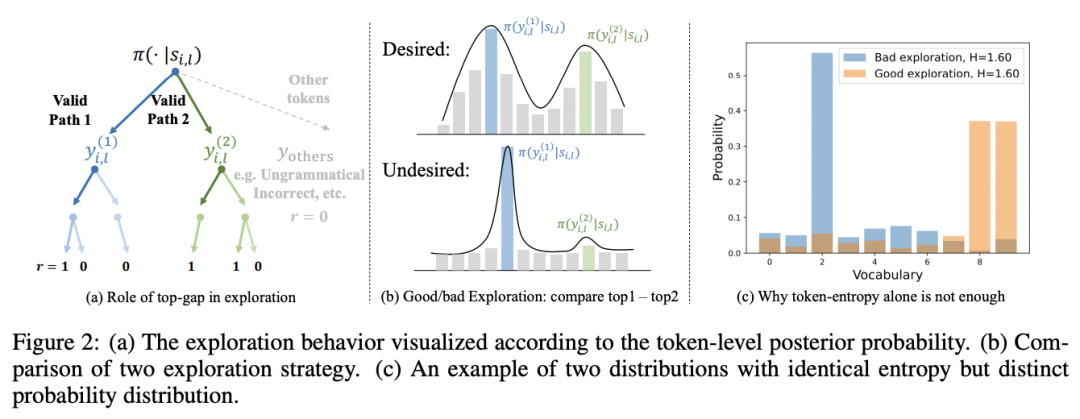
图 2
因此,团队引入了一种新的分析指标,用于更加精细地观察训练过程中的学习动态:该指标通过测量模型在生成过程中,反映下一 token 后验概率分布的不同排名候选词(rank-k candidate)的平均对数概率(average log-probability),从而实现对概率分布演化动态的直接观测。
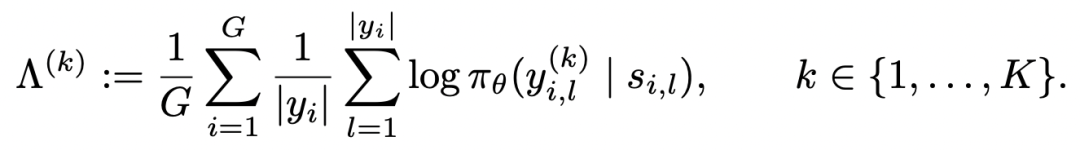
通过这一新指标,作者发现 RLVR 训练机制存在一个系统性偏差(如图 3 所示):
它会持续强化 rank-1 候选词的概率,同时显著抑制其他较低排名(rank-k, k>1)的候选路径,即使那些路径同样是正确的。
这种机制导致了模型输出分布的「过度集中」。模型的概率质量过度汇聚于单一的推理路径,导致其丧失了生成多样化正确答案的能力。
更重要的是,进一步实验分析明确揭示了概率过度集中问题与 pass@K 性能的下降之间存在强相关性:当模型概率分布越集中于 rank-1 答案,而 rank-2 和 rank-3 的概率越低的时候,其 pass@K 指标也随之降低。

图 3
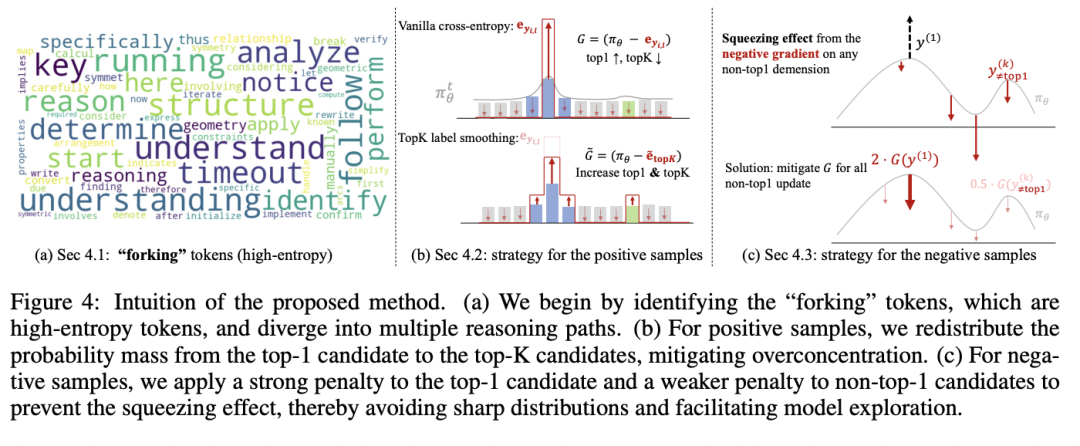
图 4
为解决上述的概率过度集中问题,研究团队提出了 SimKO (Simple Pass@K Optimization)。其核心机制在于对探索 token 施加非对称的更新策略(如图 4 所示):即在正确的推理路径上实现概率平滑,而在错误的推理路径上施加精准惩罚。
(A) 关键节点的识别
SimKO 并非对所有 token 进行无差别调节。它首先识别推理路径中具有高熵的 token,这些 token 代表了模型面临多个高概率选项、可能产生不同推理方向的关键节点。因此 SimKO 更新策略只应用于这些关键节点。
(B) 正确路径:实施 top-K Label Smoothing
(C) 错误路径:对 rank-1 token 精准惩罚
团队在多个数学推理基准(MATH500、AIME 2024/25、Minerva Math、OlympiadBench、AMC23)上对 Llama 和 Qwen 模型进行了系统性评估。如表 1 所示,SimKO 策略在显著提升 pass@K 性能的同时,成功保持(或略微提升)了 pass@1 准确率,证明其有效平衡了「探索」与「利用」。
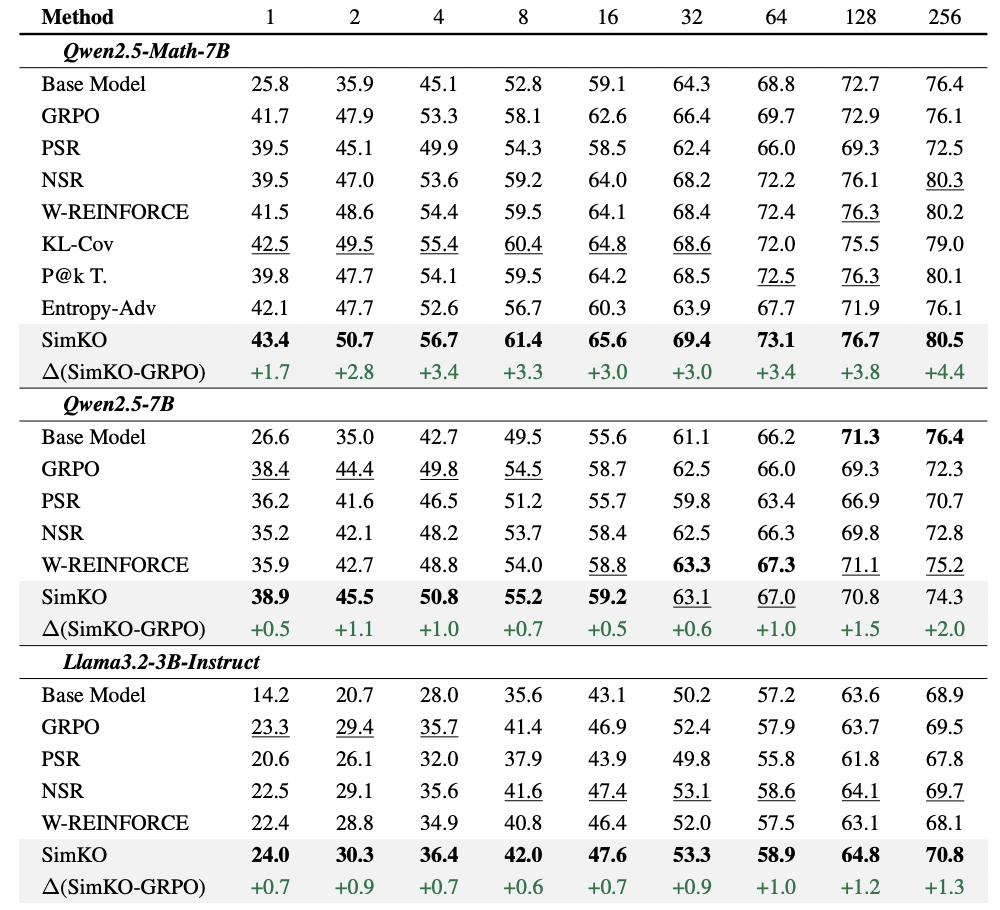
表 1
为了验证 SimKO 是否有效缓解了概率分布过度集中问题,研究团队使用上述新提出的分析指标,追踪了模型使用不同 RLVR 算法训练过程中的学习动态(如图 5 所示):
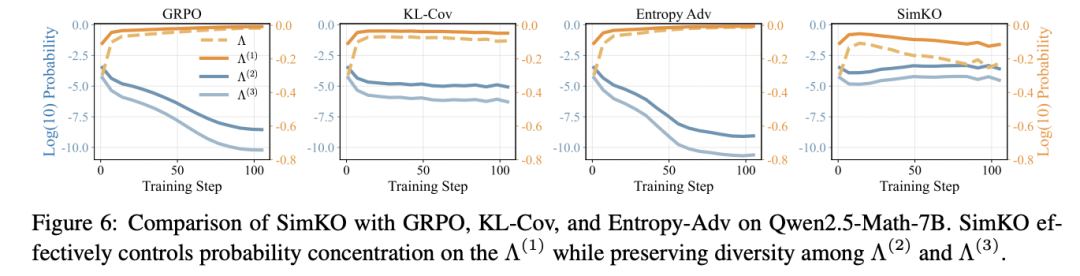
图 5
SimKO 不仅在数学推理任务上表现优异,在逻辑推理任务中同样具有出卓越的泛化效果(见表 2):
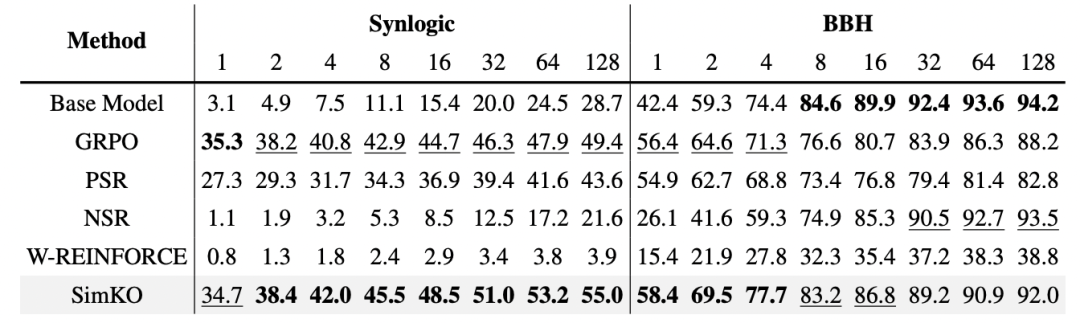
表 2
更多细节详见论文原文。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


