# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。
可以说,业界「苦」LLM 效率久矣,为了解决这一瓶颈,研究人员进行了多种尝试。
其实从根本上分析,大型语言模型(LLM)的效率是受限于其逐个词元生成的顺序过程。那如果 LLM 预测的不再是「下一个词元」,而是「若干个词元」的话,是不是会带来不一样的效果?
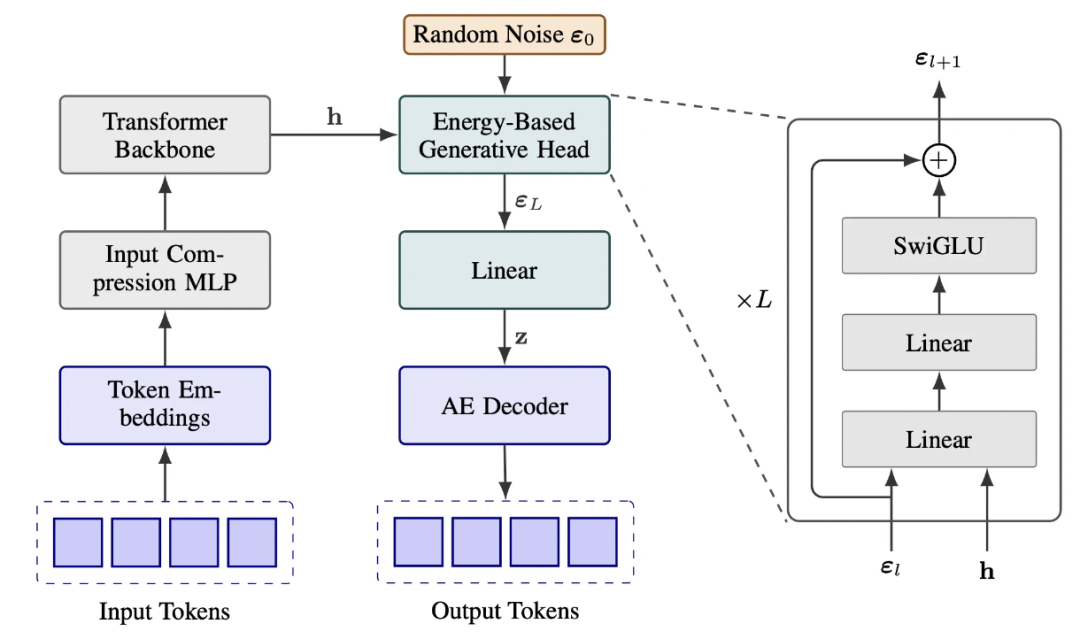
为此,腾讯微信 AI 联合清华大学在新发布论文中提出了一种新方法 —— 连续自回归语言模型(CALM),模型不再预测下一个词元,而是预测下一个连续向量。
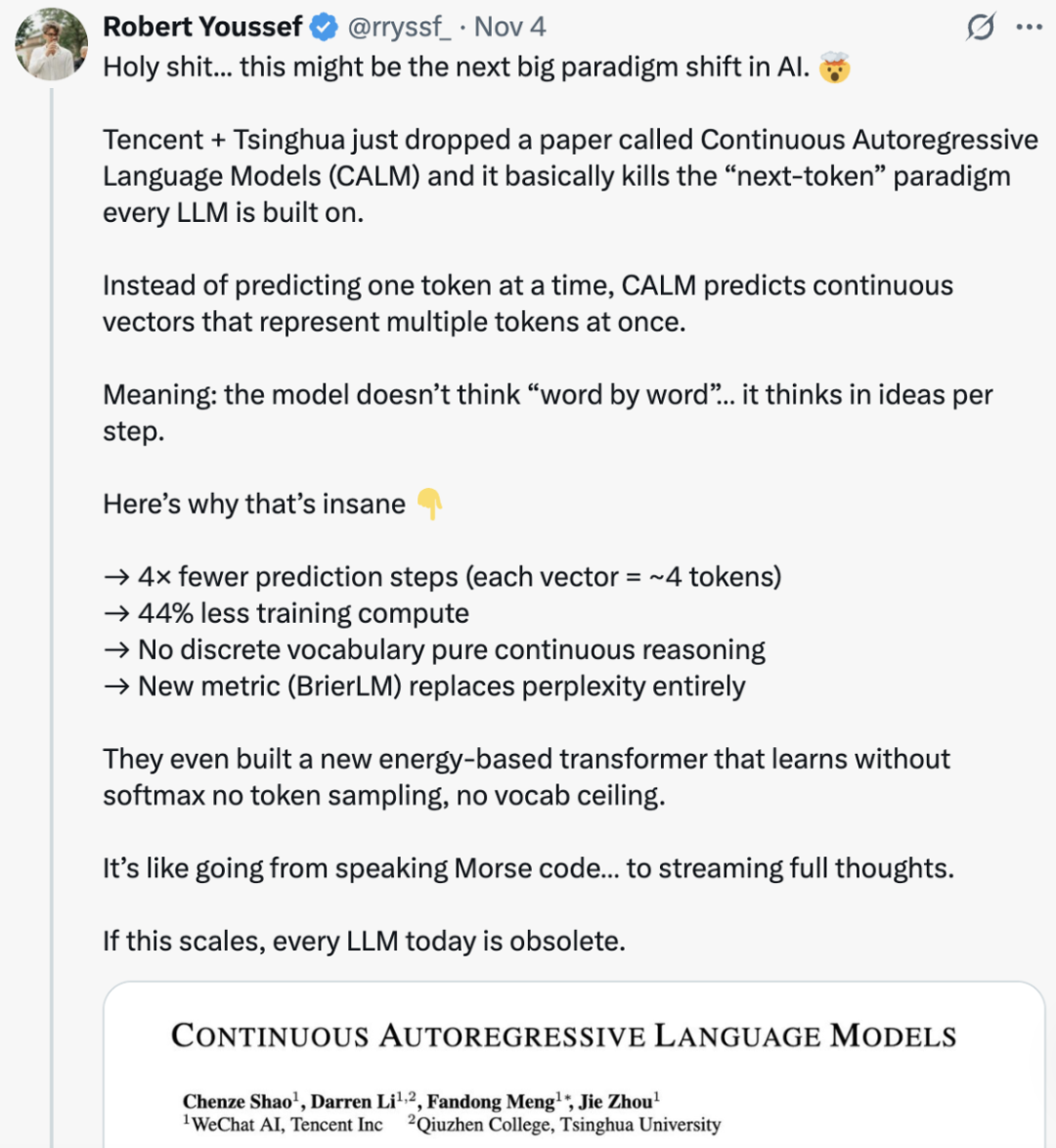
具体来看,CALM 使用高保真自编码器将 K 个词元压缩成一个连续向量,并能以超过 99.9% 的准确率从中重构原始词元,将语言建模为一系列连续向量,而非离散词元,从而将生成步骤的数量减少了 K 倍。
从效果上来看,这种方法显著改善性能与计算成本之间的权衡,在更低的计算成本下,性能可以与强大的离散基线模型相媲美。更重要的是,这是一种新的范式,为构建超高效语言模型提供了一种强大且可扩展的途径。

而论文一经发布,就引起了业界热议。
有网友认为,「这可能是人工智能领域的下一个重大范式转变」「如果这种模型能够大规模应用,那么现有的所有语言模型都将过时。」
离散词元:LLM 的效率瓶颈
大语言模型(LLMs)的成功与其高昂的计算成本相伴相生。作者认为,其效率问题的根源,在于当前所有模型都遵循的一个基础范式:在离散的词元(token)序列上进行自回归预测。问题的关键并非自回归机制本身,而在于离散词元的内在局限性。这一局限性体现在两个层面:
这揭示了一个根本性的矛盾:模型强大的表征能力,与预测任务的过细粒度之间,形成了「强模型、弱任务」的不匹配。我们拥有了参数规模巨大的模型,其能力却被束缚在一个低效、冗余的生成框架之中。
CALM:从离散词元到连续向量
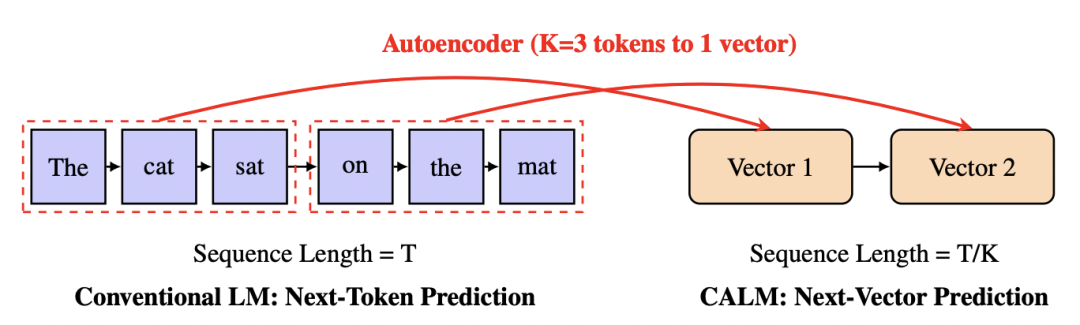
CALM 的核心思想是将语言建模的基础任务从预测离散的词元,转向预测连续的向量。这一范式转移的可行性基于一个高保真度的自编码器(Autoencoder)。它能将一个由 K 个词元组成的文本块压缩为一个稠密的连续向量,并能以超过 99.9% 的准确率从该向量中重建原始词元。
因此,语言模型只需预测代表下一个文本块的连续向量,即可通过自编码器还原回 K 个词元,从而将自回归生成的总步数减少为原来的 1/K。
然而,从离散到连续的转变,也让一些传统方法失效,带来了一系列技术挑战:
围绕这些挑战,作者建立了一套完整的无似然技术体系,使 CALM 这一新范式得以实现。
自编码器
实现 CALM 框架的基础,是构建一个高保真度的自编码器,用以建立离散词元与连续向量之间的双向映射。它由两部分组成:
这一过程的可行性在于,理论上一个浮点数向量的信息容量远超离散词元。在实践中,作者尝试将 K=4 个词元压缩为向量,仅需 10 个维度便可实现超过 99.9% 的重建准确率。
考虑到,在 CALM 的实际生成流程中,解码器所接收的向量并非来自编码器的「真值」,而是由语言模型预测出的结果。任何生成模型的预测都必然存在误差。如果自编码器只考虑重建,它会学到一个极其「脆弱」的映射,导致微小的预测误差被灾难性地放大,解码出完全无关的文本。
因此,向量表示必须具备鲁棒性(robustness),能够容忍来自预测结果的合理误差。
为实现这一目标,作者的核心策略是将确定性段自编码器升级为变分式的 VAE,使其学习将词元块映射为一个高斯分布,从而平滑向量空间。同时,作者在向量空间上引入 Dropout,迫使自编码器学习一种冗余的、抗干扰的向量表示。
综合这些技术,作者最终构建的自编码器能将 K=4 的词元块映射到一个 128 维的向量中。它能承受标准差约 σ≈0.3 的高斯噪声,同时依然保持超过 99.9% 的重建准确率。
模型训练
通过自编码器,原始的离散词元序列被转换为一个更紧凑的连续向量序列。因此,语言建模的目标也从预测下一个词元,演变为预测这个新序列中的下一个向量:
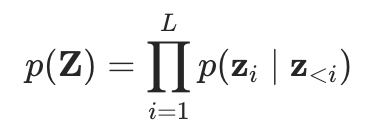
从离散到连续的转变,带来了一个生成建模上的挑战。标准语言模型依赖 softmax 层计算有限词表上的概率,但这在无限的连续空间中无法实现。

效率是此处的关键。如果取 Diffusion、flow matching 这类模型作为生成头,将需要进行多步迭代生成来预测向量,会抵消 CALM 在减少生成步数上的优势。
因此,生成头最好能具备高质量、单步生成的能力。为此,作者采用了一个基于能量分数(Energy Score)的训练目标。能量分数不依赖于概率密度,而是通过样本间的距离来评估生成分布的质量。对于模型预测的分布 P 和观测到的真值 y,其能量分数为:
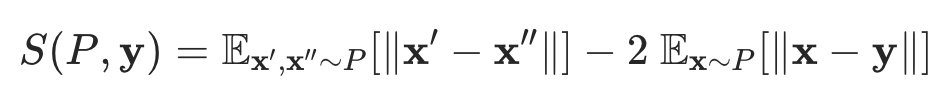
该指标巧妙地平衡了两个目标:第一项驱动多样性,鼓励模型生成不同的样本,防止模式坍塌;第二项驱动准确性,使生成结果逼近真实数据。
从统计学角度,能量分数是一种严格准确的评分规则(strictly proper scoring rule),理论上保证了最大化该分数等同于让模型学习真实的数据分布。在实践中,作者通过蒙特卡洛采样来估计能量分数,并将其作为损失函数来训练模型。
在模型结构上,为了使生成头能够产出多样的样本,其预测同时取决于两个输入:来自 Transformer 的确定性隐藏状态(提供上下文),以及一个额外的随机噪声向量(提供随机性)。通过在生成时采样不同的噪声,模型便能从同一个上下文中生成符合条件分布的、多样的输出向量。

性能评估
由于 CALM 框架无法计算显式概率,传统的困惑度(Perplexity)指标不再适用。因此,我们还需要一个无似然(likelihood-free)的评估方法。
作者引入了经典的 Brier Score 作为解决方案,这一指标最早由气象学家 Glenn W. Brier 在 1950 年提出,用来评估天气预报的准确性,目前已成为评估概率预测校准度(calibration)的标准工具之一。其定义为:
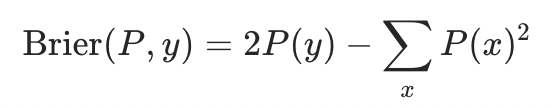
与困惑度类似,Brier 分数的设计使其仅在模型准确拟合数据分布时才能达到最优,这一点可以从其期望值的分解中看出:
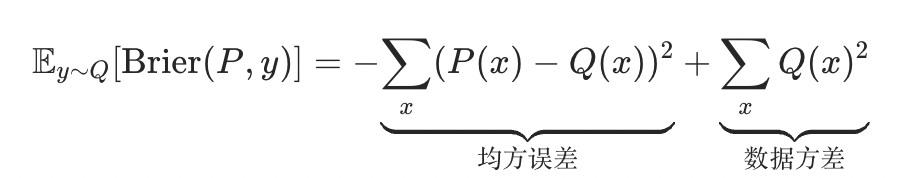
尽管 Brier 分数的仍由概率定义,但作者指出,它可以通过蒙特卡洛方法进行无偏估计,且仅需从模型中采样两个样本:
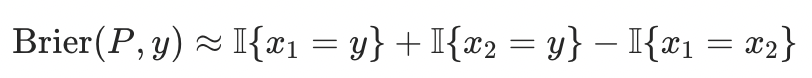

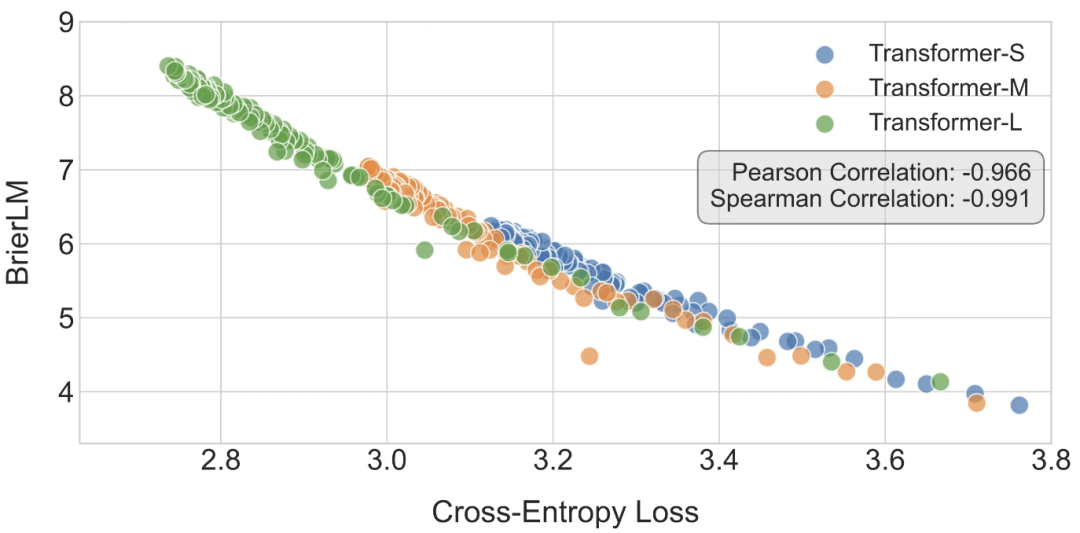
为了构建一个全面的评估指标,作者将 Brier 分数从单个词元扩展到 n-gram,并最终定义了 BrierLM,即 n=1 至 4 的 Brier-n 分数的几何平均值。BrierLM 是一个通用的评估指标,同样适用于传统语言模型。
通过在标准 Transformer 模型上进行验证,作者发现 BrierLM 与交叉熵损失几乎线性相关(Pearson 相关系数为 - 0.966),表明 BrierLM 可以作为困惑度在无似然场景下的有效替代。
可控生成
最后一个挑战是实现给定温度下的可控生成。传统方法通过调整 logits 来调整输出的概率分布,但对于像 CALM 这样只给出采样器而不提供 logits 的无似然模型,此路不通。
作者通过拒绝采样(rejection sampling)解决了这一难题。以一个简单的例子来说明:当温度 T=1/n 时,目标是使采样概率正比于
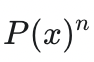
,这恰好等同于从模型中连续独立地采样 n 次,且这 n 次结果均为 x 的概率。因此,算法只需从模型中采样 n 次,当且仅当这 n 次采样结果完全相同时才接受该结果,否则便拒绝并重试。
对于更一般的温度 T,作者借鉴伯努利工厂(Bernoulli Factory)理论,将此思想推广为一个通用的拒绝采样算法。
然而,纯粹的拒绝采样算法可能因极高的拒绝率而变得低效。为此,作者进一步提出了一种高效的批处理近似(batch approximation)算法。该算法一次性从模型中采样大量的样本,然后以组合的方式在批内寻找符合条件的重复样本。这种方法极大地提升了样本的利用率。作者证明了该近似算法是渐进无偏的,即随着批处理大小的增加,其输出的样本分布会收敛于精确的目标分布。
实验效果
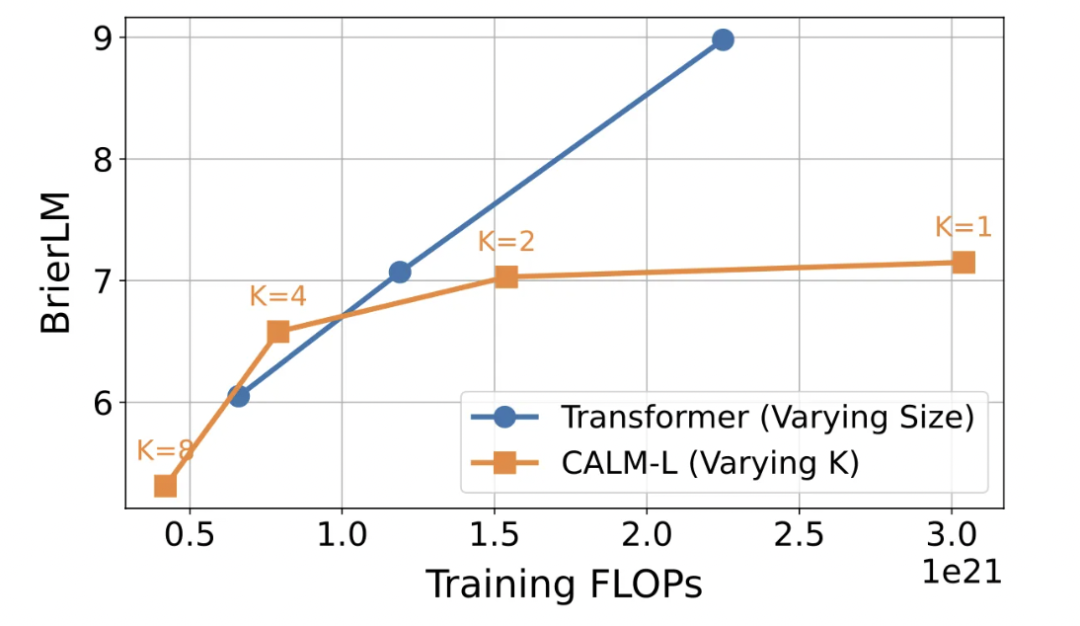
实验结果显示,CALM 能够建立一个更优的性能 - 计算前沿:例如,一个 371M 参数的 CALM-M 模型,其性能与 281M 的 Transformer 基线相当,但所需的训练 FLOPs 减少了 44%,推理 FLOPs 减少了 34%。这证明 CALM 通过牺牲少量同规模下的性能,换取了显著的计算效率提升,从而能在有限的计算预算下达到更高的性能水平。
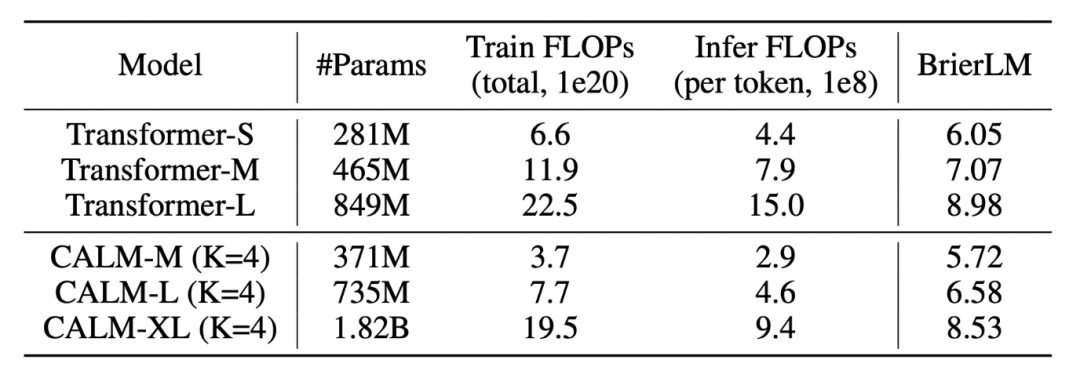
实验进一步验证了语义带宽 K 作为一个全新 scale 维度的有效性。作者探究了不同 K 值对模型性能 - 计算权衡的影响。结果显示,随着 K 从 1 增加到 4,模型的计算成本几乎成比例下降,而性能仅有轻微的回落。
这证明了通过提升单步生成的语义密度,是优化语言模型效率的一条高效路径。值得注意的是,当 K=1 时,CALM 的性能落后于其离散基线,这表明 CALM 的架构设计仍有未来优化的空间。
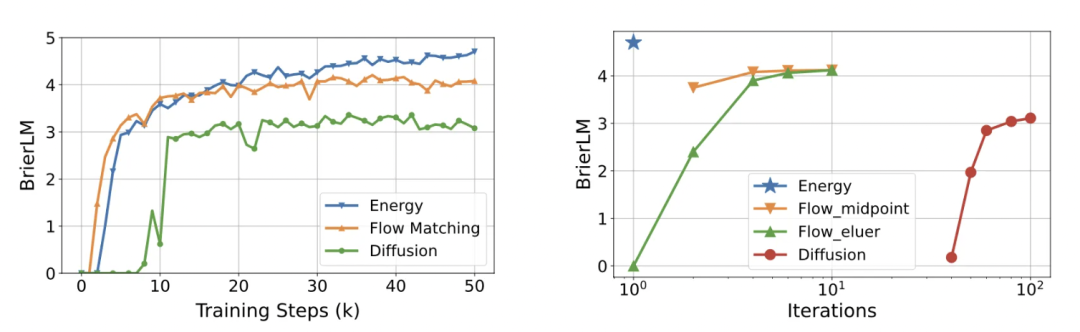
为了验证生成头的设计选择,作者对比了三种连续生成方案:本文使用的能量分数、扩散模型(Diffusion)与流匹配模型(Flow Matching)。实验表明:
结语
作者也指出了该框架未来的多个关键研究方向:首先,作为框架基石的自编码器可以被设计得更懂「语义」,而不仅是关注重建;核心生成模型也可以探索更强大的端到端架构与训练目标;在采样层面,需要研究更轻量高效的算法以降低推理开销。
更宏观地,一个重要的方向是建立包含语义带宽 K 的全新缩放定律。
最后,从离散到连续的范式转移,也要求学术界重新改造现有的算法生态,例如如何将强化学习、知识蒸馏等技术适配到这个无似然的框架中。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
