# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLM在持续学习方面有了新突破。
近日,谷歌推出了一种全新的用于持续学习的机器学习范式 —— 嵌套学习,模型不再采用静态的训练周期,而是以不同的更新速度在嵌套层中进行学习,即将模型视为一系列嵌套问题的堆叠,使其能够不断学习新技能,同时又不会遗忘旧技能。

而这或将标志着人工智能朝着「真正像大脑一样进化的方向」迈出了一大步。
这种方法一经发布,便引起网友的热议,不少网友表示,「这很令人兴奋,是迈向真正自适应、自我改进智能的重要一步。」
在谷歌看来,过去十年,得益于强大的神经网络结构和高效的训练算法,机器学习(ML)领域取得了令人惊叹的进展,可尽管大语言模型(LLMs)取得了巨大成功,一些根本性问题仍然存在,尤其是「持续学习(Continual Learning)」—— 即模型能否在不遗忘旧知识的前提下,不断学习新知识与技能。
在人类学习和自我改进方面,人脑是最完美的范例,它依靠神经可塑性(neuroplasticity)不断调整结构,以适应新的经验、记忆与学习。缺乏这种能力的人,就会像患有前向性遗忘症(anterograde amnesia)一样,只能理解眼前的信息。
而当前的 LLM 也面临着类似的限制,「知识」仅限于输入窗口的上下文,或是预训练阶段学到的静态信息。
为了弥补这些缺点,一个直觉式的做法是不断用新数据更新模型参数,但这往往导致所谓的「灾难性遗忘」(Catastrophic Forgetting,CF)—— 模型学了新任务,却失去了旧任务的能力。过去的研究尝试通过改进网络结构或优化算法来缓解这一问题。
然而,长期以来,大家总是把「模型结构」与「优化算法」当作两件事来看待,这种割裂的视角阻碍了统一高效学习系统的建立。
谷歌发表于 NeurIPS 2025 的论文《Nested Learning:深度学习架构的幻象》 中,提出了一个新的学习框架 —— 嵌套学习(Nested Learning),用以弥合架构与优化之间的鸿沟。其核心思想是:一个机器学习模型并非单一的学习过程,而是由多个相互关联、层次分明的优化子问题组成。
谷歌认为模型架构与优化算法本质上是同一类事物;它们只是不同层级的「优化层」(optimization levels),各自拥有独立的信息流与更新频率。
通过识别这种内在结构,嵌套学习为 AI 设计揭示了一个此前被忽视的维度,让我们能在不同时间尺度上构建更具「深度」的学习组件,从而解决灾难性遗忘等问题。
基于嵌套学习原理,谷歌设计了一个自我修改型架构 ——Hope,实验表明:Hope 在语言建模任务中表现优异,并且在长上下文记忆管理方面超越了当前最先进的模型。

嵌套学习揭示出,复杂的机器学习模型其实是一组相互嵌套或并行运行的优化问题,每个子问题都有自己的上下文流(context flow),也就是其试图从中学习的特定信息集。
也就是说,传统深度学习方法其实是在「压缩」这些内部信息流,而嵌套学习为我们提供了新的设计维度,从而可以构建具有更深计算深度的学习组件。
以联想记忆(Associative Memory)为例,联想记忆是指根据一个事物联想到另一个事物的能力,像是大家看到一张脸就想起一个名字。基于此,谷歌发现:训练过程本身,尤其是反向传播(backpropagation)过程,可以被建模为一种联想记忆机制,该模型学习将每个数据点映射到其局部误差(local error)上,以衡量该数据点的「意外程度」。
类似地,就像 Miras 之类研究所指出的那样,Transformer 的注意力机制也可以形式化为联想记忆模块,用于学习序列中 token 之间的映射关系。

在人脑中,统一的结构与可重复使用的模块,以及多时间尺度更新(multi-time–scale update),是人类持续学习的关键。而嵌套学习使得模型的每个组件都能以不同的频率进行更新,这表明,常见架构(如 Transformer、记忆模块)其实都是具有不同更新频率的线性层。
通过定义更新频率(update frequency rate),即每个组件的权重被调整的频次,谷歌可以将这些优化问题组织成有序的「层级」,这便构成了嵌套学习范式的核心。
嵌套学习视角提供了改进现有算法和架构的原则性方法:
嵌套学习将优化器(如动量优化器)视为联想记忆模块,从而可以将联想记忆的原理应用于它们,观察到,许多标准优化器依赖简单的点积相似度(dot-product similarity),而这并未考虑不同数据样本之间的复杂关系。
通过将优化目标改为更标准的损失指标,如 L2 回归损失(L2 regression loss),可以推导出新的动量公式,使优化器对噪声数据更具鲁棒性。
在传统 Transformer 中:序列模型充当短期记忆,保存即时上下文;前馈神经网络则充当长期记忆,存储预训练知识。嵌套学习范式将这一概念扩展到一个称之为「连续体记忆系统」(CMS)的结构中,其中记忆被视为一系列模块,每个模块以不同的特定频率更新。
这为持续学习创建了一个更加丰富、高效的记忆系统。
作为概念验证,谷歌基于嵌套学习原理设计了 Hope 架构,它是 Titans 架构的一个变体。
Titans 架构是基于「惊讶度」优先级的长期记忆系统,但它仅有两层参数更新机制,属于一阶上下文学习。
Hope 则是一个自我修改的循环架构(self-modifying recurrent architecture),能够执行无限层次的上下文学习,并通过 CMS 模块扩展上下文窗口。它能够通过自我引用过程优化自身记忆,形成具有无限循环学习层次的结构。
谷歌评估了嵌套学习框架下:新型深度优化器的有效性,以及 Hope 在语言建模、长上下文推理、持续学习与知识整合任务上的表现。
结果显示:
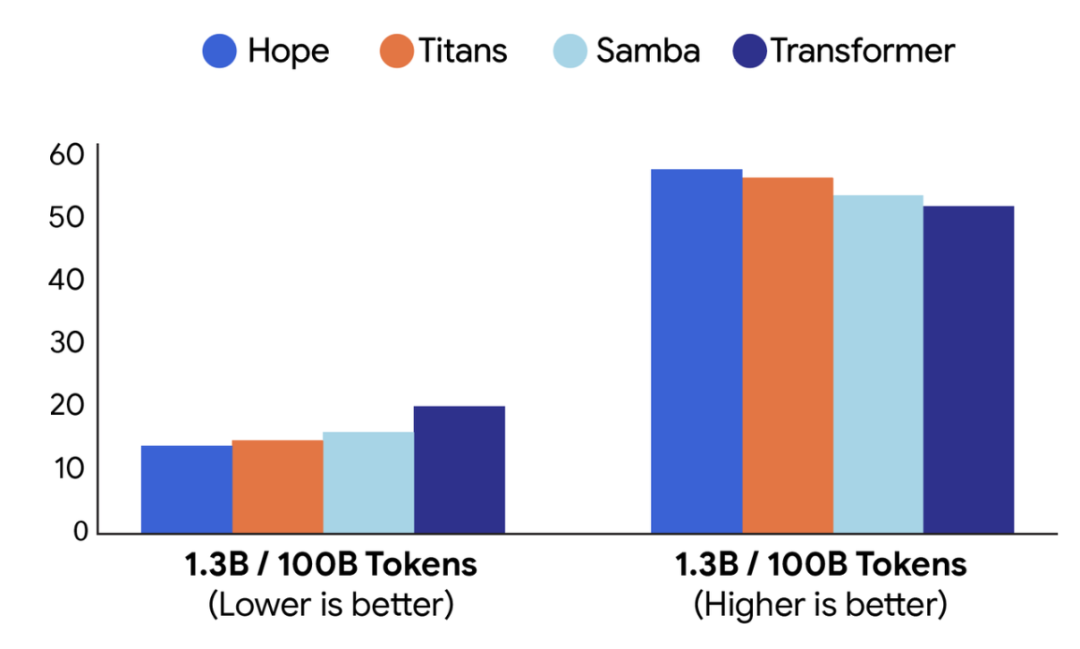
不同架构在语言建模任务(困惑度,左)和常识推理任务(准确率,右)上的性能对比:包括 Hope、Titans、Samba 以及基线 Transformer。
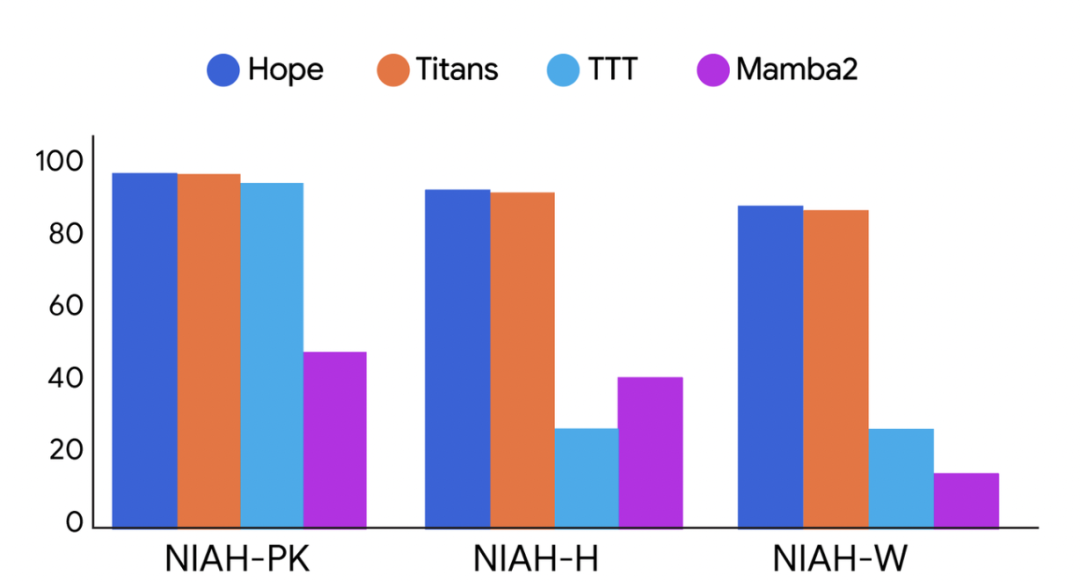
不同架构在长上下文任务中、不同难度等级下的性能对比:包括 Hope、Titans、TTT 和 Mamba2。其中,NIAH-PK、NIAH-H 和 NIAH-W 分别表示大海捞针任务的三种类型:通行密钥、数字和单词。
总的来看,嵌套学习代表了谷歌对深度学习理解迈进了新阶段,通过将架构与优化视为统一的、层次化的优化系统,打开了一个全新的设计维度。由此产生的模型(如 Hope)则表明,这种系统性整合方法能够带来更强的表达能力、更高的效率与持续学习能力。
或许可以说,嵌套学习为弥合当前 LLM「易遗忘」的局限与人脑卓越的持续学习能力之间的差距奠定了坚实的理论与实践基础,为构建下一代可自我改进的人工智能(self-improving AI)提供了新的可能性。
参考链接:
https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/
https://x.com/behrouz_ali/status/1986875258935066946
https://x.com/JeffDean/status/1986938111839129858
文章来自于微信公众号 “机器之心”,作者 “机器之心”



