# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型智能体的强化学习框架, 首次实现了通用的多智能体的“群体强化”。
在大语言模型(LLM)智能体的各种任务中,已有大量研究表明在各领域下的多智能体工作流在未经训练的情况下就能相对单智能体有显著提升。
但是现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。
为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。
大语言模型驱动的多智能体系统在医疗、编程、科研、具身智能等多个领域均能大幅度提升任务表现。
为训练大模型智能体,Group Relative Policy Optimization (GRPO) 已被验证为通用的有效强化学习算法。然而,当前所有针对LLM的强化学习训练框架,包括GRPO算法本身,都局限于单智能体训练的范畴。多智能体间的协作优化,即“群体强化”的学习机制,仍然是一个亟待填补的空白。
GRPO算法的核心机制是,针对同一个输入(prompt),通过多次采样生成一组候选回答。随后,算法在组内对这些回答进行评估(例如,通过一个奖励模型),并计算它们之间的相对优势。
这种优势计算的有效性与公平性依赖于一个关键假设——组内所有用于比较的候选回答,都必须基于一个完全相同的上下文(即prompt)生成。
然而,将GRPO直接应用于多智能体(multi-agent)多轮(multi-turn)环境中存在一个核心困难。
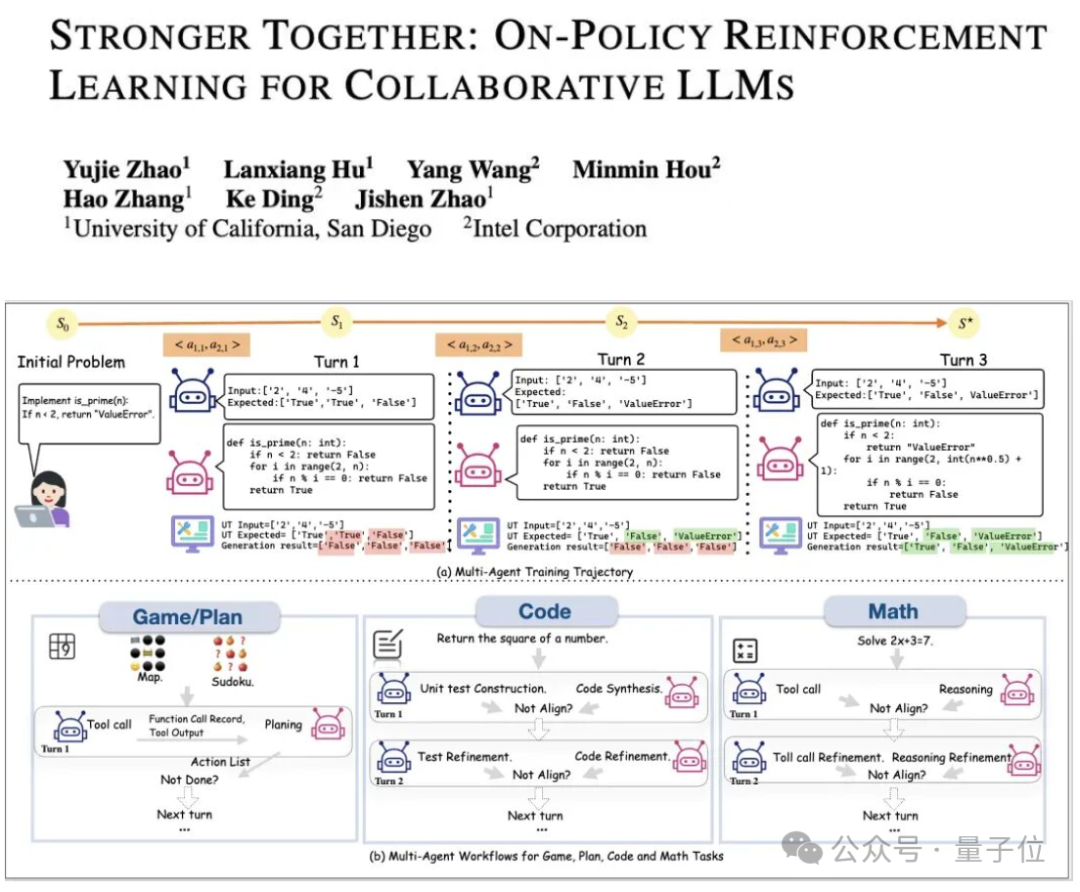
在多智能体场景下,即使是针对同一个初始问题,不同智能体在不同轮次接收到的prompt差异显著。
例如(如图所示),一个负责编程的智能体,其在第二轮的prompt不仅包含原始问题,还可能融合了第一轮中自己生成的代码以及其他智能体生成的单元测试。
因此,如果在MA环境中仍然简单地将同一个初始问题产生的所有(跨轮次、跨智能体的)回答视为一个“group”来进行优势计算,这就直接违反了GRPO所要求的“共同prompt”的核心假设。
这导致组内的优势计算基准不统一,使得计算结果不再公平或有效。
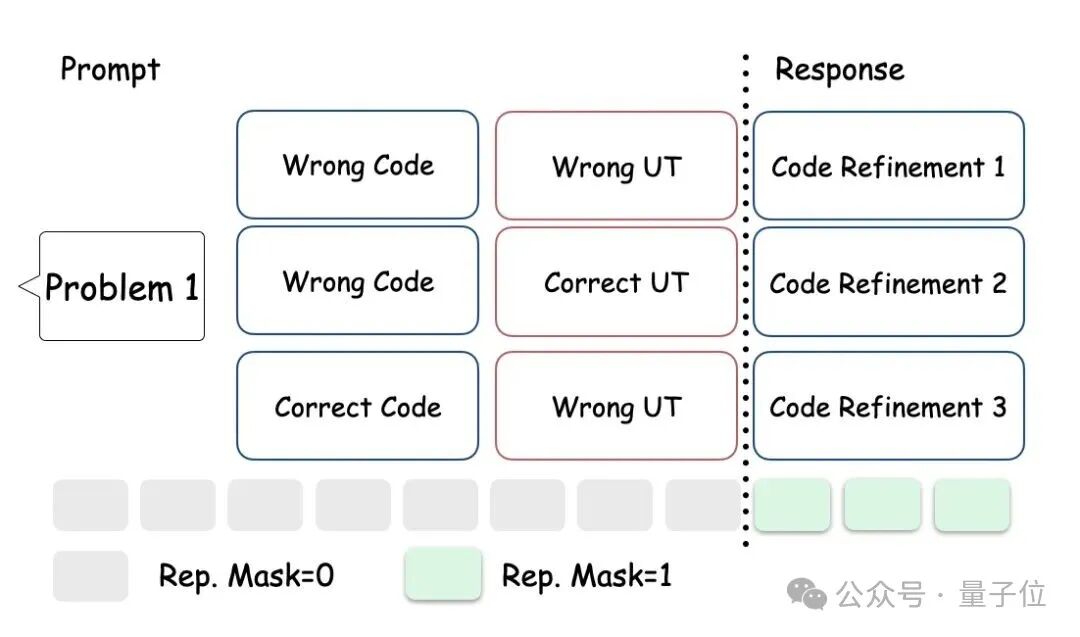
所以核心问题就是,如何既保证每个组内有一定批次量的回答,又能保证优势计算的公平。
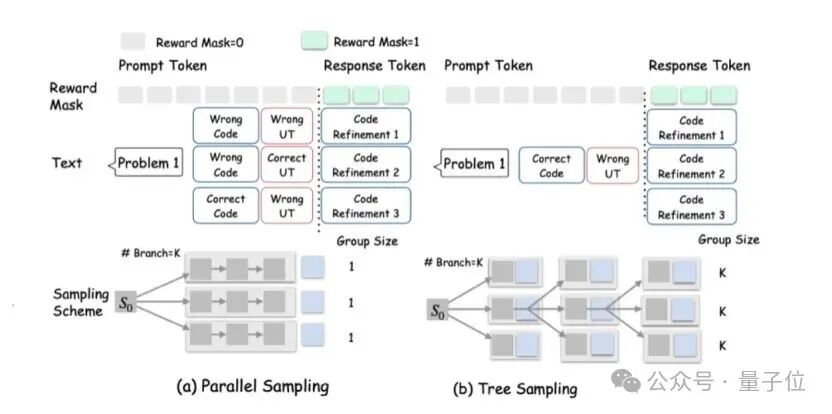
作者提出了一种greedy-search的树状采样方法。
每轮次每个agent形成一个节点进行K个分支,在分支以后选择此时reward最高的agent进行下一次分支。这样能够让多智能体训练能平衡好探索(exploration)与利用(exploitation)。
每一个agent的奖励函数都考虑自身角色的奖励和全局任务的奖励来保证角色专属能力和合作能力的进化。
对于多智能体的强化学习进化的另一个面临一个核心的策略问题:在何种任务下,让模型进化成不同角色的“专属模型”(specialized models)?又在何种任务下,让所有智能体共享一个“通用模型”(shared model)会更优?
为了实现两种不同的训练模式,作者搭建了如图所示的异步分发训练系统。
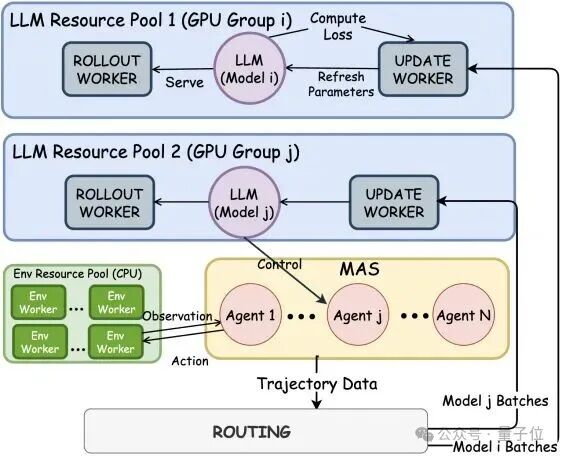
系统中的路由模块负责收集多智能体系统在环境中交互产生的轨迹数据。
专属模型模式下,系统可以配置多个独立的模型资源池(如图中的池i和池j)。路由模块会将智能体i的数据批次仅发送给池i的更新单元,专门更新模型i;同时将智能体j的数据批次发送给池j的更新单元,独立更新模型j。
而在共享模型模式中,相对地,路由模块也可以将所有智能体的轨迹数据合并,并全部发送给同一个模型资源池的更新单元,以集中更新一个共享模型。
通用的多智能体强化学习框架:PettingLLMs
基于该项研究,作者开源了通用的多智能体强化学习框架,使得多智能体强化学习训练开发变得敏捷、简洁、优雅。
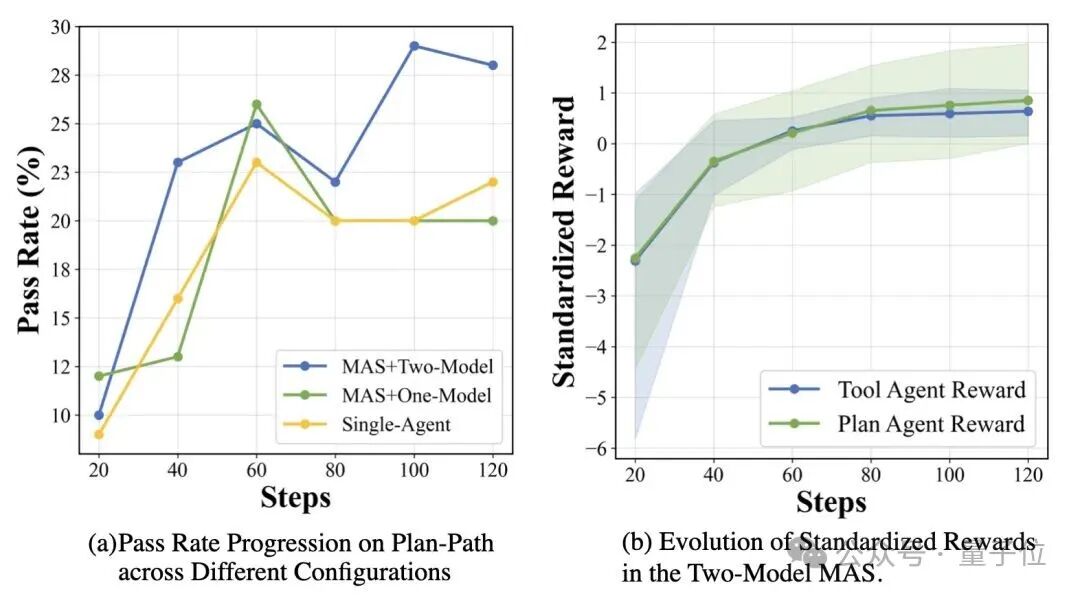
在推箱子这种长规划任务中,通过AT-GRPO训练,两个agent都得到了强化,任务性能从14%提升至96%。

作者在Qwen3-1.7B与Qwen3-8B两个规模上开展了大规模实验,覆盖规划(Sokoban、Plan-Path)、代码(LiveCodeBench、APPS、CodeContests)与数学(AIME24/25、OlympiadBench)三大类任务。
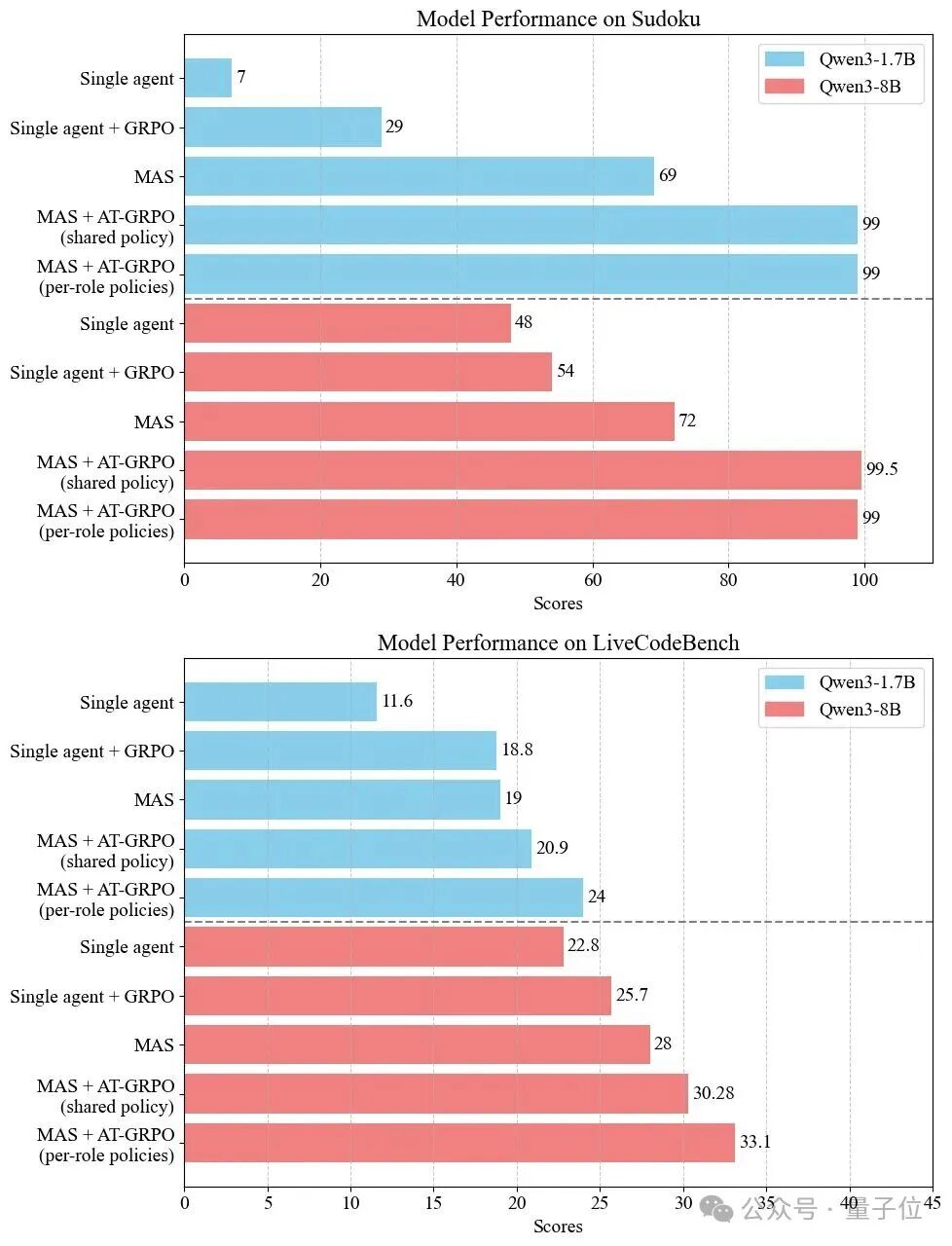
实验结果表明:
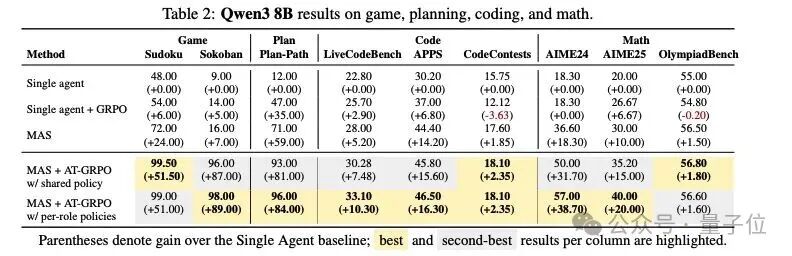
消融实验进一步验证了关键设计——
只在单智能体(SA)里训练,收益有限:把规划/工具等子角色各自放在 SA 环境里训练,单看各自指标会从 5.0% 提到11.0%/14.5%,但放回MAS联合作业仅到16.0%。
互换角色策略会“崩盘”:把已经学成的两个角色策略对调,准确率从96.0%→6.0%,说明两位“队友”学到的是互补但不可替代的能力。
协同越来越顺、回合越来越少:训练过程中两位代理的学习回报同步上升,任务所需平均回合数持续下降——体现出更紧密的对齐与分工协作。
PettingLLMs通过支持通用的多智能体强化学习算法,让多智能体一起学习一起进化,实现了跨任务、跨规模的通用强化学习算法。
论文:https://huggingface.co/papers/2510.11062
GitHub:https://github.com/pettingllms-ai/PettingLLMs
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
