# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
3D Gaussian Splatting (3DGS) 是一种日益流行的新视角合成方法,给定 3D 场景的一组带位姿的图像(即带有位置和方向的图像),3DGS 会迭代训练一个场景表示,该表示由大量各向异性 3D 高斯体组成,用以捕捉场景的外观和几何形状。
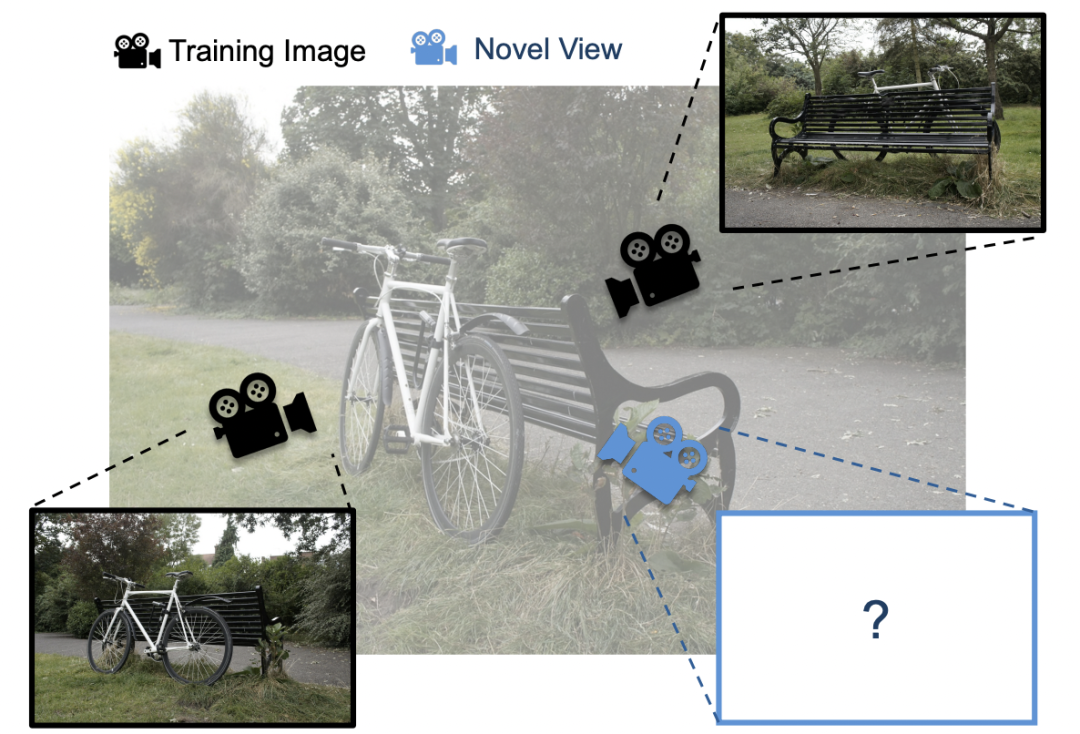
用户可以使用训练好的场景表示来渲染先前未见过的视角的图像。与其他新视角合成方法相比,3DGS 具有更快的渲染时间,同时能达到相当的图像质量,因此迅速普及开来。
3DGS 在当下的 3D 建模、数字孪生、影视制作 (VFX)、VR/AR 与机器人视觉重建 (SLAM) 等领域已展现出革命性的应用潜力。
使用 3DGS 渲染的图像质量取决于所训练场景表示的保真度。捕捉大面积区域或包含复杂细节的场景需要更多的高斯体。因此,3DGS 的内存占用会随着场景大小、场景复杂性或输出图像分辨率的增加而增长。
顶尖水平的 3DGS 实现运行在 GPU 上,而 GPU 的显存并不充裕。因此,在扩展 3DGS 并将其应用于具有高图像分辨率的大型复杂场景时,显存容量已成为一个障碍。
谢赛宁团队提出了 CLM 系统,该系统允许 3DGS 使用单块消费级 GPU(例如 RTX 4090)渲染大型场景。

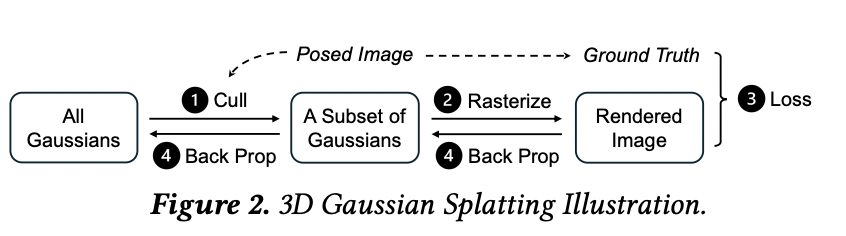
CLM 的设计基于这样一种洞察:3DGS 的计算本质上是稀疏的,即每次训练迭代只访问场景高斯体的一个小子集。因此,只需将这个子集加载到 GPU 内存中,而将其余的高斯体卸载到更充裕的 CPU 内存中即可。
为了提高性能并减少通信开销,CLM 基于对 3DGS 内存访问模式的深入理解,采用了一种新颖的卸载策略。该策略利用了关于 3DGS 训练流水线的四个观察,最大限度地减少了性能开销并能扩展到大型场景:
评估表明,由此产生的实现可以在单个 RTX 4090 上渲染一个需要 1.02 亿个高斯体的大型场景,并达到顶尖水平的重建质量。
此外当渲染可以装入基线系统 GPU 显存的小型场景时,与没有卸载的基线系统相比,CLM 针对 3DGS 的特定卸载解决方案仅产生适度的性能开销。
团队通过将部分高斯点参数存储在固定页主内存中,并在需要时动态加载到 GPU 内存,从而解决了前面提到的挑战。此外,团队还充分利用了 3DGS 的若干独特特性,以显著降低卸载带来的通信开销。
3DGS 计算具有高度稀疏性
3DGS 的计算过程是稀疏的:在渲染(无论是训练阶段还是推理阶段)时,只有场景中一小部分高斯点会被实际使用。这是因为每个视角都对应一个相机位姿,只有位于相机视锥体(frustum)内的高斯点才可能对最终渲染图像产生贡献(如下图所示)。
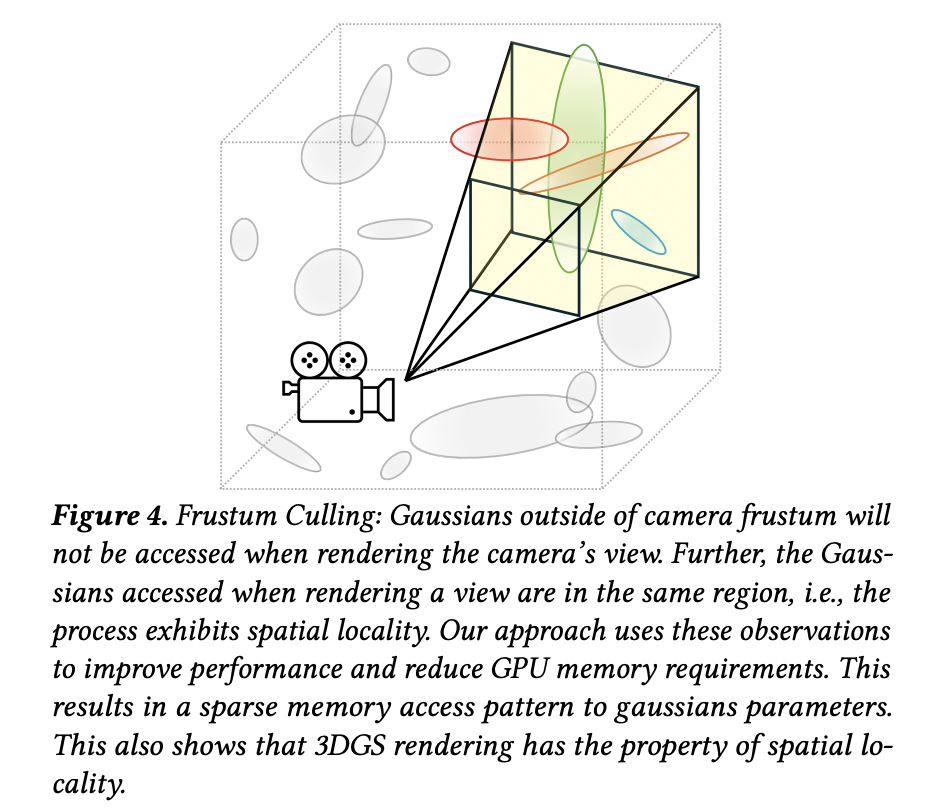
而事实上,3DGS 的渲染流程在处理某个视角之前,会显式计算出该视角内的高斯集合,然后再对这些高斯点进行渲染处理(如下图所示)。

结果表明:场景越大,其稀疏度越高(即 ρ 越小)。这符合预期,因为虽然高斯点数量会随场景规模增大而增加,但相机视锥体所覆盖的体积与场景整体大小无关。
在最大的数据集上,团队发现:
团队利用这种稀疏性,通过 3DGS 的视锥剔除(frustum culling)逻辑,提前识别出每个视角(以及其对应的 microbatch)所需的高斯点子集,并仅将这些必要的高斯点传输至 GPU,从而显著降低内存占用与数据传输量。
视角间的稀疏模式具有空间局部性

团队利用这种空间局部性(spatial locality),来优化 CPU 与 GPU 之间的数据传输:
稀疏模式的高效计算
在传统 3DGS 实现中,所有高斯点参数被存储在单个张量中,并且在 GPU 上执行视锥剔除以确定某个视角的稀疏模式。然而,这种做法要求所有高斯点都预先加载到 GPU 内存,这与「仅加载必要高斯点」的设计目标相冲突。
因此,团队通过仅使用部分高斯信息来预估稀疏模式,避免了不必要的 GPU 内存占用,为后续的高效卸载与缓存策略奠定了基础。
CLM 的核心思路是:通过将高斯参数和部分优化器计算卸载到 CPU 端,来扩展有效的 GPU 显存容量;同时基于 3DGS 稀疏性和空间局部性的观察结果,最大限度地减少 GPU-CPU 通信与 CPU 计算的开销。
目前 CLM 的实现基于 CUDA,但其设计与渲染后端无关,也可移植到 Vulkan 平台。

接着,将一个 batch 划分为多个 microbatch(微批次),以便在训练中启用流水线执行。更重要的是,CLM 根据视锥剔除的输出结果,优化 microbatch 的执行顺序,以最大化空间局部性。
最后,每个 microbatch 在流水线中执行,使得通信与计算(GPU 与 CPU)能够重叠进行。
具体而言:处理 microbatch 时,CLM 会将所需的视锥内高斯加载到 GPU 内存,通过 Gaussian Caching(高斯缓存机制) 避免重复加载连续 microbatch 中共享的高斯点。之后 GPU 执行前向与反向传播,梯度被传回 CPU,而一个并行 CPU 线程执行 Adam 优化器,更新高斯参数。
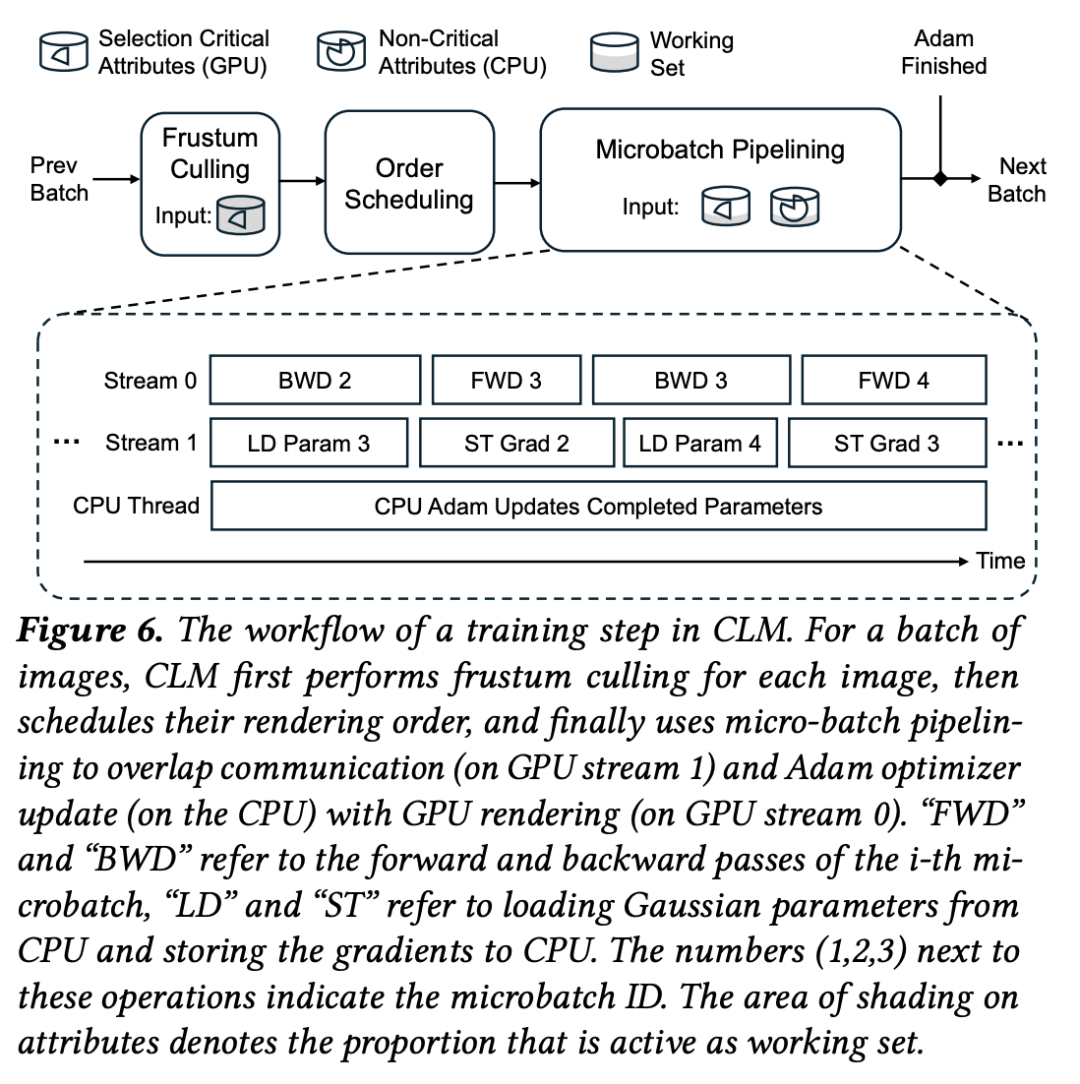
如上图所示:
而对于那些在某个 microbatch 中最后被更新的高斯点,CLM 会在 CPU 上完成其对应的 Adam 更新,并与后续microbatch的 GPU 前向 / 反向计算并行执行。
经过一系列的实验、评估,可以发现:CLM 具备更大规模的模型训练能力,通过将部分计算与数据卸载至 CPU,CLM 使得 3DGS 的可训练模型规模相比纯 GPU 训练基线提升了最高 6.1 倍;更高的重建质量,CLM 能够训练更大的模型,从而提升场景重建精度;更低的通信与卸载开销。
了解更多详细内容,请参考原论文!
文章来自于“机器之心”,作者 “机器之心编辑部”。


