# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。
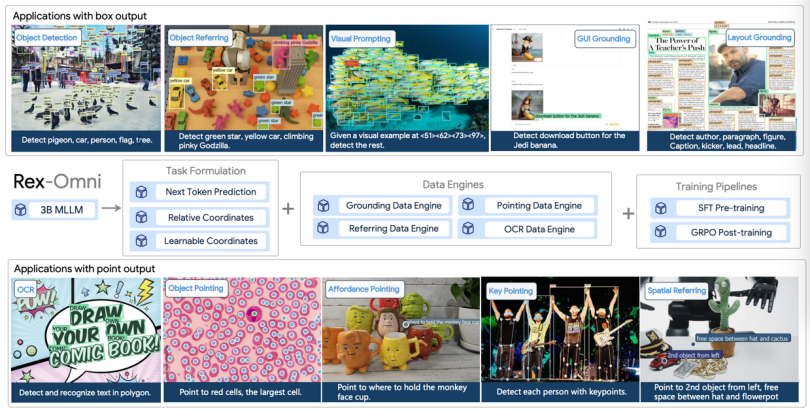
该模型将所有视觉感知任务统一为「下一个点预测」,并结合高效的 4-Token 坐标编码和两阶段 GRPO 强化学习后训练。在 COCO、LVIS 等核心检测基准的零样本评估下,Rex-Omni 的性能超越了 Grounding DINO,DINO 等基于坐标回归模型的。它系统解决了 MLLM 的定位和行为缺陷,在目标检测、指代、点选、GUI 定位、OCR、版面分析等 10 多项任务上实现 SOTA 的性能,预示着下一代强语言理解的感知系统的到来。

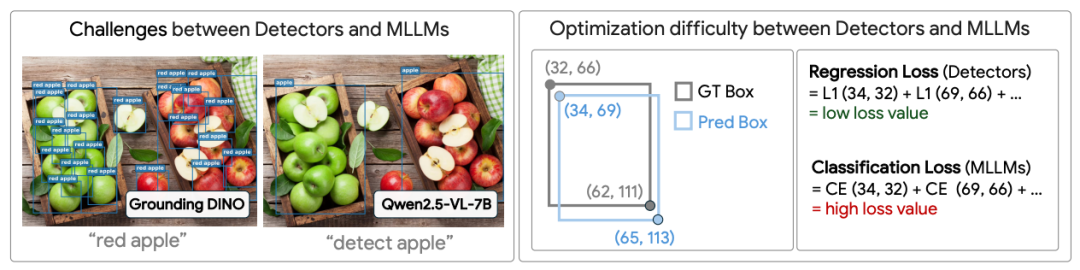
传统模型与 MLLM 模型在目标检测上各自的困境
目标检测领域的一个长远目标,就是构建一个能够根据任意自然语言提示,检测任意物体或概念,且无需任何微调的通用模型,这便是目标检测的「金杯」。长期以来,目标检测一直由基于回归的模型主宰,例如 DETR 和 Grounding DINO 等。这类模型的优势在于极高的定位精确度,但其本质受限于相对较浅的语言理解能力。例如,当用户提示 Grounding DINO 检测「红苹果」时,它仍然只能检测出图像中的所有苹果。简单地依赖这种基于类别级别的开放集检测方法,无法满足对复杂语义和精细描述的理解要求,难以实现真正的「金杯」。
另一方面,MLLM(如 Qwen2.5-VL, SEED1.5-VL) 因其底层的 LLM 具有强大的语言理解和推理能力,为实现这一目标带来了希望。它们将坐标视为离散的 Token,用交叉熵进行分类预测。然而,这种概念上优雅的方法在实践中面临两大根本挑战,导致其定位能力远未达到传统回归检测器的水平,并容易出现低召回率、坐标偏移和重复预测等问题:
要推动 MLLM 成为下一代检测模型,就必须系统性地克服这两个相互交织的根本挑战。
Rex-Omni 的建立在三项相互支撑的设计之上,包括任务设计,数据设计,训练 pipeline 设计,它们系统性地解决了 MLLM 的定位精度和行为缺陷,实现了「强大的语言理解」与「精确的几何感知」的融合:
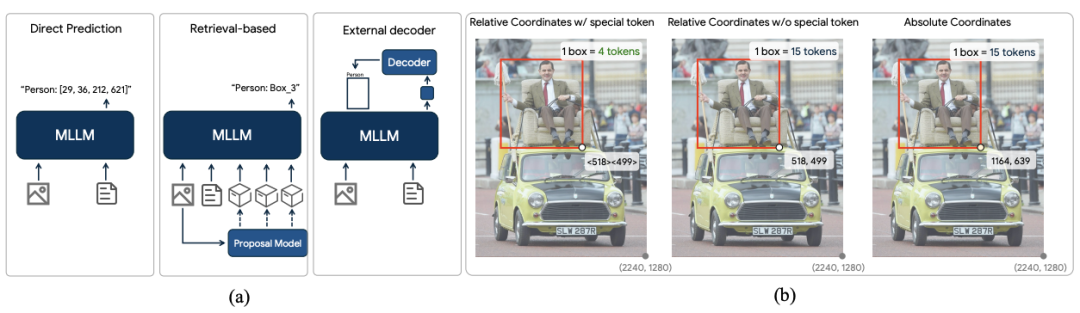
Rex-Omni 采用了量化坐标 + 特殊 token 的坐标表征形式
首先,为了解决「几何离散化挑战」,Rex-Omni 提出了一个统一的「下一个点预测」框架,将所有视觉感知任务(包括检测、点选、多边形输出)都转化为坐标序列的生成。

在模型结构上,Rex-Omni 采用了标准的 Qwen2.5-VL-3B 的架构。唯一的改动是把 Qwen2.5-VL-3B 词表中最后 1000 个不常用的 token 转换为了代表坐标的特殊 token <0> 到 <999>。

Rex-Omni 模型结构示意图
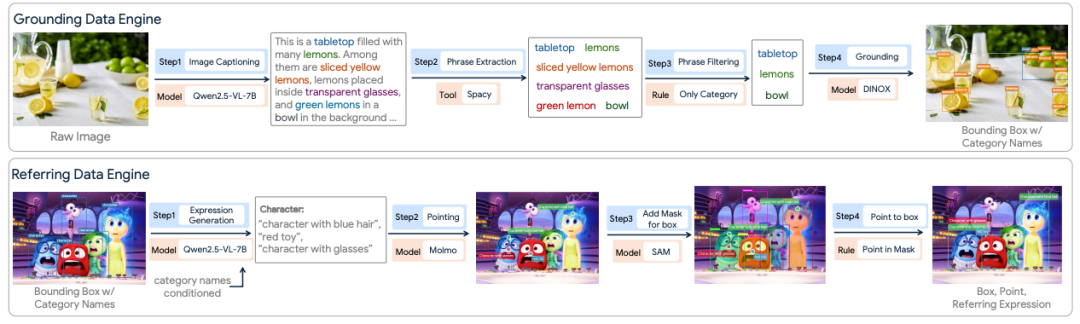
接下来,为确保模型能够将离散 Token 精确映射到连续像素,并具备鲁棒的语言理解能力,团队构建了多个定制化数据引擎(包括 Grounding、Referring、Pointing 和 OCR 数据引擎),以自动化方式生成了大规模、高质量的训练监督信号。
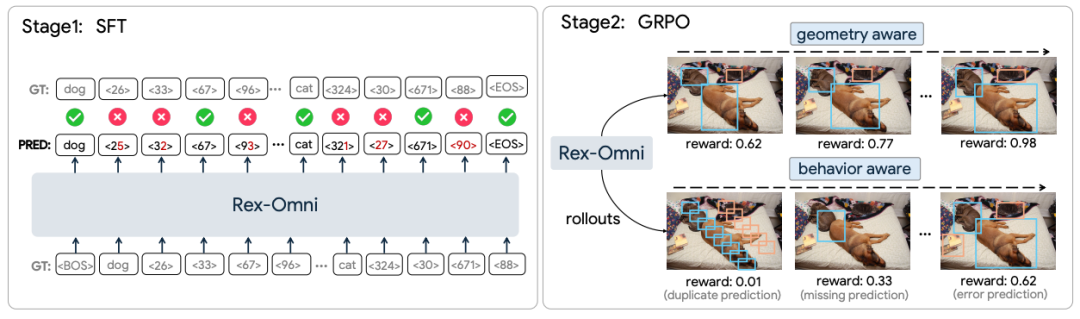
这是 Rex-Omni 达成高精度定位和克服行为调控缺陷的关键。它采用了 SFT + GRPO 的两阶段训练范式:
GRPO 通过引入几何感知奖励函数(如 IoU 奖励、点在掩码内奖励等)和行为感知优化,直接在模型自主生成的序列上进行反馈学习,从而系统性地解决了 SFT 阶段遗留的两大挑战:
实验结果表明,GRPO 并非简单的额外训练,而是解锁了 SFT 模型中强大的潜在能力,仅用少量训练步骤就带来了性能的快速、大幅提升,成为 Rex-Omni 超越传统检测器的重要推手。
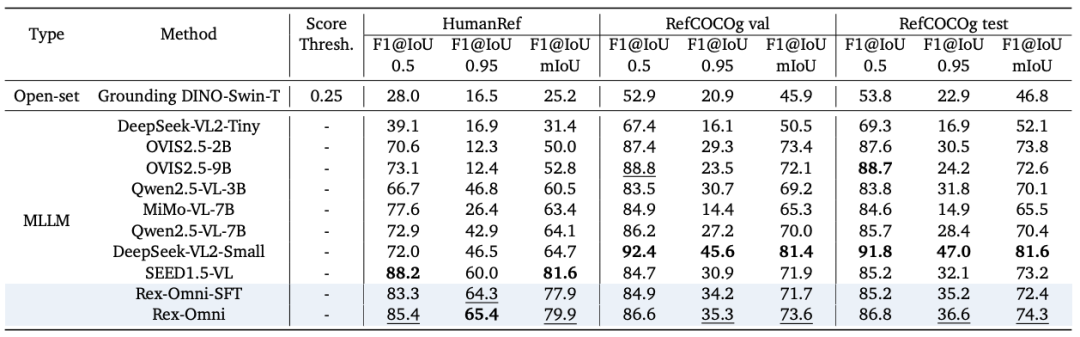
1)通用以及长尾目标检测性能评估
在通用目标检测 COCO 和 LVIS 等核心检测基准的零样本评估(不在评估 benchmark 的训练集上进行训练)设置下,Rex-Omni 的性能出色:Rex-Omni 的 F1-score(特别是 F1@IoU=0.5)首次展现出超越 Grounding DINO 等开放集专家模型的能力,并与 DINO 等传统封闭集模型持平或更高。这有力证明了离散预测的 MLLM,在精确的定位能力上完全可以与回归专家模型正面竞争。
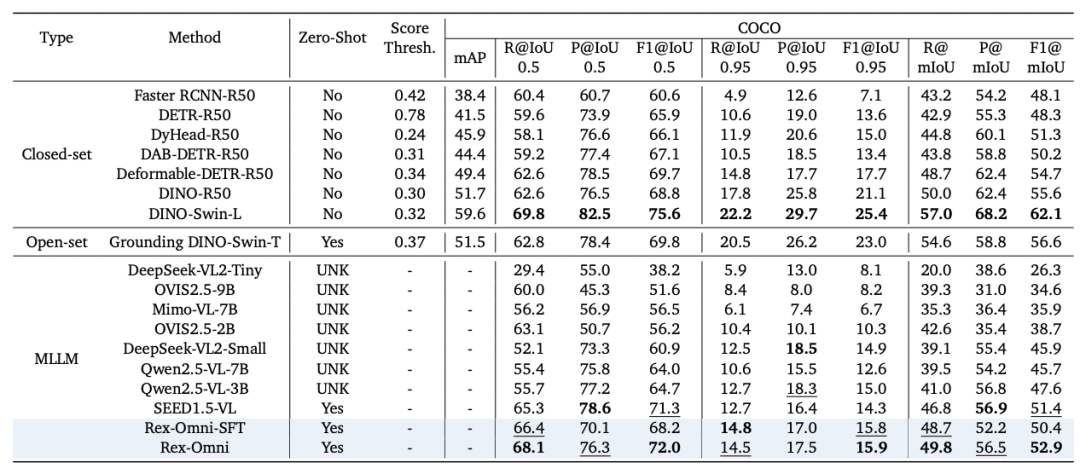
COCO 评估结果
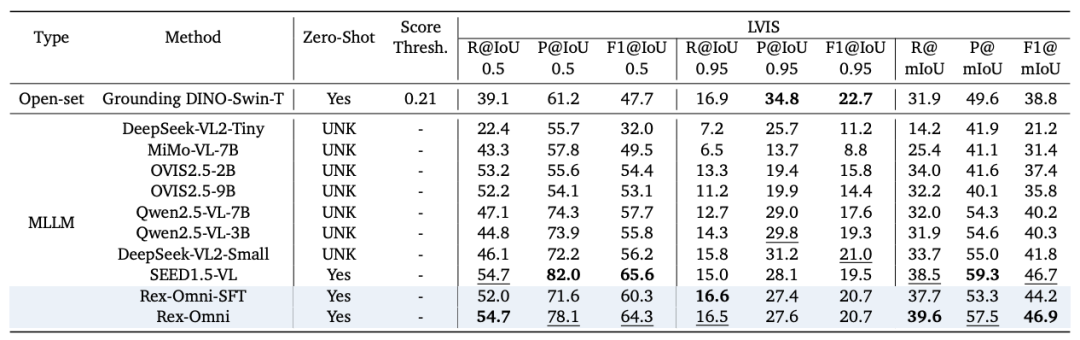
LVIS 评估结果

可视化结果可以看到,Rex-Omni 无论是定位框的精准度还是分类精准度都与传统模型如 Grounding DINO 不相上下。
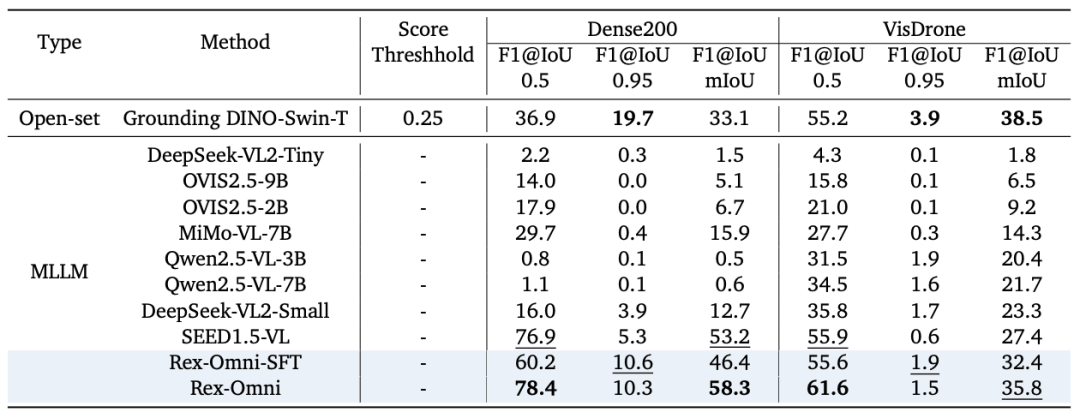
2)密集以及小物体检测性能评估
密集场景是 MLLM 的传统弱项,极度依赖于模型的精细坐标预测和输出调控能力。在 VisDrone 和 Dense200 等极具挑战的密集 / 微小目标检测任务上,Rex-Omni 取得了 MLLM 中的最高性能: Rex-Omni 的 F1@mIoU 性能在 MLLM 中居于榜首。GRPO 强化学习后训练为模型带来了实质性的性能飞跃,解决了 SFT 阶段容易产生的结构化重复预测等问题,使模型能够精准识别和定位大量微小对象。如下图所示,Rex-Omni 能够准确地检测出大量密集物体,且得益于其 4-Token 坐标编码,相比于 SEED1.5-VL 等模型,Rex-Omni 在输出相同数量目标时,耗费的 Token 数减少了 90% 以上,极大保障了在密集场景下的推理速度和效率。

3)全能制霸:统一框架下实现对多任务的通用处理
Rex-Omni 在一个统一的「下一个点预测」框架内,实现了对各种视觉感知任务的通用处理,并展现出强大的竞争力:




为什么仅用少量数据进行 GRPO 后训练,就能带来如此显著的性能飞跃?论文通过深入分析揭示了其背后的机制:
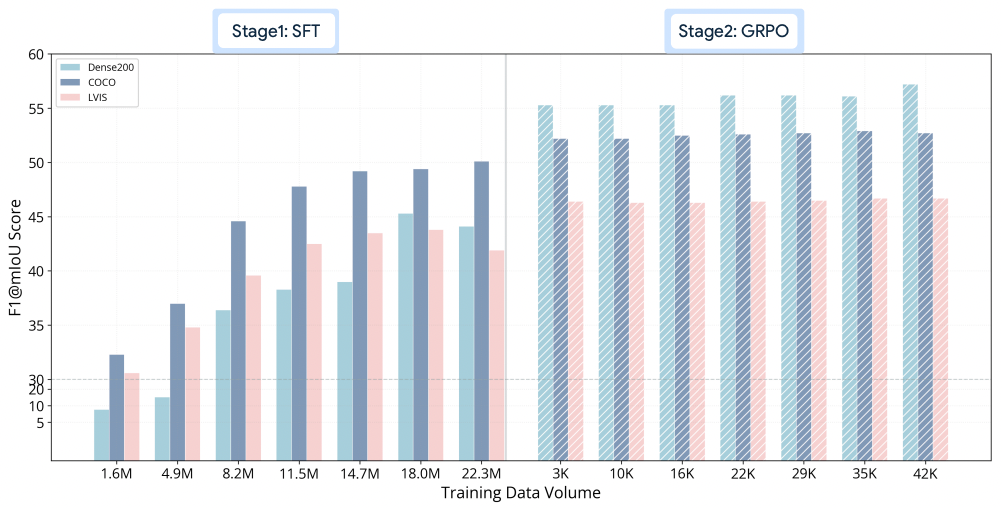
在不同训练阶段的模型性能随着训练数据增加的变化
如上图所示,SFT 阶段模型的性能随数据量增加而平稳上升并逐渐趋于平台期。然而,GRPO 阶段仅需极少的训练步骤,就能使性能曲线出现陡峭的跃升。
这表明,SFT 模型实际上已经具备了强大的定位「潜能」,但受限于「教师强制」的训练方式,这些潜能在自主推理时未能充分释放。GRPO 就像一把钥匙,通过奖励反馈解锁了这些潜在能力。
深入分析发现,GRPO 对最终性能的贡献,主要来自于对模型错误行为的系统性矫正,而非仅仅是让坐标精度提高几个像素:

研究还发现,SFT 模型其实有能力生成非常精准的预测(在 Top-N 采样中往往包含高质量答案),但在贪心解码时却往往选择了次优解。GRPO 的作用在于显著提升了模型采样到那些高质量、正确答案的概率,使其在实际应用中更可靠。
Rex-Omni 的工作为 MLLM 在视觉感知领域带来了系统性的解决方案。它通过高效的坐标编码和 SFT+GRPO 两阶段训练范式,成功证明了 MLLM 能够克服离散预测所带来的几何和行为局限性,实现了精确几何感知与鲁棒语言理解的有效融合。Rex-Omni 在零样本目标检测任务上,首次展现出超越传统回归专家模型的潜力,并在指代、点选、GUI 等多项任务中实现了强大的通用处理能力,这不仅为 MLLM 领域树立了新的性能标杆,更重要的是,它提供了一套可行的、具有竞争力的范式,表明 MLLM 有望成为结合语义推理与精确定位能力的统一模型。Rex-Omni 为下一代目标检测模型的构建,提供了一个有力的基线和发展方向。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
