# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在过去两年,大语言模型 (LLM) + 外部工具的能力,已成为推动 AI 从 “会说” 走向 “会做” 的关键机制 —— 尤其在 API 调用、多轮任务规划、知识检索、代码执行等场景中,大模型要想精准调用工具,不仅要求模型本身具备推理能力,还需要借助海量高质量、针对性强的函数调用训练数据。
然而,现有数据生成与训练流程多数是 “静态” 的 —— 数据在训练前一次性生成,无法感知到模型能力的改变。模型在微调或强化学习过程中也无法为数据生成提供正向反馈。这不仅可能导致模型对已掌握的简单任务重复学习、浪费算力,同时留下一些难点样本长期缺乏优化;此外,很多现有流程依赖昂贵的闭源 API 生成与评估数据,开源替代往往带入大量噪声标签,降低训练效果。
为解决这一系列问题,上海交通大学与小红书团队提出了 LoopTool:一个自动的(autonomous)、模型感知(model-aware)、迭代式(iterative)的数据进化框架,首次实现了工具调用任务的数据–模型闭环优化。团队仅依靠开源模型 Qwen3-32B 作为数据生成器与判别器,在无闭源 API 依赖的情况下,让一个 8B 规模的 LoopTool 模型在工具调用表现上显著超越其 32B 数据生成器,并在 BFCL-v3 与 ACEBench 公开榜单上取得同规模模型的最佳成绩。与此同时,训练后的 LoopTool-32B 模型也在这两个榜单上登顶,达到了目前开源模型的最佳成绩,进一步验证了闭环迭代优化在不同模型规模上的通用性与有效性。

论文指出,工具增强型 LLM 已经在多领域证明了其巨大价值,例如:API 调用,知识库查询、搜索引擎交互, 面向代码和多模态的任务执行, 复杂知识问答与数学问题。 但要让模型稳健地使用工具则应持续提供与其当前水平匹配,高质量且多样化的训练数据。目前主流方法(如 ToolLLM、APIGen 系列)采用 “先生成全量数据,再训练模型” 的静态流程,缺乏对模型学习状态与短板的实时反馈,且现阶段对模型工具调用能力的学习也多采用监督式微调的方法,使模型难以泛化到更多的工具类别上。
进一步地如果使用闭源生成 / 评估模型(如 GPT 系列),API 成本高且难以大规模迭代;改用开源模型则往往引入标签错误(参数不全、函数调用不符合任务要求等),会造成训练信号噪声累积甚至误导。
LoopTool 的核心思想是:让数据生成、标签修正与模型训练形成一个自动化的闭环,并由模型性能反馈驱动下一轮数据优化。它包括种子数据构建与迭代优化闭环两大阶段,后者又细分为四个核心模块。
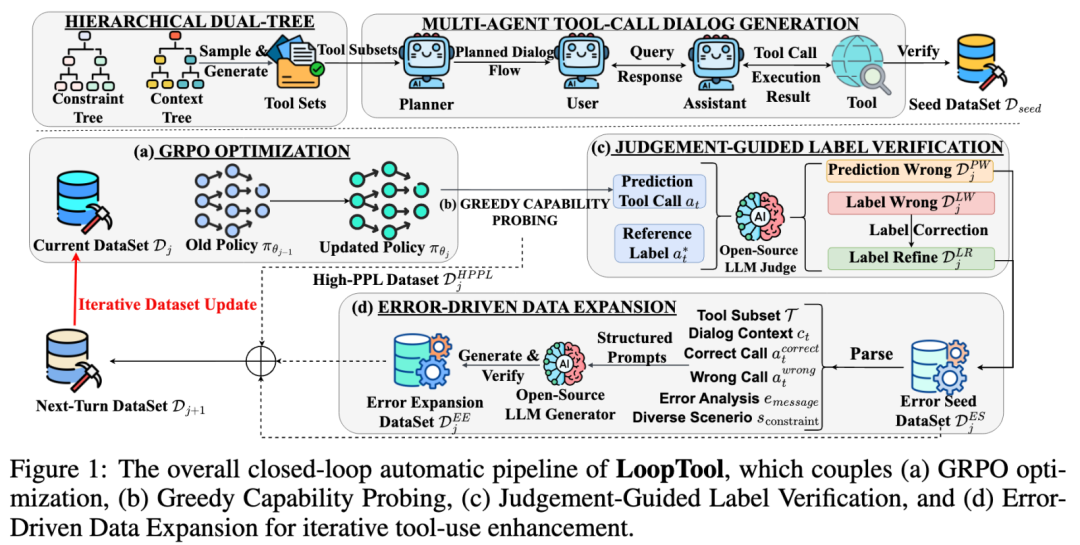
在迭代开始前,需要构建一个高质量、多样化的种子数据集。研究团队同时收集开源的各领域的 API 文献,同时也设计了两个分层树结构来辅助合成部分 API。 合成过程基于语义树 (Context Tree) 和约束树 (Constraint Tree),语义树描述领域主题与细化功能层级;约束树给出 API 结构限制,如命名规则、参数类型数量、返回格式等,通过在每棵树中独立抽取路径并合并,生成符合功能意图和结构规范的 API 定义,辅以规则验证确保生成 API 的一致性与语义完整性。
随后,这些 API 被置入多智能体工具调用对话生成 (Multi-Agent Tool-Use Dialogue Simulation) 流程线中。Planner Agent 基于抽样的工具子集规划整体任务流程与对话轮次;User Agent 根据规划在每一轮中发起请求、澄清条件、补充参数;Assistant Agent 结合当前上下文选择合适的工具,准备并执行具体的工具调用;Tool Agent 依据 API 规范模拟执行结果或者通过真实工具后端返回有效响应。所有生成的对话经 规则验证(API 语法、参数类型、schema 匹配)以及 LLM 验证(Qwen3-32B 判断逻辑一致性与语境相关性)两阶段筛选,确保了首轮训练的种子集数据的质量和多样性。
1. GRPO 强化学习训练 (GRPO Training for Tool Calling)

2. 贪婪能力探测 (Greedy Capability Probing, GCP)

3. 判别引导标签校验 (Judgement-Guided Label Verification, JGLV)
对于预测和标签不匹配的样本,使用开源模型 Qwen3-32B 作为评判者,比较模型预测与原标签孰优孰劣,分类为:(1)PRED_WRONG:模型预测错 ;(2)LABEL_WRONG:标签错,用模型预测替换标签;(3)BOTH_CORRECT:标签与预测均对,择高 PPL 保留;(4)BOTH_WRONG:全部丢弃。
不同于直接让 LLM 生成新标签,JGLV 以比较判别模式运行,减少生成噪声的风险,并随着模型水平的迭代提升,逐渐用更优预测反向优化训练集。
4. 错误驱动数据扩展 (Error-Driven Data Expansion, EDDE)
针对通过 JGLV 验证的错误种子样本,EDDE 模块进行结构保持与情境多样化生成,具体而言分析原始错误案例的结构模式与潜在误区,构造出保持任务难度但在情境和参数上经过多样化改造的新样本,这些合成数据经过与种子阶段相同的双重验证后,被并入下一轮训练集。
新一轮训练的数据集因此由四部分组成:高困惑度样本、经过判别修正的错误种子样本、错误驱动生成的新数据以及原始种子集中未使用的子样本。这样的设计保证每一轮训练都在最新的模型能力诊断结果与高价值样本的驱动下进行,形成训练–测评–修正–扩展的完整闭环,不断推动模型将 “薄弱环节” 转化为新能力点。
研究团队选用了开源的 Qwen3-8B 模型 以及 Qwen3-32B 模型作为迭代训练的基础模型,对于 8B 模型进行了 4 次迭代训练, 对于 32B 模型进行了单次的迭代训练。为了系统性评测模型在工具调用方面的能力,选用了 BFCL-v3 和 ACEBench 作为主要的评测框架,同时也测试了训练后模型在编程,数学等问题上的通用能力以及在下游应用任务下的能力。
BFCL-v3 涵盖了单轮、多轮调用场景,对模型的工具调用能力进行多维评估。在该榜单上,LoopTool-8B 总体准确率达到 74.93%,在所有 8B 规模开源模型中排名第一,较原始 Qwen3-8B 提升了 +8.59 个百分点,单轮调用准确率和 Live 执行准确率均为最高。更具代表性的是,该模型在总体性能上超越了用作数据生成与评判的 Qwen3-32B。LoopTool-32B 则在榜单上以 79.32% 的总体准确率位列第一,在单轮调用上达到最优成绩,且多轮场景表现也优异。
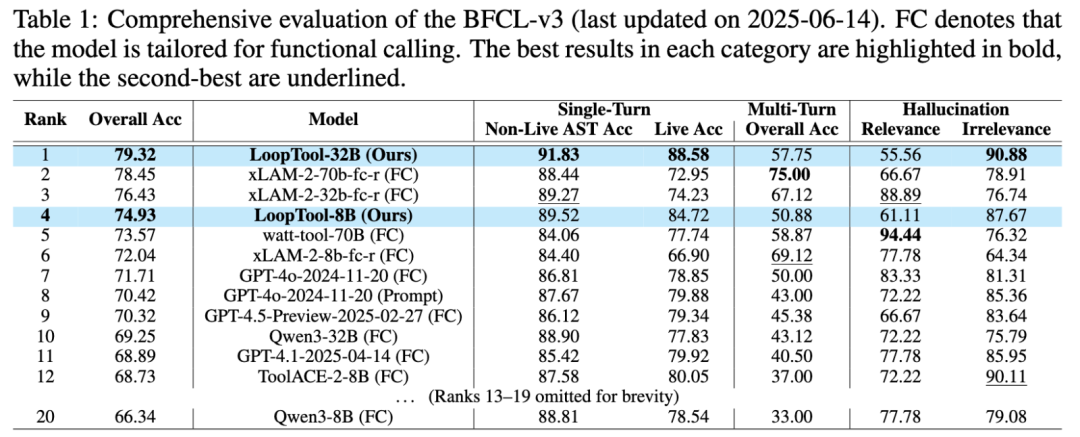
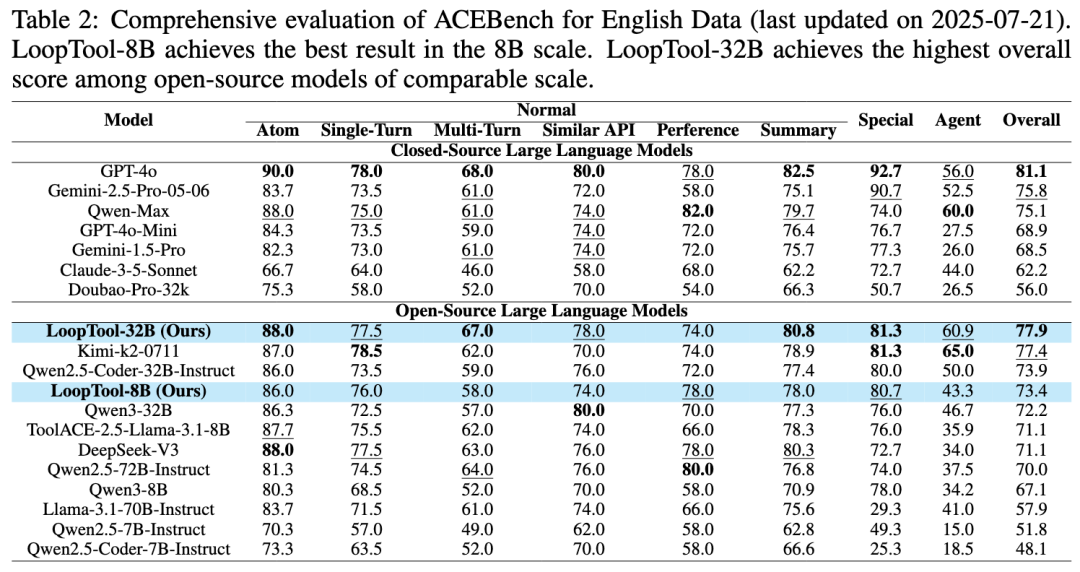
ACEBench 细分为 Normal, Sepcial, Agent 三类场景。评测结果显示,LoopTool-8B 以 73.4% 总体分数夺得同规模第一,比原始 Qwen3-8B 高出 6.3 分,在多类评测中均保持相对均衡优势。LoopTool-32B 达到了开源模型榜单中的第一,仅次于 GPT-4o 模型的表现。
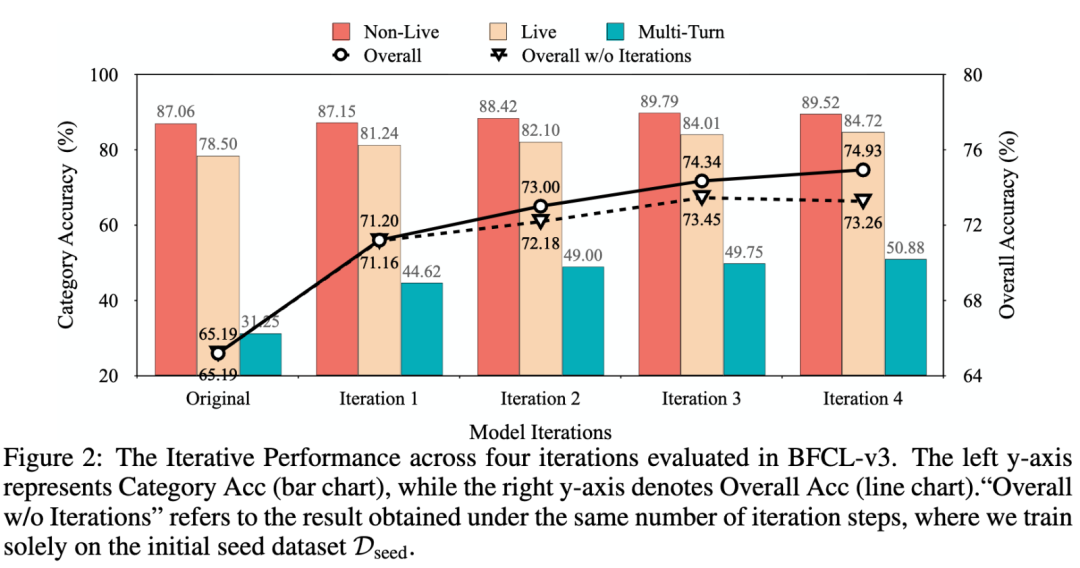
为了进一步对比 LoopTool 迭代优化和静态训练的差别,研究团队设置了对照实验,对比 LoopTool-8B 与静态数据训练的结果。结果显示,在 BFCL-v3 中,LoopTool 的性能随迭代逐步提升,从初始模型到第 4 轮迭代持续增长,而静态训练在第二轮后即出现平稳,甚至因数据分布与模型能力越来越不匹配而下滑。
为了评估 LoopTool 每个核心模块的贡献,论文在 BFCL-v3 基准上进行了多组消融对比,分别针对高困惑度样本筛选 (High-PPL)、判决引导标签校正 (JGLV)、以及错误驱动数据扩展 (EDDE) 模块。

作者还测试了 LoopTool 在不同规模模型上的表现,范围涵盖 0.6B 到 8B 参数量,并在 BFCL-v3 上进行两轮迭代训练。
结果清晰显示:模型规模越大,初始迭代 (Iteration 1) 和优化迭代 (Iteration 2) 阶段的准确率都更高。大模型在迭代中获得的绝对性能提升也更明显 —— 0.6B 模型仅提升 +0.70 个百分点,而 8B 模型则提升了 +1.80 个百分点。这种趋势源于 GRPO 强化学习依赖模型在探索中识别正确工具调用轨迹的能力。更大规模的模型往往能更早发现有效解法,从而更大化迭代式数据精炼的优势。

为了确保闭环优化不会让模型在非工具领域上的性能退化,作者在六个不同通用任务上测试并比较了 LoopTool 模型与原始模型:包括 MMLU-redux(综合常识)、IFEval(指令跟随)、LiveCodeBench(代码生成)、Math-500、AIME24、AIME25(数学竞赛题)。结果表明,LoopTool-8B 在全部任务上匹配或超越原模型,尤其在指令跟随 (+1.40) 与代码生成 (+3.84) 上提升显著,说明闭环数据演化不仅增强了工具调用,还提升了泛化推理与复杂任务处理能力。LoopTool-32B 则在数学任务上超越原始模型,在其他任务上与原始模型持平。

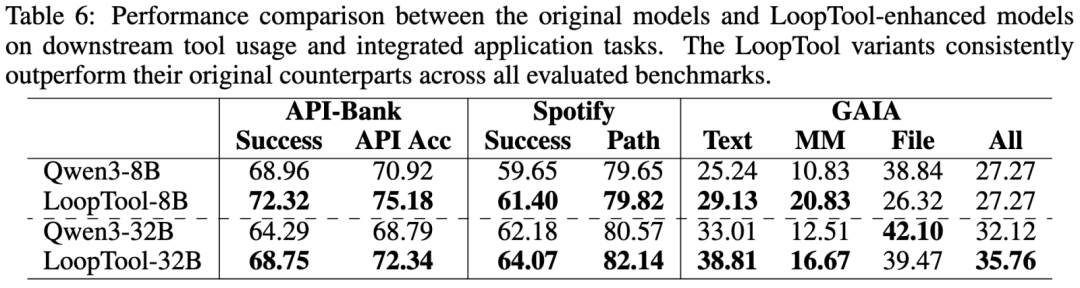
进一步地,团队借助了 DeepAgent 框架来评测模型在下游工具使用场景下解决现实问题的能力,包括以下评测基准:
评测结果表明,LoopTool 工具使用能力的提升,有效地增强了对实际问题的解决能力。
LoopTool 呈现了一个完全自动化、模型感知的闭环管道,将数据合成、标签校正以及基于 GRPO 的模型训练紧密结合,形成迭代优化循环,用于增强大型语言模型的工具使用能力。整个过程完全依赖开源模型完成数据生成与评估,不仅降低了成本,还确保了数据的高质量与多样性。在多轮迭代中,LoopTool 不断针对模型的薄弱点合成更具挑战性的样本,同时校正噪声标签,让训练数据随着模型能力的提升而动态进化。经过 LoopTool 迭代训练的 8B 与 32B 模型在公开的测评榜单中达到了新的 SOTA 成绩。LoopTool 不仅证明了模型闭环进化的有效性,也验证了开源框架在无依赖闭源 API 的条件下仍能达到乃至超越更大规模模型的表现。
文章来自于“机器之心”,作者 “机器之心编辑部”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
