# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
扩散模型「去噪」,是不是反而忘了真正去噪?何恺明携弟子出手,回归本源!
何恺明新作!
无需使用tokenizer,无需预训练,也无需任何额外的损失函数,何恺明等提出了一种「简单但强大」的方法。
他们证明,Transformer简单地在像素上使用大尺寸图像块(large-patch),就能成为一个强大的生成式模型。

预印本链接:https://arxiv.org/abs/2511.13720
标题:Back to Basics: Let Denoising Generative Models Denoise
论文中给出的生成样本,可见图像质量相当细腻自然,色彩和结构表达力也很强:

作为参照基准,他们在表7和表8中与前人研究成果进行了系统对比。
相较于其他基于像素的方法,新方案完全由通用型Transformer架构驱动,具有计算友好特性,成功避免了分辨率翻倍时计算量的二次增长(详见表8中的浮点运算量统计Gflops)。
表7评估了5万张生成样本的FID和IS指标。
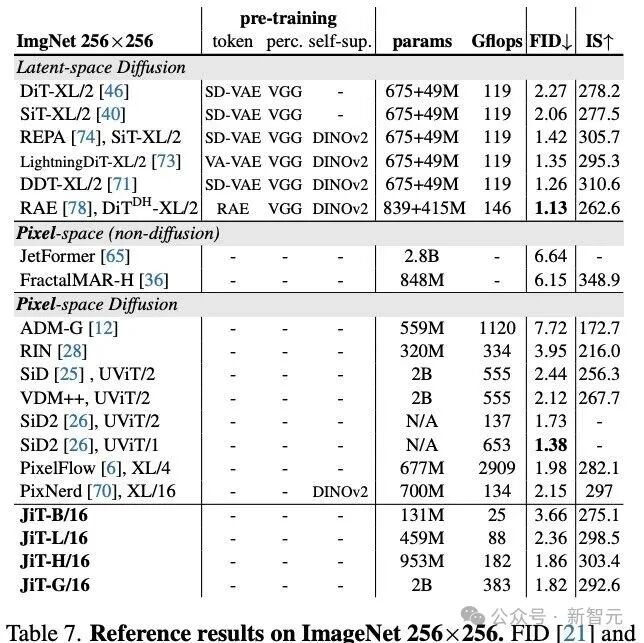
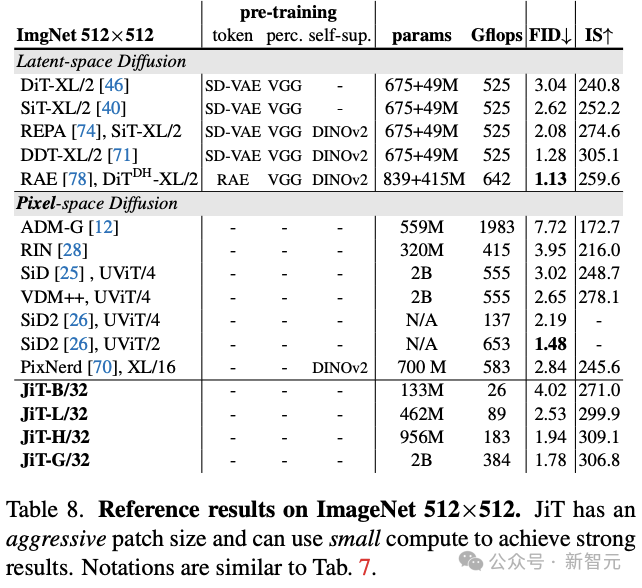
表8呈现了ImageNet在512×512分辨率下的基准测试结果。
JiT模型通过采用更激进的块大小,用较低的计算代价实现出色的生成效果。
他们坦言,推动的是一种面向原始自然数据的「扩散+Transformer」建模理念,强调结构简洁、过程闭环、自洽独立。
JiT全面展示了纯Transformer架构在图像生成中的潜力,而这种理念在其他自然数据领域(如蛋白质、分子、气象等)同样大有可为,尤其在这些领域中设计tokenizer往往异常困难。
通过最小化特定领域的定制设计,它们希望,这种起源于视觉的通用建模范式,未来能在更广阔的跨学科场景中落地生根。
论文一开始,就点名:如今的去噪扩散模型走了一条歧路——
其实,它们并不是真正意义上的「去噪」。
它们并不直接生成干净图像,而是预测噪声或带噪声的量。
何恺明新研究的核心观点在于:预测干净数据和预测带噪数据,本质上截然不同。
根据流形假设,自然图像数据应分布在低维流形上,而带噪数据则不具备这一特性。
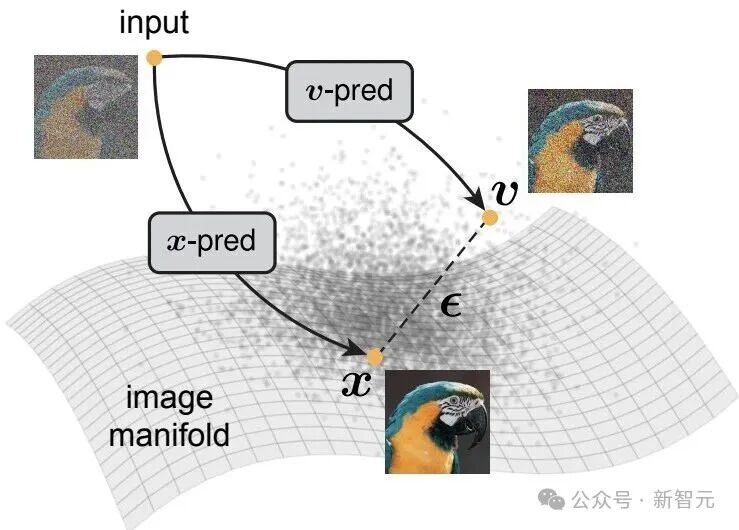
图1. 流形假设示意图
流形假设的核心思想是:自然图像,存在于高维像素空间中的一个低维流形之上。
在此概念框架下,干净图像x位于流形之上,而噪声ϵ或流速度v(例如 v = x - ϵ)本质上则游离于流形之外。
这揭示了去噪模型训练的两种根本不同路径:一是训练神经网络直接预测干净图像(即x-prediction),二是训练其预测噪声或含噪量(即ϵ/v-prediction)。
若要高维空间中预测噪声,模型就必须具备极高的容量——因为它需要完整保留噪声的所有信息。
而相较之下,如果目标是预测干净数据,即便神经网络容量有限,也能胜任,因为它只需保留低维信息,同时滤除噪声。
此外,扩散模型还有多个缺陷:
为了解决这个问题,研究者们近年来愈发重视「在像素空间中进行扩散建模」。
何恺明等人认为,这些架构选择的背后,其实是在努力克服预测高维带噪量所需的建模难度。
他们这次回归扩散建模的基本原理:让神经网络直接预测干净图像。
最后,他们发现,只要采用最基础的Vision Transformer(ViT),基于大尺寸图像Patch(由原始像素构成)即可实现有效建模。
新方案完全自洽:
无需任何预训练或辅助损失函数,
无需潜空间tokenizer,
无需对抗损失 ,
无需感知损失(即不依赖预训练分类器),
也无需特征对齐机制(因此不依赖自监督预训练)。
他们称之为「纯图像Transformer」(Just image Transformers,简称JiT)。
事实上,「x预测」这一策略并不新鲜,甚至可以追溯到最初的DDPM论文,其代码实现中就包含了这一形式。

论文链接:https://dl.acm.org/doi/abs/10.5555/3495724.3496298
标题:Denoising diffusion probabilistic models
不过在早期实验中,DDPM团队发现ϵ预测性能显著更好,从而逐渐成为标准做法。最后,这一做法无意中成了「历史的遗憾」。
在这项研究同时,也有研究在面向条件生成的世界模型中提倡采用x预测。

预印本:https://arxiv.org/abs/2509.24527
标题:Training Agents Inside of Scalable World Models
新研究并不试图「重新发明」x预测这个基本概念,而是想强调:在高维数据与低维流形共存的语境下,直接预测干净数据这一问题长期被忽视,但却至关重要。
扩散模型的预测,可以在三个不同空间中进行:x空间(即干净图像)、ϵ空间(噪声)或v空间(流速)。
选择在哪个空间建模,不仅决定了损失函数的定义位置,也影响了神经网络输出的内容。
需要特别强调的是:损失空间与网络输出空间可以不同,这一选择会对最终性能产生显著影响。
由于三者(x、ϵ、v)之间彼此依赖,只需设定一个网络输出,同时结合另外两个约束条件,即可推导出其余两个变量。
这两个约束条件分别是:
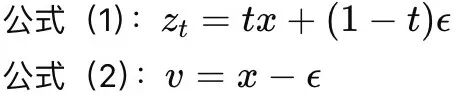
比如,神经网络直接输出x,联立方程组
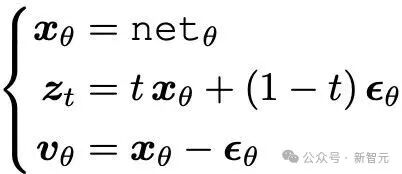
由此可解出:
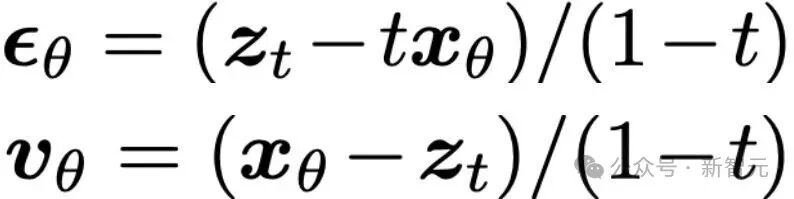
这意味着:只要网络输出了x,其对应的ϵ和v都可以显式计算出来。表1的(a)列正是总结了这种情况下的转换关系。
同理,若网络直接输出ϵ或v,即可推出相应的三元关系。表1中的(b)和(c)列分别总结了ϵ预测与v预测下的变换。

综上:x、ϵ、v三者中只需预测其一,另外两个均可由公式推导得出。
理论上,损失函数也可以定义在任意空间。
已有研究指出:在已知不同预测空间之间重参数化关系的前提下,不同损失形式之间是加权等价的。具体形式已在表1中系统列出。
将x、ϵ、v三种预测空间与三种损失空间进行两两组合,总共构成了九种合法的建模形式(见表1)。这些组合在数学上各自有效,但两两之间并不完全等价。
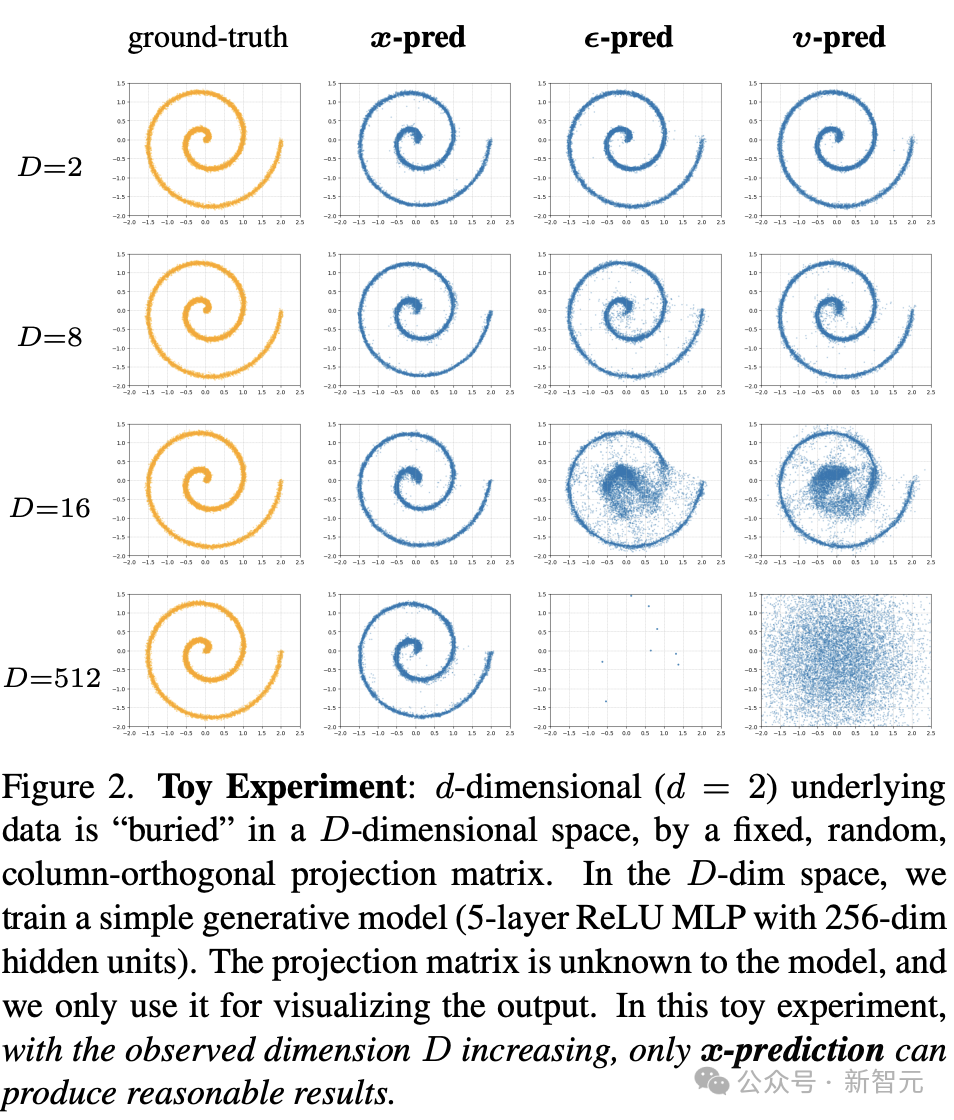
此外,如图2所示,作者通过一个玩具实验展示:当原始低维数据被嵌入更高维空间后,只有x预测仍能稳定生成合理输出,ϵ与v预测则迅速退化。
无论训练时采用哪种预测/损失组合,推理阶段都可统一转换至v空间(即表1中第3行),再进行ODE采样。因此,这九种形式在生成意义上均合法有效,可根据任务需求灵活选择。
ViT的核心思想是「图像Patch上Transformer」(ToP,Transformer on Patches)——新提出的架构设计也沿用这一理念。
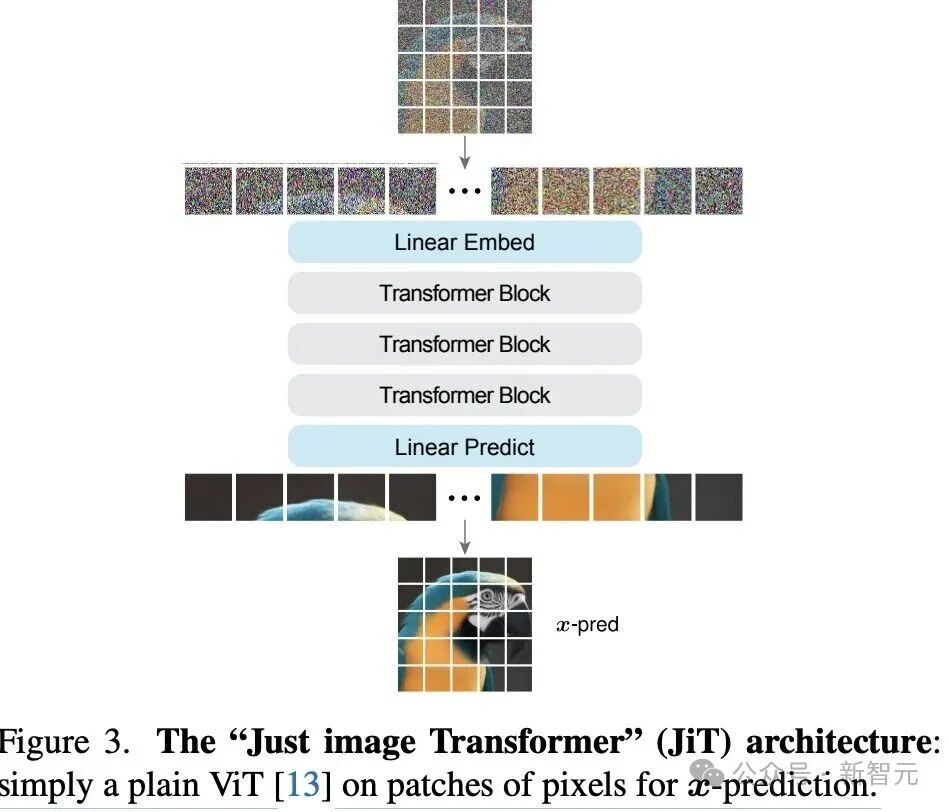
如图3所示,这种结构与DiT(Diffusion Transformer)非常相似,但核心差别在于:JiT直接在原始像素上建模,完全依赖x预测。
此外,模型在训练过程中也进行条件控制(如时间t和类别标签),采用了adaLN-Zero 方法来实现条件嵌入。
表1总结了9种「损失空间 + 预测空间」的组合形式。
为研究它们在实际表现上的差异,研究者分别使用ViT-Base(JiT-B)模型对每种组合进行训练。
根据ImageNet上的大量实验,作者归纳出以下几个关键结论,进一步验证了 「只用x预测+ViT」 这一策略在高维像素扩散建模中的可行性与优势:
✅ x预测至关重要
原因在于:ϵ和v包含高维噪声信息,对模型容量要求极高,而x预测只需保留低维干净数据结构,更容易学习;这与前文玩具实验的发现一致(图2)。
⚖️ 损失加权不是万能解法
x预测在三种损失空间下都有效,而ϵ/v预测在所有损失权重下均失败,说明关键不在加权,而在预测对象本身。
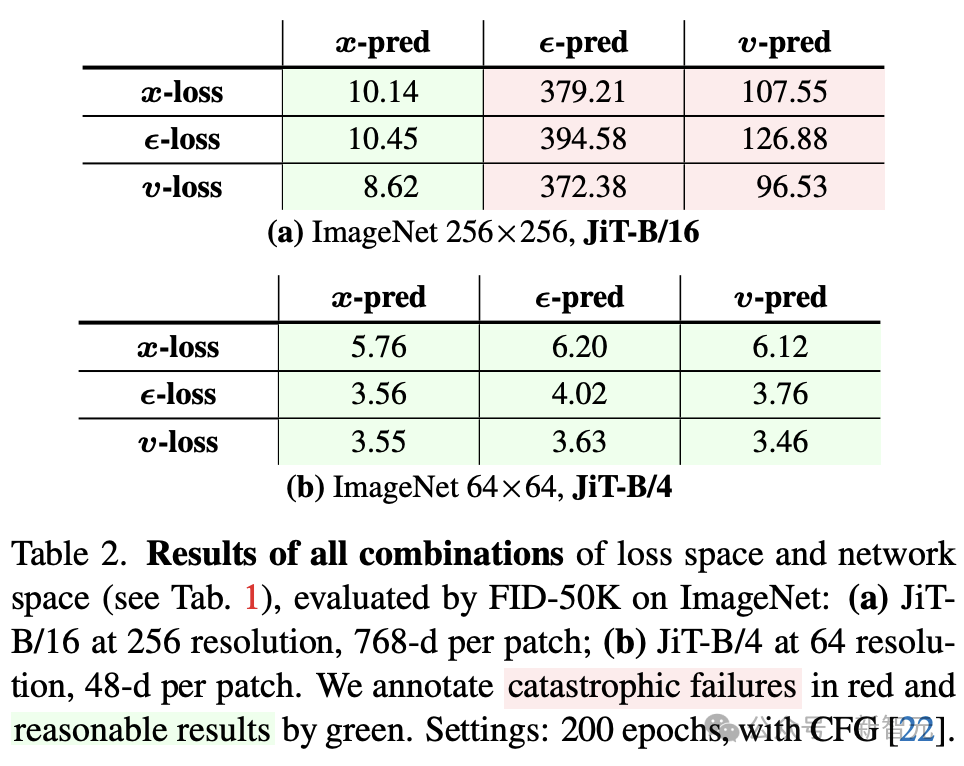
表3展示了在不同噪声水平下(通过调整logit-normal分布的参数µ)各预测方式的FID变化:
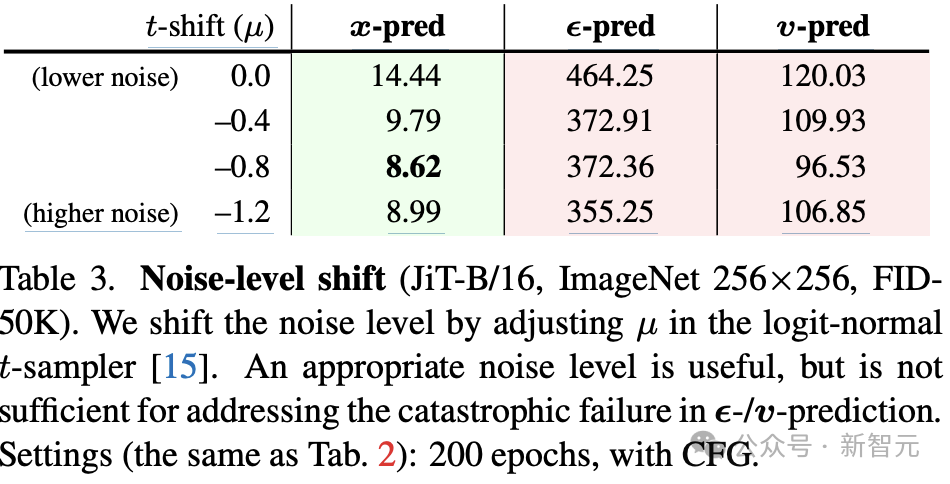
图4展示了对线性Patch嵌入层加入低秩瓶颈(bottleneck)结构后的结果:
结果发现:适度瓶颈不仅不会崩溃,反而能提升性能——FID下降最多达到约1.3分。
这说明信息压缩有助于网络聚焦于低维有效特征,契合流形假设与人类感知机制。
虽然理论上增加模型容量可能有助于提升性能,但在高维下,这种方法成本高昂且并不必要。
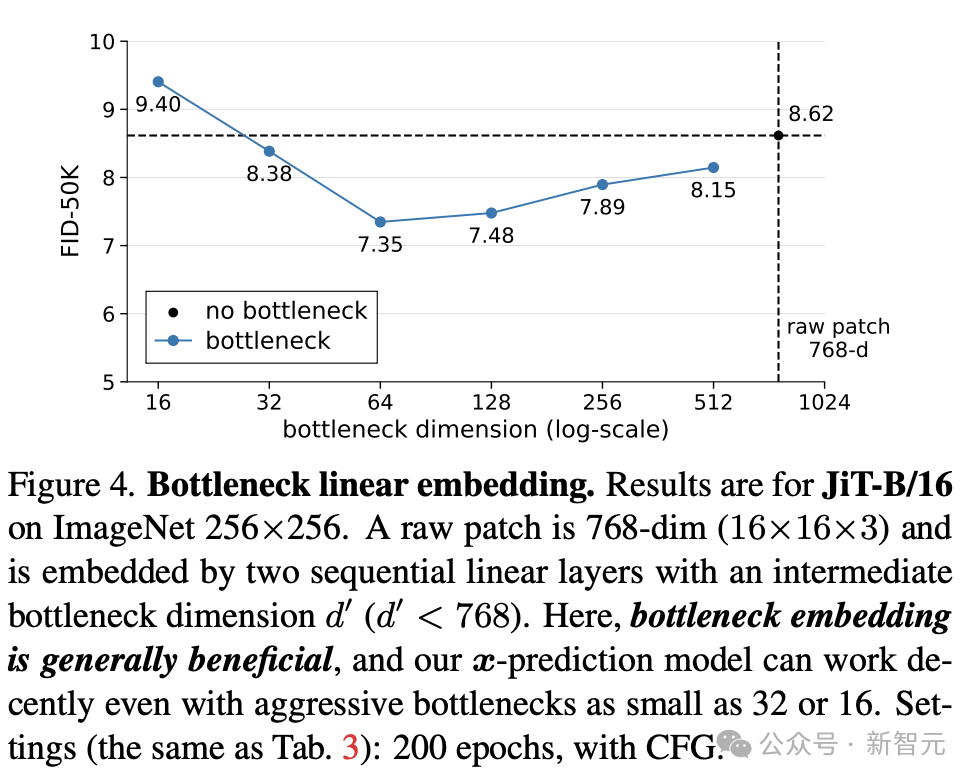
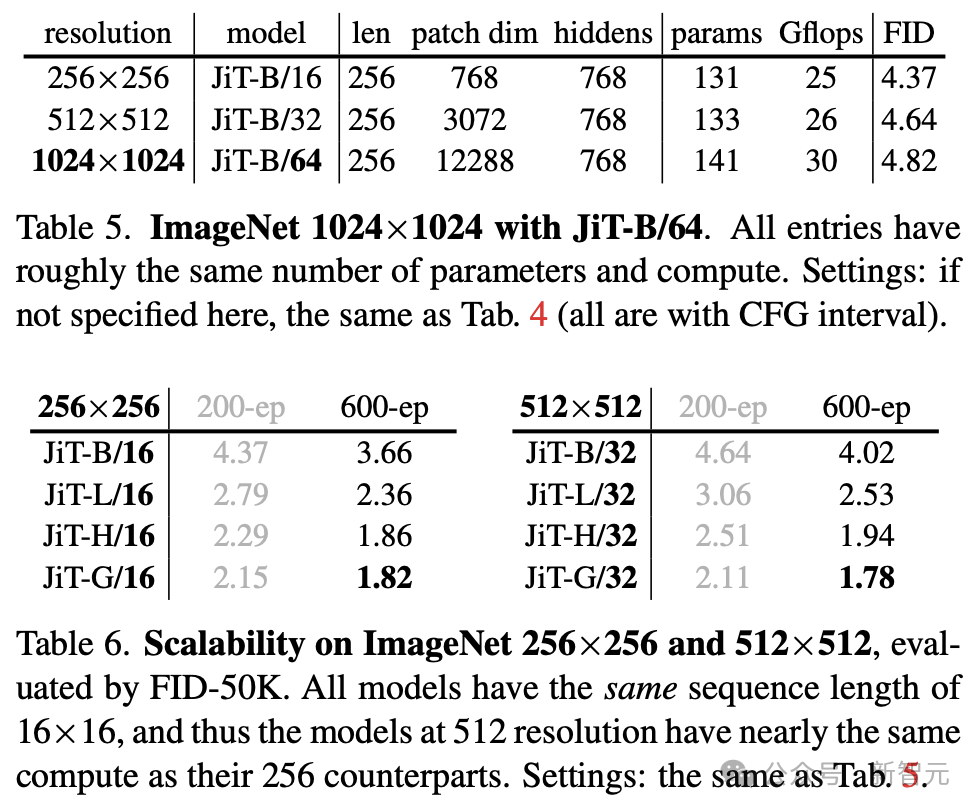
表5和表6显示,哪怕Patch维度高达3072或12288,只要采用x预测,标准宽度模型依然能稳定工作。
模型设计与输入维度可以部分解耦,仅需按比例调整噪声强度即可适配更大分辨率。
在前文分析基础上,作者最终选择使用「x预测 + v损失(v-loss)」作为训练方案,对应表1中的组合 (3)(a)。
优化目标函数如下:
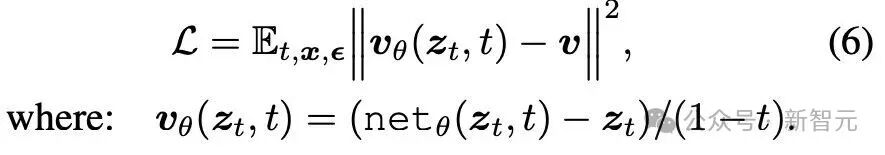
训练步骤(算法1):

采样步骤(算法2):

Transformer的关键优势在于其结构设计与任务解耦,因此可以从其他领域(如自然语言处理)借用先进模块来增强性能。
基础版(Baseline):使用SwiGLU和RMSNorm
加入旋转位置编码RoPE与qk-norm(注意力归一化)
加入 in-context类别Token嵌入:不像ViT仅添加1个CLS Token,默认使用 32个类别Token
这些优化组件均来自语言模型研究,但在视觉扩散任务中同样显著提升性能:

在高分辨率像素生成上,表5表明JiT无惧维度灾难; 表6则验证了JiT的可扩展性。
Just Image Transformers(JiT)证明了这样一个核心事实:只用原始像素+x预测+基础ViT结构,就足以实现顶尖性能。
相较其他方法,JiT具有以下独特优势:
结构极简: 无需预训练、辅助损失或感知模块;
通用高效: 利用标准Transformer即可训练;
稳定扩展: 分辨率、模型规模提升不影响性能;
资源友好: FLOPs 控制良好,无维度灾难;
可进化性强: 未来可接入更多语言模型模块进行微调提升。
最后,欣赏一下更多未筛选样例(un-curated examples)。




更多细节,请参考原文。

论文一作为黎天鸿。
目前,他是麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)的博士后研究员,导师是何恺明。
在此之前,他在麻省理工学院攻读博士和硕士。
他本科毕业于清华大学「姚班」,获计算机科学学士学位。
他的研究兴趣集中在表征学习、生成模型,以及这两者之间的协同作用。他致力于构建能够超越人类感知、理解和建模世界的智能视觉系统。
参考资料:
https://arxiv.org/abs/2511.13720
https://www.tianhongli.me/
文章来自于“新智元”,作者 “KingHZ”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
