# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
图像与视频重光照(Relighting)技术在计算机视觉与图形学中备受关注,尤其在电影、游戏及增强现实等领域应用广泛。当前,基于扩散模型的方法能够生成多样且可控的光照效果,但其优化过程通常依赖于语义空间,而语义上的相似性无法保证视觉空间中的物理合理性,导致生成结果常出现高光过曝、阴影错位、遮挡关系错误等不合理现象。
针对上述问题,我们提出了 UniLumos,一个统一的图像与视频重光照框架。本工作的主要创新点主要为:
实验表明,UniLumos 在显著提升物理一致性的同时,其重光照质量也达到了当前 SOTA 水平,并且在计算效率上比现有方法提升约 20 倍,实现了高质量与高效率的统一。





本演示所呈现内容均来源于真实用户的生成内容,仅用于展示模型的效果。
重光照(Relighting)是计算机视觉与图形学中的一项核心任务,旨在保持场景几何、材质等内容固有属性不变的前提下,对图像或视频中的光照效果进行自由编辑与调整。该技术在电影后期、游戏开发、虚拟现实(VR)与增强现实(AR)等领域具有重要应用价值,例如实现演员在不同光照虚拟场景中的无缝合成,或对游戏环境氛围进行实时调节。
近年来,基于扩散模型(Diffusion Models)的方法在重光照任务中展现出强大的生成潜力。然而,当前主流方法在生成质量与实用性之间仍面临两个根本性挑战:
现有方法通常在语义潜空间中进行优化,其目标是实现语义层面的相似性,而非物理层面的准确性。这种设计导致模型易产生物理不一致现象,具体表现为:
尽管已有研究(如 IC-Light、Light-A-Video 等)尝试引入几何先验或强化时序一致性,但它们要么缺乏视觉域(Visual Domain)中的显式物理监督,要么为保持一致性而牺牲了推理效率。
如何系统评估重光照结果的质量,是当前研究中的另一大瓶颈。现有通用图像评价指标(如 FID、LPIPS)主要关注整体感知相似度,却无法针对性衡量光照属性的准确性。例如,它们难以判断生成结果在「阴影方向是否正确」、「色温是否匹配」、「光照强度是否合理」等细粒度维度上的表现。这种评估体系的局限,严重制约了模型在光照可控性(Controllability)方面的迭代与优化。

图 1:各基线方法的定性对比。所有方法均以一段主体视频和一段文本光影描述作为输入,生成在指定光照条件下具有相应背景的视频。UniLumos 生成效果更自然且符合物理一致性。其中,基线方法 IC-Light(逐帧闪烁严重)和 Light-A-Video(光照方向错误、细节丢失)相比,UniLumos 展现出更准确的阴影对齐与更高的时序稳定性。
为应对上述挑战,我们提出 UniLumos——一个统一的图像与视频重光照框架。如下图所示,该框架基于视频生成模型 Wan 2.1 构建,能够依据用户指定的光照条件(如图像参考、视频片段或文本提示),在保持场景内容结构与时序一致性的前提下,实现对图像与视频的高质量重光照。
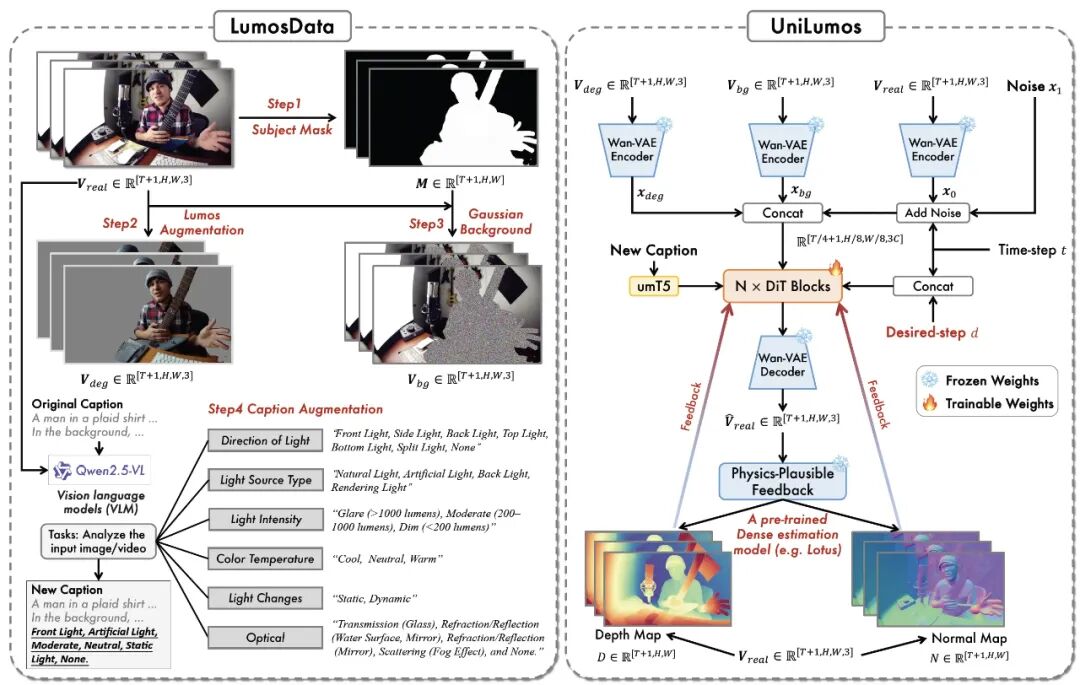
图 2:UniLumos 整体框架图。左侧为 LumosData(我们提出的数据构建流程),该流程包含四个阶段,用于从真实场景数据生成多样化的重光照样本对。右侧展示了 UniLumos 的架构,一个统一的图像与视频重光照框架,其设计目标是实现物理合理的光照控制。
我们的核心创新包括一个旨在增强物理一致性的几何反馈机制,以及一个用于细粒度效果评估的基准:
我们首先构建了一个高质量的光影训练数据集 LumosData,其流程如上图(左)所示。这是一个可扩展的数据集构建流程,用于从真实世界视频中提取高质量的重光照训练样本。



为平衡物理监督与训练效率,我们借鉴路径一致性调度思想,采用选择性优化策略。在每轮训练迭代中,我们按 80/20 比例划分批次,以避免全监督带来的过高开销,同时保留有效的学习信号。

我们在图像与视频重光照任务上进行了广泛实验,并与多种重光影 SOTA 方法进行了系统比较。
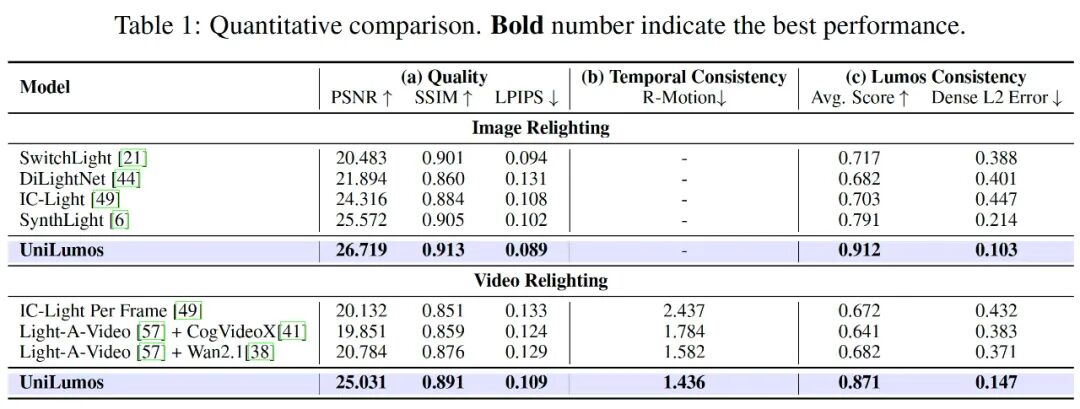
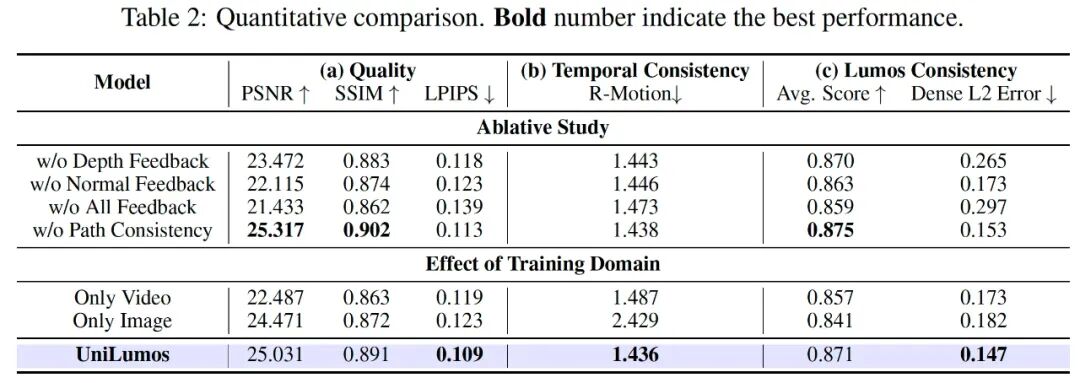
A. 定量结果:多项指标达到 SOTA
如下表所示,UniLumos 在所有关键指标上均取得最优性能:
B. LumosBench 细粒度可控性分析
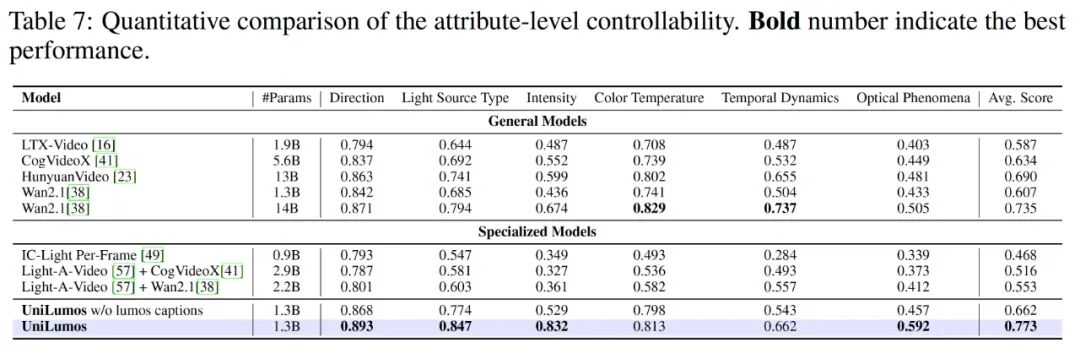
我们进一步使用 LumosBench 评估模型在六个光照维度上的可控性。具体而言,我们构建了一个包含 2000 条测试提示词的数据集,每条提示词由一个视频和一条结构化文本描述组成,旨在每次仅变动一个光照属性,同时保持其他变量恒定。这些提示词覆盖六大类别:方向、光源类型、强度、色温、时间动态与光学现象,每个类别下包含多个子类型(例如方向分为前/侧/后光)。
为衡量生成光照属性与预期属性之间的一致性,我们采用 Qwen2.5-VL 对重光照结果进行分析,并判断目标属性是否正确呈现。每个维度独立评分,最终的可控性得分为所有六个维度的平均值。
UniLumos (1.3B) 的平均可控性得分达 [此处缺失具体数值],显著高于其他专有重光照模型,如 IC-Light Per-Frame 与 Light-A-Video。其表现甚至优于参数量更大的通用视频生成模型(如 Wan2.1 14B),说明 UniLumos 在光照属性的细粒度控制方面具备显著优势。
C. 定性结果:视觉效果更真实、更稳定
我在基线方法对比和下图中提供了定性比较结果,充分展现了 UniLumos 在光照真实感、时序一致性与可控性方面的优势:

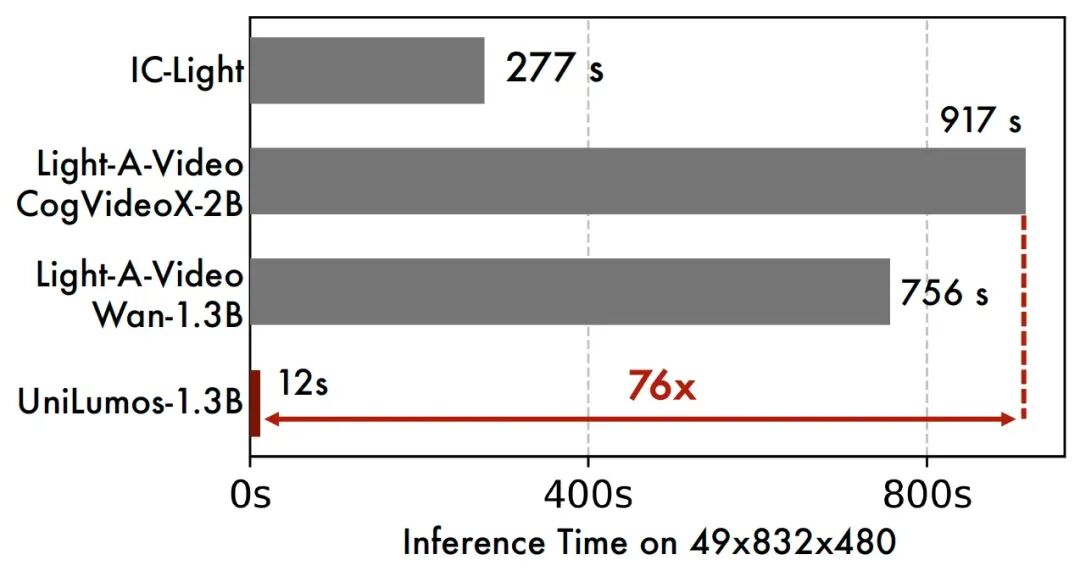
D. 效率对比:实现 20 倍加速
在生成 49 帧 480p 视频的任务中:UniLumos (1.3B) 仅需 12 秒;IC-Light(逐帧处理)需 277 秒;Light-A-Video (Wan-1.3B) 需 756 秒;Light-A-Video (CogVideoX-2B) 需 917 秒。UniLumos 在保持 SOTA 生成质量的同时,实现了显著的推理效率提升。
E. 消融实验:关键模块分析
如下表和图所示,我们通过消融研究验证各模块的贡献:

针对现有基于扩散模型的重光照方法在物理真实性差和评估维度单一等方面的挑战,我们提出了 UniLumos,一个统一的图像与视频重光照框架。该框架引入 RGB 空间的几何反馈,包括深度图与法线图作为监督信号,并将其与流匹配基模相结合,显著提升了光照效果的物理一致性。
为克服该反馈机制带来的计算效率瓶颈,我们采用路径一致性学习来增强物理监督的有效性,在实现当前最优生成质量的同时,带来了 20 倍的推理加速。
此外,为解决评估体系不完善的问题,我们构建了 LumosBench,一个基于视觉语言模型的光照可控性评估基准,实现了对重光照精度的自动化、可解释评估。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
