# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现如今,Agent 所需要执行的任务长度每几个月翻一番,长周期任务通常涉及数十次工具调用,这会带来成本和可靠性方面的问题。
那么,要如何解决?
deepagents 是 LangChain 推出的开源框架,通过规划、文件系统访问和子 agent 委托三大机制,可以对复杂长任务提供系统化解决方案。
本文将重点解读deepagents ,并给出它的部署、落地教程。
deepagents 是 LangChain 团队开源的 agent 框架项目,专门用于解决长周期任务的执行问题,其核心能力有三:
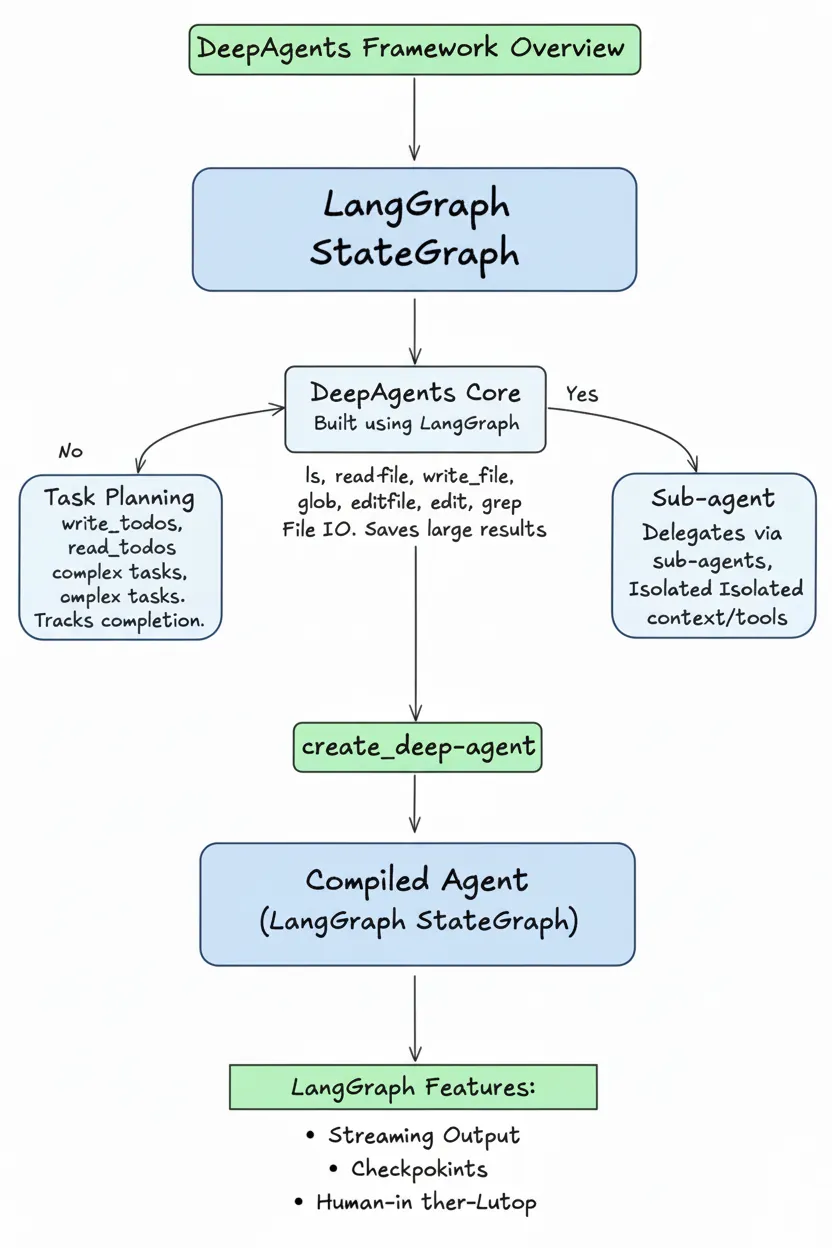
任务规划(Planning):使用内置 write_todos 和 read_todos 工具将复杂任务分解为结构化待办事项列表,agent 按列表执行并标记完成状态。
文件系统访问(Computer Access):提供 ls、read_file、write_file、edit_file、glob、grep 等工具,让 agent 能够读写文件、搜索文件内容。大型工具调用结果自动保存到文件,避免消耗上下文窗口。
子 agent 委托(Sub-agent Delegation):通过 task 工具将子任务委托给专门的子 agent 执行,每个子 agent 拥有独立的上下文窗口和工具集。
使用 create_deep_agent 创建的 agent 是编译后的 LangGraph StateGraph,可直接使用 LangGraph 的流式输出、检查点、人机交互等特性。
长周期任务面临的核心挑战是上下文窗口限制与成本控制之间的矛盾。传统 agent 将所有工具调用结果堆入上下文,导致 token 成本激增,同时模型在海量信息中逐渐失焦。
deepagents 的解决思路是重新设计信息流架构:引入文件系统作为上下文缓冲区,大型工具结果自动写入文件,agent 上下文中仅保留路径引用。配合自动摘要和提示缓存机制,系统显著降低成本的同时保持任务执行效率。
此外,deepagents 通过引入TodoListMiddleware 要求 agent 在执行前分解任务,将复杂指令转化为可验证的原子步骤,可以避免因随机探索导致的失败。
在此基础上,SubAgentMiddleware还会 为子任务创建独立执行环境,不同任务的上下文互不干扰。
PatchToolCallsMiddleware 则用于处理人机交互中断场景,确保任务恢复后能正确继续。这些机制组合使用,将复杂任务的完成率大幅提升。
架构扩展性则来自模块化中间件设计。deepagents 将 Claude Code 和 Manus 验证的架构模式开源,通过每个能力封装为独立组件,开发者可以根据需求替换或扩展任意中间件,从而构建适合特定领域的 agent 系统。例如将文件存储迁移到云端只需替换 backend 实现。
通用框架无法满足所有垂直领域的特定需求可以通过定制能力,deepagents 通过提供完整的可扩展机制,允许开发者根据业务场景定制 agent 。
开发者可以:集成专有工具和 API、定义领域特定的工作流程、控制 agent 行为符合业务规则、实现跨会话的知识积累和记忆管理。
以下是deepagents 支持的定制能力:
自定义 system prompt 会附加到中间件注入的默认指令之后,用于定义领域特定的工作流程和约束。
在使用中,我们要注意,应该在自定义 prompt 中包含:
不应该包含:
deepagents 支持添加自定义工具到内置工具集。工具定义遵循标准 Python 函数签名,docstring 作为工具描述。
from deepagents import create_deep_agent
def internet_search(query: str) -> str:
"""Run a web search"""
return tavily_client.search(query)
agent = create_deep_agent(tools=[internet_search])
MCP 工具集成通过 langchain-mcp-adapters 连接 Model Context Protocol 工具。
from langchain_mcp_adapters.client import MultiServerMCPClient
from deepagents import create_deep_agent
async def main():
mcp_client = MultiServerMCPClient(...)
mcp_tools = await mcp_client.get_tools()
agent = create_deep_agent(tools=mcp_tools)
async for chunk in agent.astream({"messages": [{"role": "user", "content": "..."}]}):
chunk["messages"][-1].pretty_print()
自定义 middleware 用于注入工具、修改提示或 hook agent 生命周期。
from langchain_core.tools import tool
from deepagents import create_deep_agent
from deepagents.middleware import AgentMiddleware
@tool
def get_weather(city: str) -> str:
"""Get the weather in a city."""
return f"The weather in {city} is sunny."
class WeatherMiddleware(AgentMiddleware):
tools = [get_weather]
agent = create_deep_agent(middleware=[WeatherMiddleware()])
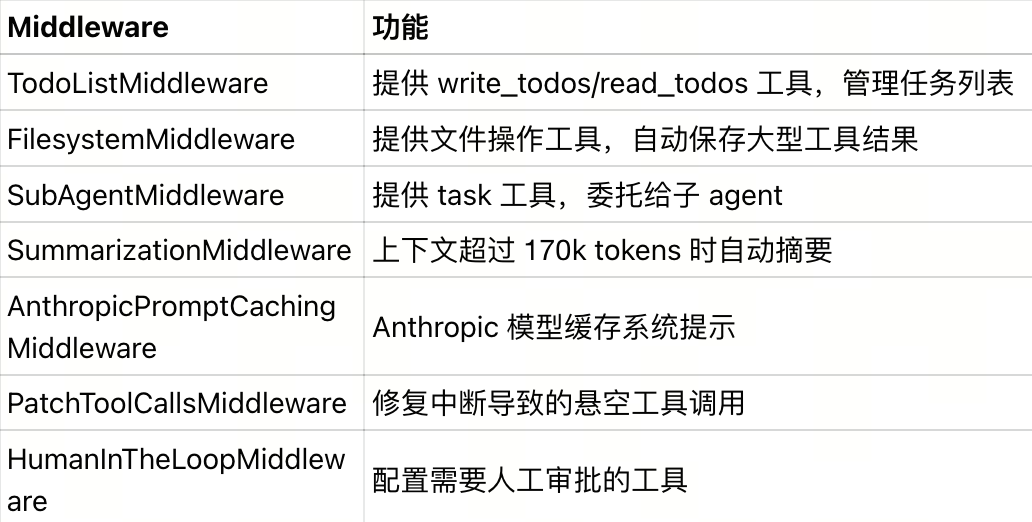
内置 middleware 功能清单:
主 agent 通过 task 工具将子任务委托给子 agent。子 agent 在隔离的上下文窗口中执行,拥有独立的工具集和系统提示。
from deepagents import create_deep_agent
research_subagent = {
"name": "research-agent",
"description": "Used to research in-depth questions",
"prompt": "You are an expert researcher",
"tools": [internet_search],
"model": "openai:gpt-4o", # Optional, defaults to main agent model
}
agent = create_deep_agent(subagents=[research_subagent])
对于复杂情况,可以传入预先构建的 LangGraph:
from deepagents import CompiledSubAgent, create_deep_agent
custom_graph = create_agent(model=..., tools=..., prompt=...)
agent = create_deep_agent(
subagents=[CompiledSubAgent(
name="data-analyzer",
description="Specialized agent for data analysis",
runnable=custom_graph
)]
)
通过 interrupt_on 参数配置需要人工审批的工具,agent 会暂停执行等待人工反馈。
from langchain_core.tools import tool
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
@tool
def delete_file(path: str) -> str:
"""Delete a file from the filesystem."""
return f"Deleted {path}"
agent = create_deep_agent(
tools=[delete_file],
interrupt_on={
"delete_file": {
"allowed_decisions": ["approve", "edit", "reject"]
}
},
checkpointer=MemorySaver()
)
配置不同的存储后端控制文件操作行为,支持 StateBackend(临时)、FilesystemBackend(本地磁盘)、
StoreBackend(持久化)、CompositeBackend(混合路由)。
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
agent = create_deep_agent(
backend=FilesystemBackend(root_dir="/path/to/project")
)
Agent 需要跨会话能力用于保存用户偏好配置、从多次对话中积累领域知识、记录反馈用于行为调整、维护跨会话的长期研究任务进度。
但是deepagents默认的 StateBackend 只支持单次会话存储,而持久化 backend 能够解决跨会话数据保留问题。
因此,我们需要引入Milvus 作为向量存储层,配合 StoreBackend 实现语义记忆的持久化。过程中,Agent 对话内容和重要工具结果会自动转换为 embedding 存储到 Milvus,每次任务执行时通过语义检索找回相关历史记忆。
Milvus 的计算存储分离架构能很好地支持 Agent 的高并发读写,可水平扩展至十亿级向量规模,同时支持高并发查询和流式数据实时更新,适合生产环境的 agent 记忆存储场景。
在这个方案中,deepagents 通过 CompositeBackend 实现混合存储,将不同路径路由到不同 backend:
/workspace/、/temp/ → StateBackend(临时文件)/memories/、/knowledge/ → StoreBackend + Milvus(持久化数据)使用 CompositeBackend可以将特定路径(如 /memories/)路由到持久化存储,实现跨会话记忆的具体配置代码请见下文的快速开始部分。
以下示例展示如何为 deepagents 添加持久化记忆。
pip install deepagents tavily-python langchain-milvus
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langchain_milvus.storage import MilvusStore
# from langgraph.store.memory import InMemoryStore # 仅测试用
# 配置 Milvus 存储
milvus_store = MilvusStore(
collection_name="agent_memories",
embedding_service=... # 这里需要 embedding,或者 MilvusStore 默认配置
)
backend = CompositeBackend(
default=StateBackend(),
routes={"/memories/": StoreBackend(store=InMemoryStore())}
)
from tavily import TavilyClient
import os
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
def internet_search(query: str, max_results: int = 5) -> str:
"""执行网络搜索"""
results = tavily_client.search(query, max_results=max_results)
return "
".join([f"{r['title']}: {r['content']}" for r in results["results"]])
agent = create_deep_agent(
tools=[internet_search],
system_prompt="你是研究专家,将重要发现写入 /memories/ 目录以便跨会话复用",
backend=backend
)
运行 agent
result = agent.invoke({
"messages": [{"role": "user", "content": "研究 Milvus 向量数据库的技术特点"}]
})
说明:
/memories/ 路径下的文件会持久化存储,跨会话可访问InMemoryStore() 可为 Milvus 适配器即可实现生产级语义检索/memories/,下次任务时检索相关内容deepagents 通过中间件提供以下内置工具:
任务管理工具(TodoListMiddleware):
write_todos:创建结构化待办事项列表,包含任务描述、优先级、依赖关系read_todos:读取当前待办事项状态,显示已完成和待处理的任务文件系统工具(FilesystemMiddleware):
ls:列出目录中的文件,需要绝对路径(以 / 开头)read_file:读取文件内容,支持分页参数(offset/limit)处理大文件write_file:创建新文件或覆盖现有文件edit_file:在文件中执行精确字符串替换glob:使用模式匹配查找文件,例如 **/*.py 查找所有 Python 文件grep:在文件中搜索文本模式execute:在沙箱环境中执行 shell 命令(需要 backend 实现 SandboxBackendProtocol)子 agent 委托工具(SubAgentMiddleware):
task:将子任务委托给专门的子 agent 执行,参数包括子 agent 名称和任务描述工具使用模式:
大型工具调用结果自动保存到文件。例如 internet_search 返回 100KB 内容时,FilesystemMiddleware 自动将结果写入 /tool_results/internet_search_1.txt,agent 上下文中只保留文件路径,避免消耗 token。
DeepAgents通过规划、文件系统、委托三大机制,可以将不可控的复杂agent流程转化为确定性的工作流。结合 Milvus 的向量检索能力,进一步赋予 Agent 跨会话的长期记忆。
对于开发者而言,这是一套真正打破 Token 限制、能从 Demo 走向 Production 的高可靠 Agent 架构方案。

Zilliz黄金写手:尹珉
文章来自于“Zilliz”,作者 “尹珉”。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
