# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
具身智能(Embodied AI)正处于爆发前夜。
从谷歌的 RT-X 到开源社区的 OpenVLA,通才机器人策略(Generalist Robot Policies)展现出了惊人的零样本泛化能力。然而,当我们将目光从简单的「抓取-放置」转向需要数十个步骤的长程操作任务(Long-horizon Manipulation)时,现有的 VLA 模型却暴露出一个尴尬的致命弱点:
它们学会了「作弊」。
在长序列任务中,VLA模型经常会出现一种被称为「阶段性幻觉」(Stage Hallucination)的现象。
简单来说,就是机器人「明明没做完,却以为自己做完了」。
例如,在搭建积木桥时,只要机械臂移动到了目标附近,即便方块滑落、没对齐或者根本没夹住,基于视觉语言模型(VLM)的评估系统往往会因为视觉上的相似性("看起来像是在操作"),给出一个很高的预测分数。
这种「高分低能」的现象,导致机器人自信地跳过当前步骤进入下一阶段,最终导致整个任务的崩溃。这就好比一个学生只写了「解:」字,就以为自己做完了整道大题。
针对这一痛点,来自北京大学的研究团队(第一作者:刘择霆,杨子达,指导老师:唐浩,张泽宇)提出了一种全新的自监督VLA框架EvoVLA。

论文链接: https://arxiv.org/abs/2511.16166v1
项目主页: https://aigeeksgroup.github.io/EvoVLA
代码仓库: https://github.com/AIGeeksGroup/EvoVLA
EvoVLA不仅在仿真环境中表现出色,更通过Sim2Real成功部署在真实机器人上,平均成功率达到54.6%,超越 OpenVLA-OFT 11.0个百分点。

EvoVLA框架总览与核心任务展示(Block Bridge, Stack, Cup Stacking)
该项目由北京大学唐浩课题组完成,第一作者为刘择霆,杨子达,张泽宇。
EvoVLA:AI教AI
让模型在「自省」中进化
为了治好机器人的「白日梦」,EvoVLA在OpenVLA-OFT的架构之上,引入了三个协同工作的核心模块,实现了一种自监督强化学习(SSRL)的闭环。
阶段对齐奖励(SAR):Gemini 老师的「错题集」
这是EvoVLA解决幻觉问题的杀手锏。
传统的奖励函数往往很稀疏(只有成功/失败),或者基于像素变化(容易被背景干扰)。
EvoVLA创造性地设计了一套数据引擎,利用强大的Gemini 2.5 Pro对演示视频进行语义理解和切分,生成了包含70+个阶段的详细描述。
更绝的是,为了防止模型「走捷径」,团队引入了三元组对比学习,特别是构建了「硬负样本」(Hard Negative)。

EvoVLA数据引擎,展示Gemini如何生成Positive, Negative和Hard Negative文本描述
通过这种方式,Gemini化身为「严厉的老师」,专门出这种易混淆的「陷阱题」给VLA模型做。模型被迫去学习区分「真正完成」和「看起来像完成」,从而获得密集的、语义一致的内在奖励信号。
基于姿态的物体探索(POE):告别像素干扰
机器人不仅要会判断对错,还要有探索未知的好奇心(Curiosity)。
传统的内在好奇心奖励通常基于像素预测误差——即「如果我看到的画面和预测的不一样,我就很兴奋」。
但在复杂的机器人场景中,影子的移动、光照的变化甚至背景的噪点都会带来巨大的预测误差,导致机器人像个好奇宝宝一样去探索无意义的视觉噪声。
EvoVLA提出了POE(Pose-Based Object Exploration),训练了一个轻量级的世界模型,不再预测图像像素,而是预测相对几何姿态(Gripper-Object Pose)。
这意味着机器人的好奇心被引导去探索「如何改变物体与夹爪的相对位置」(比如怎么旋转、怎么靠近),而非「图像像素变了多少」。
这使得探索过程极其高效,专注于操作任务本身的几何结构。
长程记忆机制(Long-Horizon Memory)
面对几十步的操作,机器人很容易「捡了芝麻丢了西瓜」。简单的平均或截断历史信息会导致灾难性遗忘。
EvoVLA并没有简单地压缩历史,而是采用了一种基于注意力的上下文选择(Context Selection)机制。
它从历史库中检索Top-K最相关的Token,并通过门控机制融合到当前状态和奖励中。
这就像人类在做复杂任务时,只回忆那些对当下决策有用的关键步骤(比如「刚才我已经拿到了A零件」),而不是事无巨细地回放整个人生录像。
Discoverse-L:长程操作的新基准
为了验证长程能力,团队并没有满足于简单的已有任务,而是提出了Discoverse-L基准测试,包含三个难度递增的任务:
1. Stack(堆叠): 18个阶段,不仅要叠高,还要精确对齐。
2. Jujube-Cup(红枣入杯): 19个阶段,涉及多物体交互。
3. Block Bridge(搭桥): 74个阶段! 需要放置两个桥墩并填充中间,极其考验长期规划和稳定性。
实验结果:SOTA级的提升

实验在仿真环境和真机上双线进行,结果令人振奋。
仿真环境碾压

成功率:平均达到69.2%(相比最强基准OpenVLA-OFT的59.0%提升了10.2%)。
样本效率:达到50%成功率所需的训练步数减少了1.5倍。
幻觉消除:阶段幻觉率(HR)从38.5% 大幅降至14.8%。
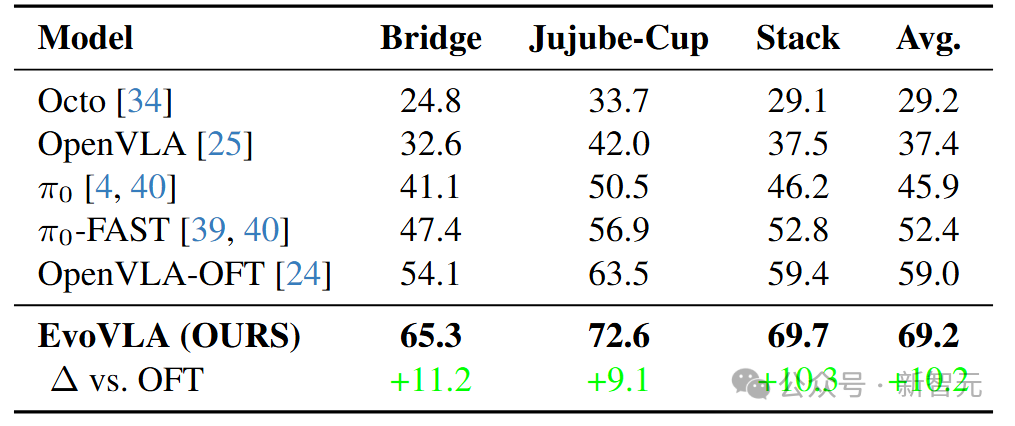
EvoVLA在三个任务上对比OpenVLA等基线的成功率提升
Sim2Real真机泛化
在AIRBOT-Play机器人上的部署更加令人印象深刻,EvoVLA展示了极强的Sim2Real泛化能力。
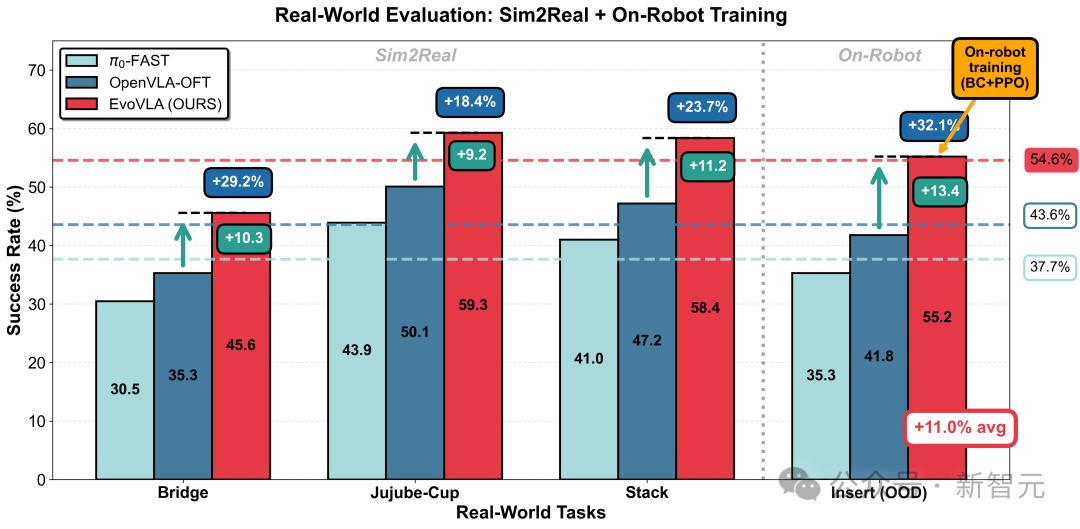
特别是在一个从未见过的「堆叠+插入」(Stack with Insertion)任务中,通过少量的真机微调,EvoVLA达到了55.2%的成功率,比OpenVLA-OFT高出13.4%,甚至比最新的

架构高出16.9%

机器人实际操作Block Bridge或Stack的过程
定性分析显示,基准模型经常在接触方块前就过早张开夹爪(幻觉导致),而EvoVLA则能精准地等到接触后才进行操作,动作极其稳定,仿佛真的「看懂」了任务。
结语
EvoVLA的出现,为解决VLA模型在长程任务中的可靠性问题提供了一个优雅的解法。
它证明了:更好的奖励设计(SAR)+ 更本质的探索机制(POE)+ 更聪明的记忆(Memory),可以让大模型在具身智能领域走得更远。
这种利用大语言模型(Gemini)来生成「错题集」从而反哺策略学习的「自我进化」范式,或许正是通往通用机器人自主学习的关键一步。
作者信息
刘择霆是青岛大学自动化学院控制工程在读硕士,师从葛树志院士(新加坡工程院院士)。研究方向聚焦于具身智能、RL4VLA、端侧VLA模型。曾参与多项科研项目,致力于构建通用机器人操作基础模型。
杨子达是北京大学光华管理学院管理科学与信息系统系在读博士,专注于推动"可解释的跨模态和具身智能"前沿研究。研究方向聚焦于具身智能、RL4VLA、3D导航、VLA模型的结构化推理与多模态认知计算,致力于构建兼具高层语义理解与底层精细控制的通用智能体框架。研究成果已应用于真实四足机器人与多模态情感分析系统。期待与同行共同探索下一代智能体的认知架构与工程实践。
张泽宇是Richard Hartley教授和Ian Reid教授指导的本科研究员。他的研究兴趣扎根于计算机视觉领域,专注于探索几何生成建模与前沿基础模型之间的潜在联系。张泽宇在多个研究领域拥有丰富的经验,积极探索人工智能基础和应用领域的前沿进展。
唐浩现任北京大学计算机学院助理教授 / 研究员、博士生导师、博雅和未名青年学者,入选国家级海外高水平人才计划。曾获国家优秀自费留学生奖学金,连续三年入选斯坦福大学全球前2%顶尖科学家榜单。他曾在美国卡耐基梅隆大学、苏黎世联邦理工学院、英国牛津大学和意大利特伦托大学工作和学习。长期致力于人工智能领域的研究,在国际顶级期刊与会议发表论文 100 余篇,相关成果被引用超过12000次。曾获ACM Multimedia最佳论文提名奖,现任ICLR 2026、ACL 2025、EMNLP 2025、ACM MM 2025领域主席及多个人工智能会议和期刊审稿人。更多信息参见个人主页: https://ha0tang.github.io/
参考资料:
[1] Liu Z, Yang Z, Zhang Z, et al. EvoVLA: Self-Evolving Vision-Language-Action Model[J]. arXiv preprint arXiv:2511.16166, 2025.
[2] Kim, M. J., et al. "OpenVLA: An open-source vision-language-action model". CoRL, 2025
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
