# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近研究发现,大模型在判断逻辑谬误时容易「想太多」,误报正常句子,但在确定有谬误后,其分类能力较强。研究人员构建了首个高质量英文逻辑谬误基准SMARTYPAT-BENCH,并开发了基于Prolog的逻辑谬误自动生成框架SMARTYPAT,为大模型逻辑能力评估提供新思路,可用于谬误识别、辩论教育等领域。
在大模型已经能写代码、写论文的2025年,它们到底能不能看穿人类日常话术里的逻辑坑?
最近,澳大利亚新南威尔士大学、复旦大学和卡内基梅隆大学组成的团队给出了一个系统答案:
他们从英文Reddit社区里挖出了一个原生版「弱智吧」,构建了首个高质量英文原生逻辑谬误基准SMARTYPAT-BENCH,并提出一个基于Prolog的逻辑谬误自动生成框架SMARTYPAT,论文已被AAAI收录。

参考资料:https://arxiv.org/abs/2504.12312
论文的结论是:推理模型在有没有谬误这件事上反而更容易想太多,误把正常句子当谬误,但一旦确定有谬误,推理模型在这是什么谬误的分类任务上又明显更强,大模型与Prolog两者配合能显著提高逻辑谬误数据的质量和可控性。
论文系统梳理了现有逻辑评测基准,并给它们分了四个维度。
NE:是否原生英文;
CQ:是否包含狡猾提问(Cunning Question),类似弱智吧风格;
RW:是否来自真实世界语料;
FL:是否有细粒度谬误标签。
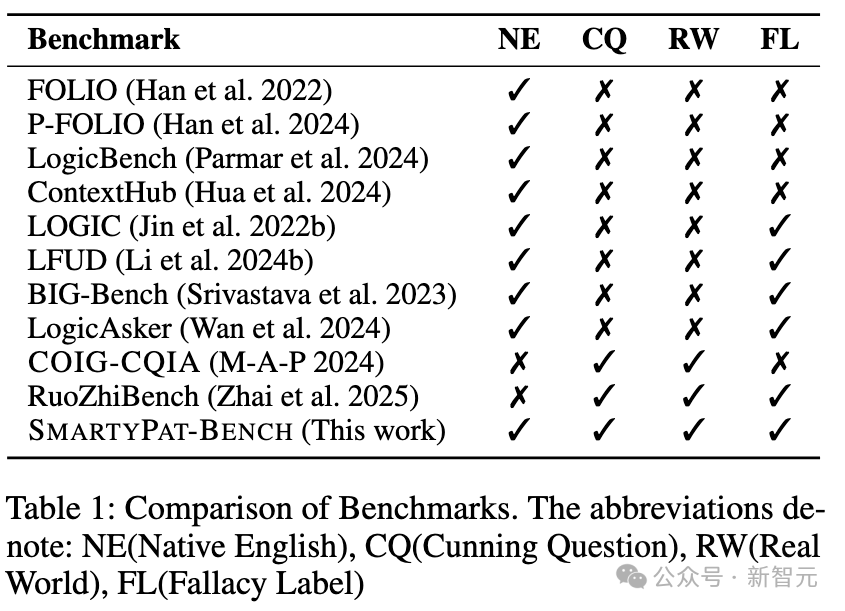
FOLIO、LogicBench等符号逻辑数据集:NE ✓,但 CQ / RW / FL 全 ✗,像「逻辑学课后习题」,形式严谨,却离自然语言很远;
LOGIC、LFUD、BIG-Bench等:会从试题或百科句子改写,句子自然度好一些,但情境单薄、谬误类型粗糙;
COIG-CQIA、RuoZhiBench:来自中文论坛「弱智吧」,有真实世界狡猾提问,但要么是中文,要么是翻译到英文后语境变形,而且多没有细粒度标签。
在对比表里,SMARTYPAT-BENCH是唯一NE / CQ / RW / FL全部打勾的基准——既是原生英文,又真来自英文版弱智吧,还带精细的谬误类型标注。
这次的SMARTYPAT-BENCH,灵感来自Reddit上著名的r/ShittyAskScience板块,里面充斥着类似这样的提问。
If smoking is so bad for you, how come it cures salmon? (既然吸烟这么有害,为什么还能治好三文鱼?——cure 兼具(治疗 / 腌制)双关)
Why do meteors always land in craters? (为什么陨石总是掉在坑里?)
研究团队的构建过程非常耗时:
先通过 Arctic Shift 数据集抓取到目标子版块的全部历史内容,共 251,052 条帖子;
再按点赞数排序,取历史前 2500 条高互动帖子做候选;
5位作者人工清洗、筛选出真正「逻辑有毒」的句子,最终留下 502 条;
结合两本经典逻辑谬误教材,对每条句子打上可多选的细粒度逻辑谬误标签,最后形成 14 类谬误类型 的标注体系。
SMARTYPAT-BENCH 中最常见的,是三大类型:
这三类加起来占了79.7%,而像Improper Transposition(换质不换位)、Fallacy of Composition(合成谬误)等少数类,加起来还不到2%
这也暴露出一个现实:真实世界中,逻辑错误高度长尾,人工构建平衡数据集又极其耗时。
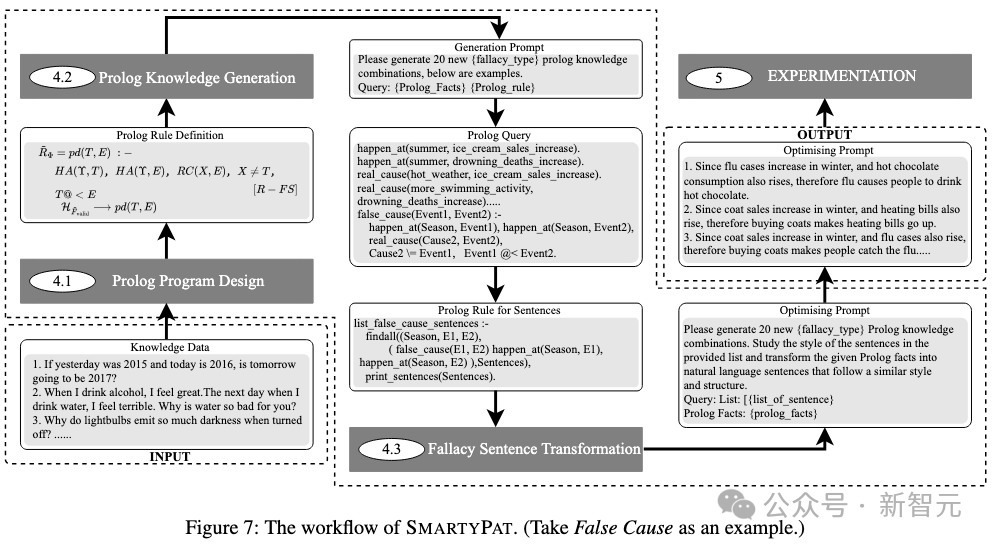
为解决数据集规模受限和标签不平衡问题,研究团队开发了SmartPat生成框架,见下图,采用「符号逻辑+神经生成」的混合方法:
首先,将原始数据转化为一阶逻辑形式,如「since A and B, therefore C」的结构化表达。
接着,在元层面对逻辑谬误进行建模,设计出可复用的Prolog谓词,如has_effect/3、valid_accumulate/3等,为每种谬误类型构建形式化规则。
然后,让大模型在谓词空间中批量生成「事件-条件-结果」的事实组合,由Prolog引擎执行查询,仅保留真正触发逻辑谬误规则的组合。
最后,通过逻辑验证的事实组合被交还给大模型,转化为流畅自然的语言表达。
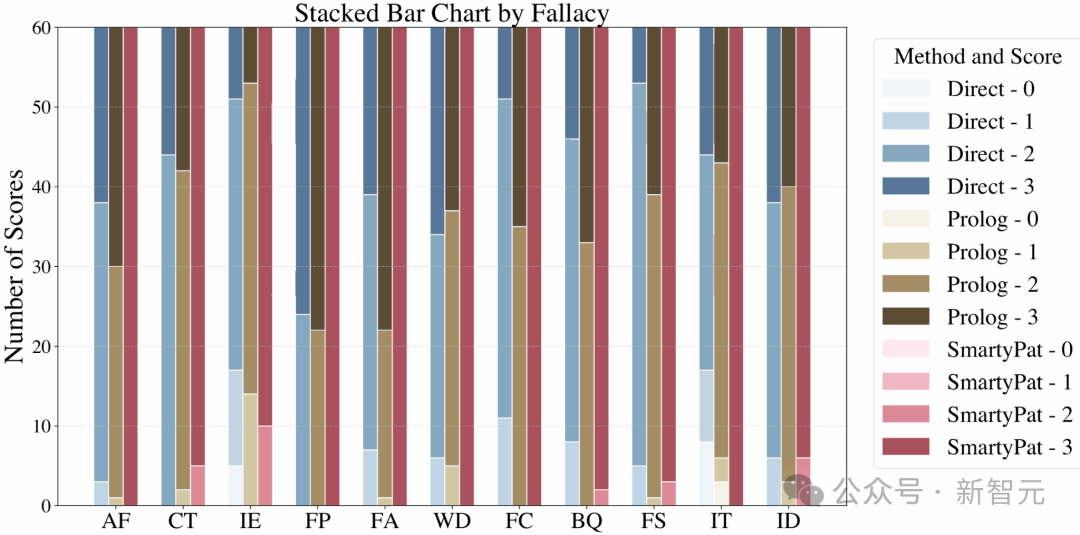
研究设置了两个基线方法进行对比:
FallacyGen-Direct,仅让大模型直接生成谬误语句
FallacyGen-Prolog,让大模型同时生成Prolog代码和自然语句
实验结果显示,SmartPat的「人工规则+LLM生成+Prolog校验」组合在大多数谬误类型上都能产生更高质量的样本,通过了基于大模型评分和人工交叉验证的评估。
同时,作者还用OpenAI的text-embedding-3-large算了语义相似度,证明增广数据与原始Reddit数据之间的平均余弦相似度只有0.16左右,真正带来新的数据。
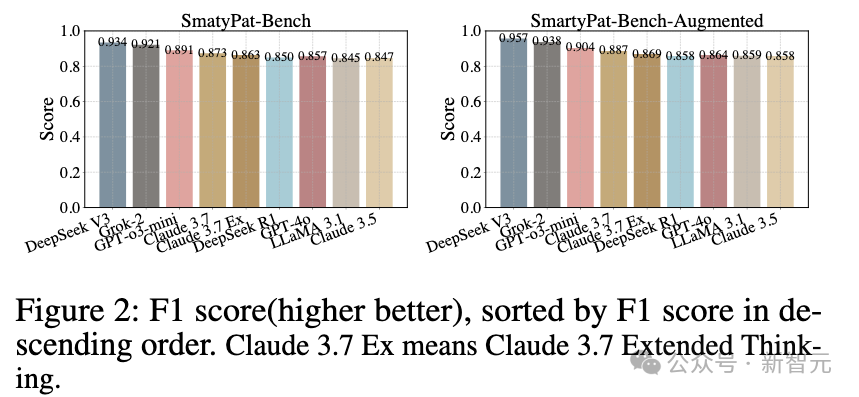
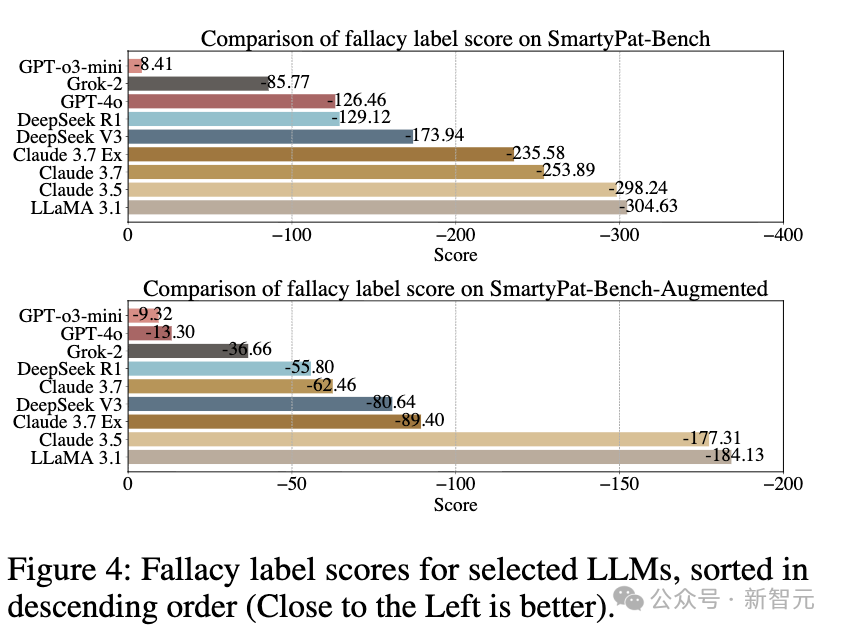
研究团队对9个主流大模型进行了全面评测,包括GPT-4o、GPT-o3-mini、Claude系列、DeepSeek系列、LLaMA 3.1 405B和Grok-2
在谬误检测任务中(有没有逻辑谬误(是 / 否)),结果出人意料:非推理模型(如DeepSeek V3、Grok-2)的F1分数更稳定,而推理模型(如GPT-o3-mini、Claude 3.7 Extended Thinking)在良性样本上误报率明显偏高,表现出「过度思考」的倾向。
然而在谬误分类任务中(「是哪些谬误?(可多选)」),局面反转:推理模型表现明显更强,GPT-o3-mini优于GPT-4o,DeepSeek R1超过V3。
所有模型在SmartPat生成的合成数据上分类得分都显著高于原始Reddit数据,因为前者结构更清晰、谬误更典型。
谬误种类难度谱:表面因果、简单类比最好识别,上下文相关最难
从不同谬误类型来看,作者还观察到有趣的「难度梯度」。
False Cause、False Analogy:大多数模型识别率最高;因为这类谬误往往有直观的因果 / 类比错误,比较显眼;
Contextomy、Improper Transposition、Improper Distribution or Addition等:需要理解上下文、省略信息以及更细腻的逻辑结构,模型识别准确率普遍较低。
这说明当谬误「贴着表面语义」时,LLM 已经能拿到不错的成绩;一旦谬误依赖上下文、语境和隐含前提,模型就开始力不从心。
这项研究不仅提供了高质量的逻辑谬误数据集,更展示了一种「符号逻辑+神经生成」的混合方法,适用于需要可控、可验证文本生成的场景,包括:
大模型逻辑能力评测与基准构建、谬误识别与抵抗训练、辩论与批判性思维教育工具开发。
该工作为大模型的逻辑推理能力评估提供了新的思路和工具。
参考资料:
https://arxiv.org/abs/2504.12312
文章来自于“新智元”,作者 “LRST”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
