# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025年,AI大模型的竞争焦点正在发生根本性转移。
预训练的边际收益在下降,数据的红利在消退,整个行业都在寻找下一个增长引擎。答案越来越清晰:强化学习(RL)。
DeepSeek V3.2的技术报告里有个细节很值得玩味——RL训练的算力投入已经超过预训练的10%,而且性能曲线还在往上走。OpenAI的o系列、Claude的推理能力、Gemini的多模态表现,背后都站着大规模RL。
强化学习正在从“锦上添花”变成大模型进化的主战场。
但这里有一个卡脖子的问题:在万亿参数模型上跑RL,成本高得离谱。
传统方法需要上千张顶级GPU,训练周期动辄数周,绝大多数团队根本玩不起。这不是技术问题,这是资源垄断——只有少数几家公司能负担得起这种规模的RL训练。
现在,这个局面被打破了。
来自Macaron AI背后的研究团队Mind Lab给出了他们的答案:全球首个在1T参数模型上实现的LoRA高效强化学习训练,GPU消耗直降90%。
这不是工程优化的小胜利,而是训练范式的根本性转变。NVIDIA Megatron-Bridge和Seed verl已官方合并这套技术,代码全部开源。

更硬核的是,这支10人研究团队的成员来自OpenAI、DeepMind、Seed,发表200+篇论文,累计被引用30,000+次。
先说说背景。
最近几个月,万亿参数级的推理模型开始扎堆出现——Kimi-K2、Ring-1T相继登场,在多个推理基准上已经追平甚至超越闭源模型。
但预训练只是起点。看看DeepSeek V3.2就知道了——RL训练的算力投入已经超过预训练的10%,性能曲线还没见顶。强化学习正在从“锦上添花”变成大模型进化的主战场,成为未来一年的兵家必争之地。
要让万亿参数模型真正适配Agent任务,RL不再是可选项:
问题在于成本。
在万亿参数模型上跑全参数RL,对绝大多数团队来说根本不现实——就算你能拿到开源的模型权重,训练开销也能把你劝退。
Mind Lab给出的解法是:用LoRA做参数高效适配,配合专门为万亿参数MoE模型设计的混合并行引擎,把RL的计算量砍到只剩十分之一,同时性能不打折。
Mind Lab直接拿Kimi K2开刀做了验证。
先看模型配置:
再看训练配置:
关键结论有三条:
第一,成本大幅下降。
在Kimi K2上跑LoRA RL,GPU消耗只有传统全参数RL的10%左右。
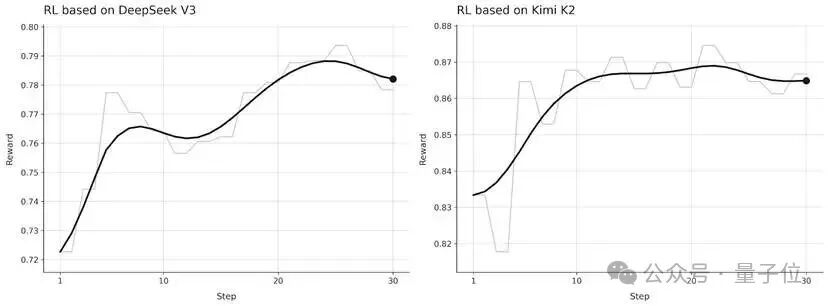
第二,训练稳定收敛。
学习曲线显示,reward和任务成功率随着训练步数平稳提升,没有出现灾难性崩溃。
第三,通用能力保住了。
在hold-out基准上的评测表明,LoRA RL在提升特定任务表现的同时,保留了基座模型的通用能力。
你可能会问:LoRA不是早就有了吗?为什么在万亿参数MoE上跑就这么难?
问题出在MoE的架构特性上。现代万亿参数推理模型基本都是MoE Transformer,几百个专家、大量的all-to-all通信、dense和expert参数混杂在一起。
在这个设定下,简单的数据并行+LoRA方案会被三个问题卡死:
问题一:路由不均衡。
几百个专家的token路由极度不均匀,拖慢吞吐、放大RL更新的方差。
问题二:通信压力爆炸。
LoRA的适配器权重需要频繁跨设备收集,all-gather开销巨大,动不动就OOM。
问题三:并行布局太复杂。
rollout和training要在同一套硬件上紧耦合运行,简单的并行策略根本带不动。
Mind Lab的解法是设计了一套混合协同并行引擎,把tensor、pipeline、expert、sequence四种并行方式统一调度:
核心设计思想是:把并行当成可调度的资源,而不是固定的布局。
LoRA的配置也有讲究:
最终效果:LoRA的参数量和通信量大约是全参数RL的10%,但RL信号的传导路径并没有被阉割。
还有一个坑:RL训练里,rollout(生成轨迹)和training(更新参数)通常用不同的后端。
推理端可能跑在一个独立的、为serving优化的引擎上;训练端可能跑在一个重型的、需要频繁同步的分片后端上。
这就导致了分布不匹配——生成轨迹的策略和更新参数的策略不是同一个东西。
在万亿参数规模下,这个问题会被急剧放大:
Mind Lab的解法是引入了截断重要性采样比率(truncated importance ratio),显式修正这种不匹配,同时不引入不可接受的方差。具体的数学公式涉及vllm和megatron两个后端的策略比值,通过截断操作把梯度权重控制在合理范围内。
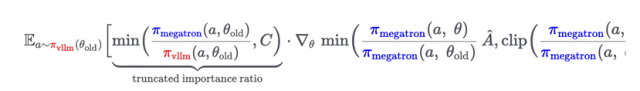
整套方案已经集成到开源训练栈里:verl负责RL训练循环、rollout编排和reward聚合;Megatron-Bridge把verl接入Megatron风格的MoE后端,统一暴露四种并行方式。
代码已合并至NVIDIA Megatron-Bridge和Volcengine verl。
一个自然的问题是:为什么非要在超大模型上做LoRA RL,而不是直接用小模型跑全量RL呢?
Mind Lab做了一组对照实验,在Math数据集上训练三个策略:
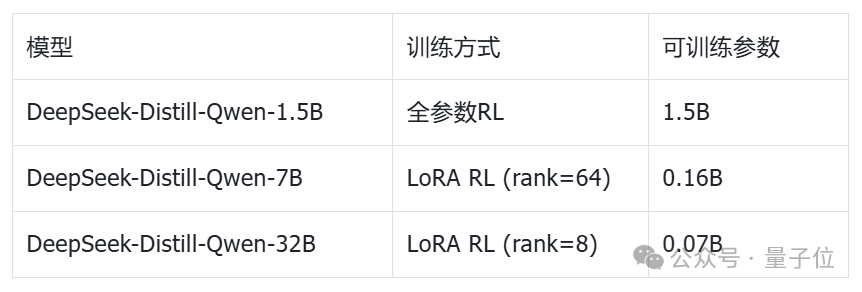
三个模型只在Math上训练,然后同时在AIME 2025(域内)和GPQA(域外)上评测。
为了公平比较,团队控制了:
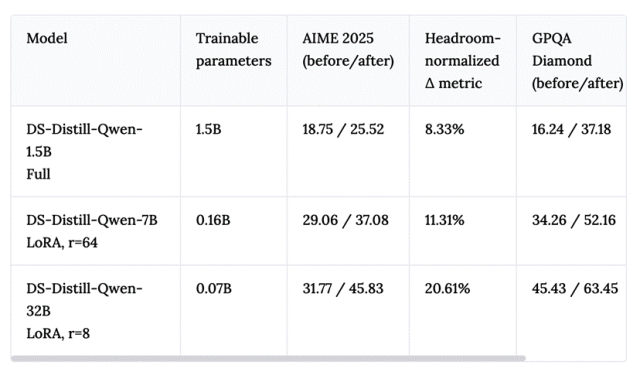
为了剔除大模型起点更高的优势,团队用了一个“headroom-normalized”的指标:相对于起点分数到满分之间的提升比例。
结论相当清晰:
32B模型+rank=8的LoRA,在相同RL计算预算下,headroom-normalized增益最大。
而且在域外任务GPQA上,32B+LoRA的迁移效果也是最好的——更强的先验带来了更好的泛化。
简单说:“大先验+小LoRA”比“小模型全参数RL”更划算。
背后的逻辑是:RL本质上是先验受限的(prior-limited)。如果基座模型本身生成不出高质量轨迹,RL就没有什么有用的信号可以放大。大模型已经编码了丰富的推理、工具使用和人类交互模式,RL可以在这些基础上精修,而不是从头造轮子。
除了RL训练框架,Mind Lab还搞了一套全新的记忆机制——Memory Diffusion。
传统的Agent记忆方案有两类:
第一类是推理式记忆。每轮对话后,模型主动总结记忆片段。问题是反复总结计算开销大,而且关键细节容易在多轮迭代中丢失。
第二类是工具式记忆。把记忆存在外部数据库里,需要时检索回来插入上下文。问题是检索和重整合的过程容易丢失微妙的语境。
Mind Lab的思路完全不同:把轨迹本身当作记忆,通过反复的“遮蔽-分配-重填”操作来动态压缩。
三步走:
这个设计的灵感来自人类的遗忘机制。
人脑每时每刻都在高速丢弃无关信息——开车上班时,你会瞬间忘掉路过的广告牌,只记住目的地和路线。Memory Diffusion让AI也学会了这种“智慧地遗忘”:不追求记住一切,而是只保留真正有意义的经验。
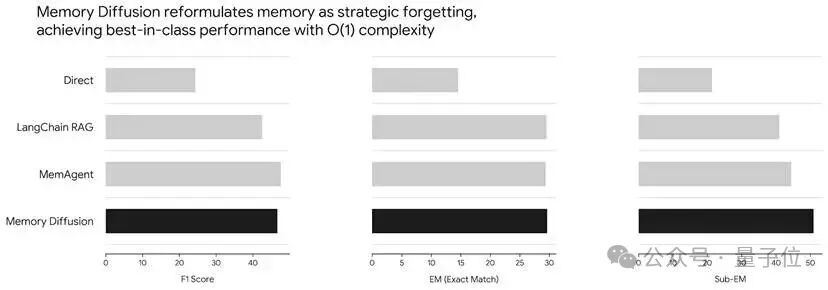
关键是,这套方法的时间复杂度是O(1),不改变模型架构,严格遵守上下文预算。
在Locomo基准测试上,Memory Diffusion达到了93%的准确率,刷新了SOTA。
Andrej Karpathy说过一句话:
“Human thought naively feels a bit more like autoregression but it’s hard to say that there aren’t more diffusion-like components in some latent space of thought.”
Mind Lab正在把这个直觉变成工程现实——用扩散语言模型来做记忆更新本身,让“智慧遗忘”成为模型原生的能力。
Research-Product Co-Design:产品就是最好的RL环境Mind Lab还提出了一个核心理念:研产共设(Research-Product Co-Design)。
为什么?因为真实产品能提供合成环境给不了的东西:
产品本质上就是天然的RL环境。它持续生成接地的reward信号——编辑、使用模式、任务完成率、留存率,甚至用户的流失,都在告诉你系统到底有没有在帮忙。
Mind Lab在前端代码生成任务上做过一个实验:用产品级的人类反馈训练为什么非要在超大模型上做LoRA RL,而不是直接用小模型跑全量RL呢?,然后用它来优化策略。
结果显示:

而且,静态环境下的reward model容易被“hack”——模型找到满足proxy但违背真实意图的病态策略后,没有自动纠错机制。
但在真实产品里,偏好数据是源源不断的。用户会交互、会反对、会覆盖系统的输出。这种持续的反馈流让reward model能不断更新,不容易过拟合到退化策略上,行为也更贴近真实的用户价值。
底层技术的突破不是停留在论文里的数字。
基于这次模型升级,Macaron AI的Mini-app生成速度从20分钟直接干到2分钟,提升10倍。同时上线了群聊协作和Daily Spark等新功能。
这就是“研产共设”的真实成果——更高效的模型训练,带来更快的推理速度,最终转化为用户可感知的体验升级。
在最新的访谈中,Ilya表示:我们正在结束一个以「算力规模化」(Scaling)为核心的时代,重新回到一个以「基础研究」(Research)为驱动的时代。
Ilya Sutskever说了一句让整个行业都在琢磨的话:
Pre-training as we know it will end. What comes next is superintelligence: agentic, reasons, understands and is self aware.
预训练时代正在走向终结。那么,下一个时代是什么?
Mind Lab的答案是:经验智能(Experiential Intelligence)时代。
这可能是全球第一个专门为“后预训练时代”而生的研究实验室。
他们的核心命题只有一个:
他们的核心主张是:预训练时代构建了“大脑”,但下一个时代属于“心智”。大脑记住了互联网上的海量知识,但在面对真实世界的复杂性时依然捉襟见肘。心智不只是存储的知识——它是能通过交互不断更新的世界模型、能从反馈中学习的内部机制、能动态感知任务的记忆系统。
简单说:大脑负责记忆,心智负责在世界中活着。
而这次万亿参数LoRA-RL的突破,正是他们为这个新时代打下的第一块基石——当RL训练的门槛被砍掉90%,更多团队就能进入这个赛道,整个行业的进化速度都会加快。
团队阵容相当硬核:
Slogan也很有意思:
Real intelligence learns from real experience.真正的智能源于真实的体验。
他们研究的三个方向:
1. 基础设施:打通产品到Agent的闭环,更快更便宜的训练方案
2. 超越预训练:持续学习、记忆机制、推理与反思
3. 开放与可复现:可被复现的重要实验,寻找下一个scaling law
Mind Lab的差异化在于:他们不是产品公司,不会永远追着最新最强的模型跑;他们以研究智能为目标,不断提高模型学习的效率。也许当前模型不是最好的产品选择,但好算法的斜率更大,长期会成为那个更好的选择。
用他们自己的话说:
From training to becoming, from static intelligence to living intelligence.
从训练到成为,从静态智能到活的智能。
项目主页:
Mind Lab Blog: https://macaron.im/mindlab/
开源地址:
https://github.com/volcengine/verl/pull/4063
https://github.com/NVIDIA-NeMo/Megatron-Bridge/pull/1310
https://github.com/NVIDIA-NeMo/Megatron-Bridge/pull/1380
文章来自于“量子位”,作者 “Mind Lab团队”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
