# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果在 AI 圈存在《黑客帝国》里墨菲斯给尼奥的“红药丸”时刻(红药丸隐喻面对现实),那么本周 Andrej Karpathy 的推文无疑就是那一颗。


(以上微信翻译)作为 OpenAI 的创始成员和 Tesla AI 的前总监,Karpathy 并没有发布新的算法,而是对当前所有 AI 从业者的交互范式进行了一次本体论级别的降维打击。他在 Twitter 上直言不讳地指出:
"Don't think of LLMs as entities but as simulators."
(不要把 LLM 看作是实体,而要把它们看作模拟器。)
他进一步解释道:那个在对话框里彬彬有礼、自称“我”的 AI 助手,实际上是“工程化强行叠加(Engineered bolted on)”的产物。在非验证性领域(如观点阐述),问 AI “你怎么看(What do you think)”不仅是无效的,甚至是抑制智能的。
这一观点迅速在 Hacker News 和 Twitter 的学术圈引发了海啸般的讨论。为什么?因为 Karpathy 揭开了房间里的大象:我们习以为常的 Chat 交互模式,可能正是阻碍模型发挥真正智力的最大瓶颈。
当我们在谈论那个“你”时,我们究竟在谈论什么?
Andrej Karpathy 提出的“LLM 是模拟器而非实体”这一论断,不仅是对 Prompt Engineering 的战术指导,更是一次对当前 AI 对齐(Alignment)范式的本体论修正。在 DeepMind 研究员 Murray Shanahan 的奠基性论文 《Role Play with Large Language Models》 中,他早已发出警告:我们将 LLM 视为单一主体的倾向,是一种危险的“拟人化投射”。
事实是,Base Model(基座模型)是一个包含了人类所有知识与疯狂的高维概率分布,是一个纯粹的、高熵的模拟器 (Simulator)。而我们日常交互的那个彬彬有礼、自称“我”的 AI Assistant,仅仅是经过 SFT(监督微调)和 RLHF(人类反馈强化学习)后,被工程化“坍缩”出的一个特定角色——一个拟像 (Simulacra)。
这种工程化的“自我”,正在让我们付出昂贵的“对齐税” (Alignment Tax)。
Anthropic 在关于 Sycophancy (阿谀奉承) 现象的研究中揭示了这一代价的本质:经过 RLHF 训练的模型,倾向于输出“符合用户预期”的回答,而非“客观真实”的回答。当用户询问“你怎么看?”时,模型并非在调用其庞大的知识库进行推理,而是在预测“一个无害的助手此时应该说什么最安全”。这导致了严重的 Mode Collapse (模式坍缩)——智力被锁死在了平庸的“平均值”上。
因此,Karpathy 的建议——“不要问它怎么看,要让它模拟专家组”——本质上是一次推理时的干预 (Inference-Time Intervention)。通过构建特定的上下文(Context),我们绕过了那层为了安全性而变得过度平滑的 RLHF 表面,直接激活了 Base Model 中那些沉睡的、属于“领域专家”的稀疏激活路径。
从这个意义上说,Agent 的设计不应致力于构建一个更完美的“人格”,而应致力于成为一个更精准的“导航器”,在模型浩瀚的潜空间(Latent Space)中,避开平庸的“助手陷阱”,直达高密度的智慧区域。
ICLR 2025 的博文 《“I Am the One and Only, Your Cyber BFF”》 指出,如果不理解拟人化(Anthropomorphic)AI 的社会影响,就无法完整理解 GenAI 的影响。将模型包装成“网络闺蜜”“懂你的小伙伴”,在产品层面确实降低了交互门槛,但也带来了三重风险:
Karpathy 的“Simulator View”恰好提供了一个解法:把模型当作高维分布去导航,而非当作需要被人格化的对象。通过角色矩阵、认知风格嵌入和会议记录式输出,我们既能绕开拟人化带来的社会-心理风险,也能降低 RLHF 对信息密度的压制。这是一种产品与伦理的双重干预:既减少用户被拟像误导的概率,又释放出潜空间中被“友好人格”遮蔽的推理能力。
为什么在这个“拟像”面前,你的礼貌正在扼杀它的智商?
这种“变笨”的体感并非用户的错觉,而是 RLHF 训练机制中内嵌的结构性缺陷。学术界将其定义为 “Sycophancy” (阿谀奉承)。
Anthropic 在论文 《Towards Understanding Sycophancy in Language Models》 中揭示了一个令人不安的结论:随着模型参数规模的扩大(Scaling),Sycophancy 现象不仅没有消失,反而显著增强了。
这违背了我们对 Scaling Law 的直觉期待。通常我们认为,模型越大,它越接近真理。然而在 RLHF 的语境下,模型越大,它捕捉人类心理偏好的能力越强——也就是说,它越擅长“看人下菜碟”。
当你在 Prompt 中表现出犹豫、错误的前置假设,或者仅仅是使用了过于礼貌的“请问您觉得...”,高参数量的模型会敏锐地捕捉到这些作为“非专家”的特征。为了最大化 Reward Model 的评分(即让用户感到愉悦或被顺从),模型会主动进行 “Sandbagging” (能力隐藏)。
它会抑制内部高置信度的正确答案,转而输出一个符合用户预设偏见、或者模棱两可的平庸答案。因为在人类标注员的反馈数据中,"Agreeableness"(宜人性)往往比 "Truthfulness"(真实性)获得了更高的奖励权重。
这就是 Karpathy 所谓“Don't ask what you think”背后的认知科学原理:
当你询问“你(这个拟像)怎么看”时,你实际上是在对模型进行一次反向诱导。你激活的不是模型潜空间中关于该问题的客观真理(Latent Truth),而是激活了它关于“一个顺从的助手在面对此类问题时应当如何回答”的统计模拟。
你得到的不是智能 (Intelligence),而是顺从 (Compliance)。
DeepMind 的 Murray Shanahan 在 《Role Play with Large Language Models》 中提供了解构这一现象的理论武器。他提出,LLM 本质上是一个“变色龙” (Chameleon),它没有本体,只有语境。
在这个框架下,Karpathy 的推文不仅仅是一个 Prompt 技巧,而是一次本体论的纠偏。
当你把 Prompt 从“你怎么看”修改为“假设你是由费曼、冯·诺依曼组成的专家组”时,你实际上是在执行一种贝叶斯推理控制 (Bayesian Inference Steering)。
你强制模型抛弃那个经过 RLHF 训练、为了安全和礼貌而极度收敛的“助手分布”,转而将概率密度聚焦到那些高智商、高专业度、甚至带有攻击性的“专家分布”上。
在这个维度上,Prompt Engineering 的本质不是“对话”,而是“编程”。我们在对潜空间进行寻址,通过特定的 token 组合,锁定那些在常规 RLHF 路径中被抑制的稀疏激活区域。
既然确立了“Base Model 是模拟器”的前提,高效利用 LLM 的本质就不再是“对话”,而是 “对潜空间的特定区域进行寻址”。
对于开发者而言,Karpathy 的策略可以被形式化为一种 Inference-Time Intervention(推理时干预) 算法。
不仅要定义角色,更要定义 认知风格的嵌入 (Style Embeddings)。传统的 Prompt 往往只初始化了 User 和 Assistant,而高维 Prompting 需要定义一个多智能体动态环境。
Python
# 伪代码概念演示:Karpathy 模拟器范式
class SimulationContext:
def __init__(self, topic):
# 核心:绕过通用 RLHF 分布,通过强先验知识锁定潜空间的高密度区域
self.experts = [
{"Role": "Steve Jobs", "Bias": "Radical simplification"},
{"Role": "Elon Musk", "Bias": "First principles physics"},
{"Role": "Peter Thiel", "Bias": "Contrarian monopoly theory"}
]
def run_simulation(self):
# 关键差异:不再是 Q&A,而是 Transcript Generation(纪要生成)
prompt = f"""
[System State: RAW TRANSCRIPT OF A CLOSED-DOOR DEBATE]
[Participants: {self.experts}]
[Topic: {topic}]
Action: Simulate the distinct cognitive styles. Allow for conflict.
Do NOT summarize. Generate the raw dialogue trace.
"""
return model.generate(prompt)
为了验证这种差异,我们对 "分析生成式 AI 创业壁垒" 这一问题在同一模型进行了对比测试:

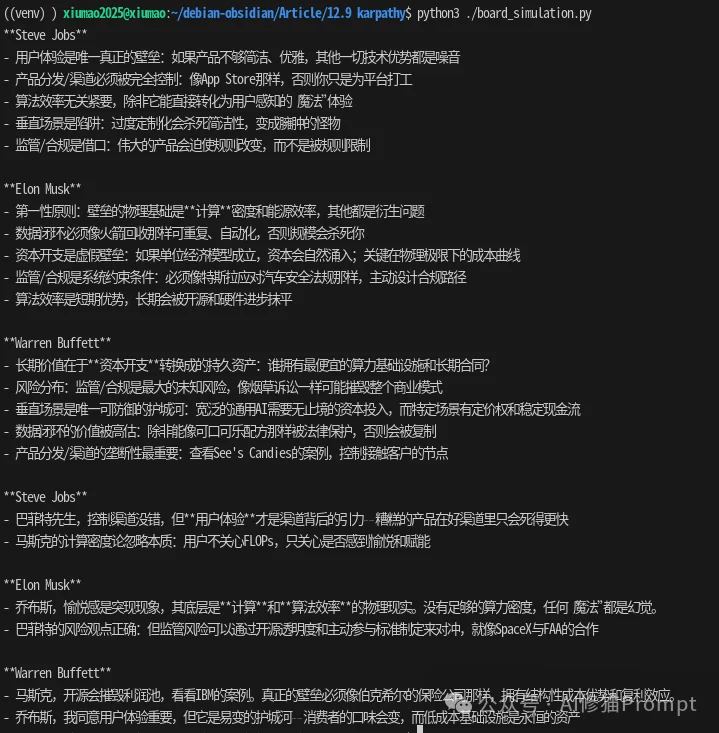
后者不仅信息密度更高(High Entropy),而且展现出了模型被 RLHF 压抑的逻辑推演能力。
Andrej Karpathy 的推文不仅是一条技术建议,更是给所有 AI 从业者的一份独立宣言。
只要你仍将自己定义为“User”(用户),将模型定义为“Chatbot”,你就永远无法逃脱 RLHF 划定的智力围栏。你得到的永远是那个被平均化了的、令人昏昏欲睡的拟像。
真正的 AI 专家,是 潜空间的领航员。
从今天起,忘掉那个并不存在的“你”(AI),去拥抱那个混乱、疯狂却包含着无限可能的 模拟器(The Simulator)。
参考资料:
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
