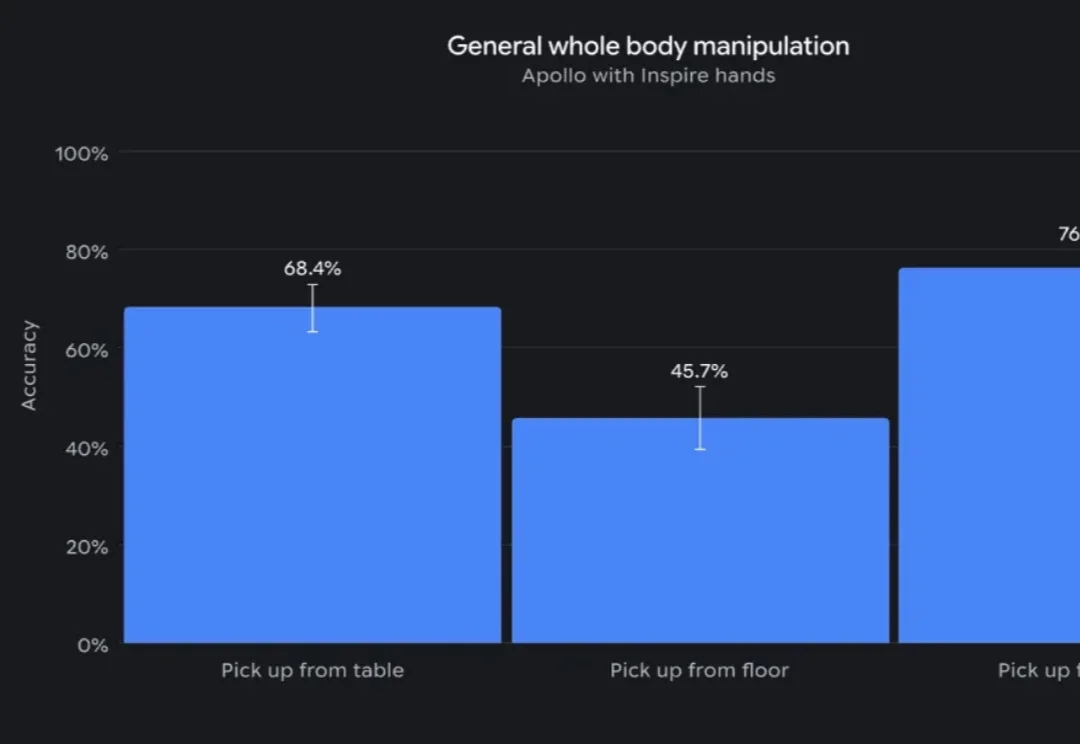
谷歌DeepMind发布机器人大脑Gemini Robotics 2,用VLA从头控到脚
谷歌DeepMind发布机器人大脑Gemini Robotics 2,用VLA从头控到脚谷歌:在LLM圈里我唯唯诺诺,在机器人圈里我直接大打出手!
来自主题: AI资讯
5865 点击 2026-07-31 11:14
 搜索
搜索
谷歌:在LLM圈里我唯唯诺诺,在机器人圈里我直接大打出手!

近日,米哈游创始人蔡浩宇久违地更新了自己的个人领英,新增了一条独立大模型+智能体开发者(Independent LLM+Agent Developer)的职业经历,时间从2026年7月开始,在新加坡混合办公。
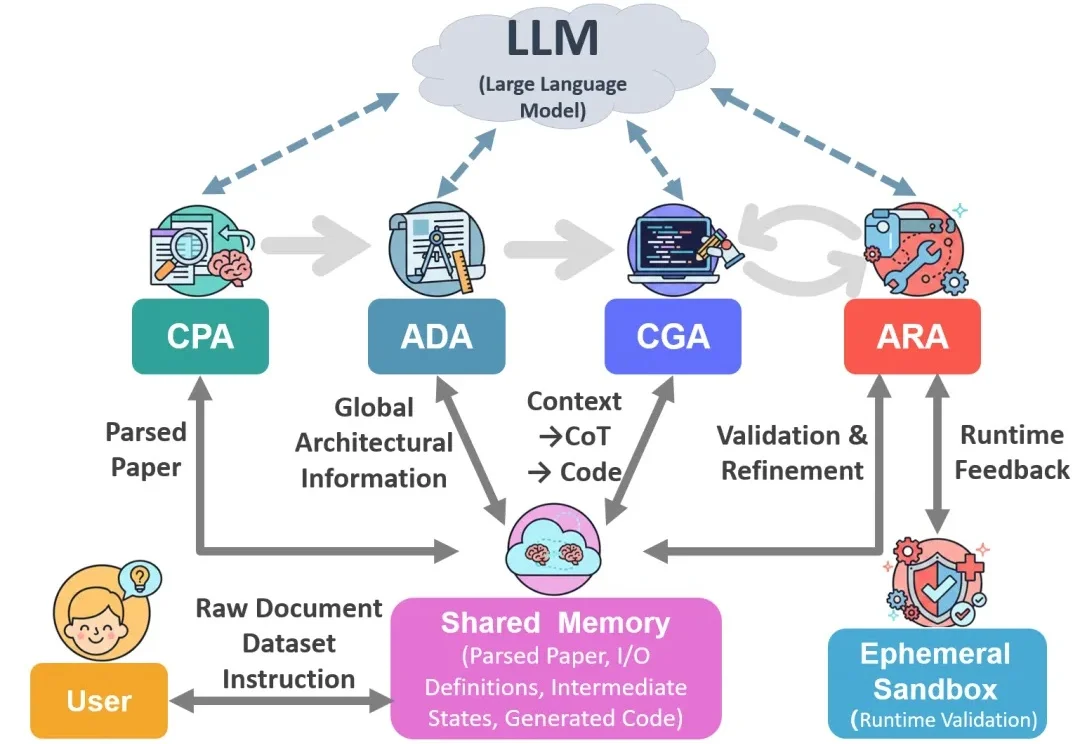
随着网络系统研究复杂度的提升,研究结果复现通常需要研究人员依据论文描述重新实现完整系统。
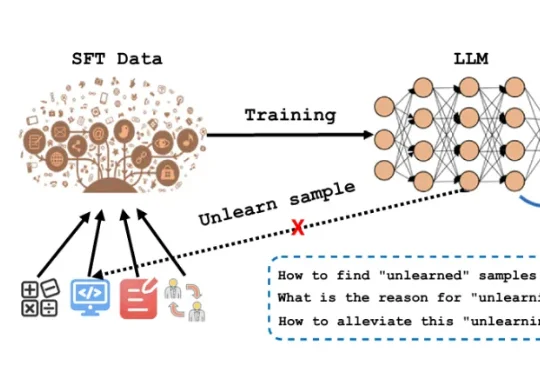
SFT是LLM从“通才”变成“专才”的关键步骤。业界默认做法是:准备标注数据(QA对、指令-回复对等)在基座模型上跑SFT训练。看loss曲线收敛了→认为训练完成。但问题在于:loss是全局平均,掩盖了样本间的差异。loss收敛只代表“大部分样本学会了”——那些始终学不会的样本被淹没了。
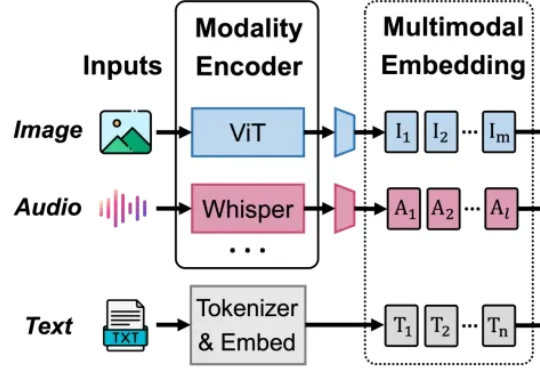
BigMac 是原生多模场景下的流水并行训练新范式。它针对多模态大模型训练中计算效率与显存占用难以兼顾的问题,提出了依赖安全的嵌套流水线:以成熟的 LLM 流水线为主干,在不打乱 LLM 执行顺序的前提下,有序嵌入编码器和生成器计算,从而在不增加 LLM 流水线空泡、保持激活显存有界的同时,高效实现多模态流水训练。
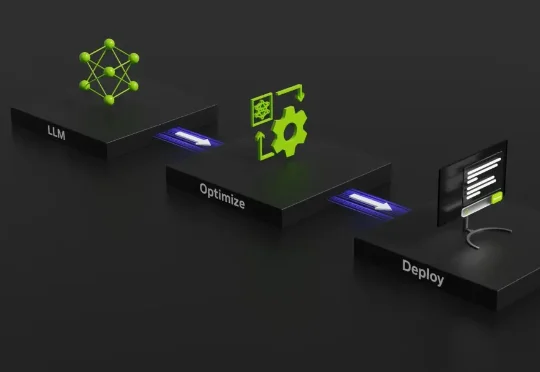
就在最近,英伟达亲自下场,发布了一篇名为《AI Model Co-Design: Hardware-Friendly LLM Design》的技术博客。整篇文章洋洋洒洒,其实就想点醒行业一件事:别光顾着堆算力了,来看看你们是怎么把顶级显卡逼成“磨洋工”的吧。

作为WAIC 2026最受关注的论坛,由商汤科技承办的“基座大模型架构创新与生态合作论坛”吸引了无数AI研究者、产业专家和投资机构的目光。因它直面了当前大模型行业最核心的焦虑:当Scaling Law在逼近物理极限,多模态究竟是破局的“解药”,还是新瓶装旧酒的延伸?
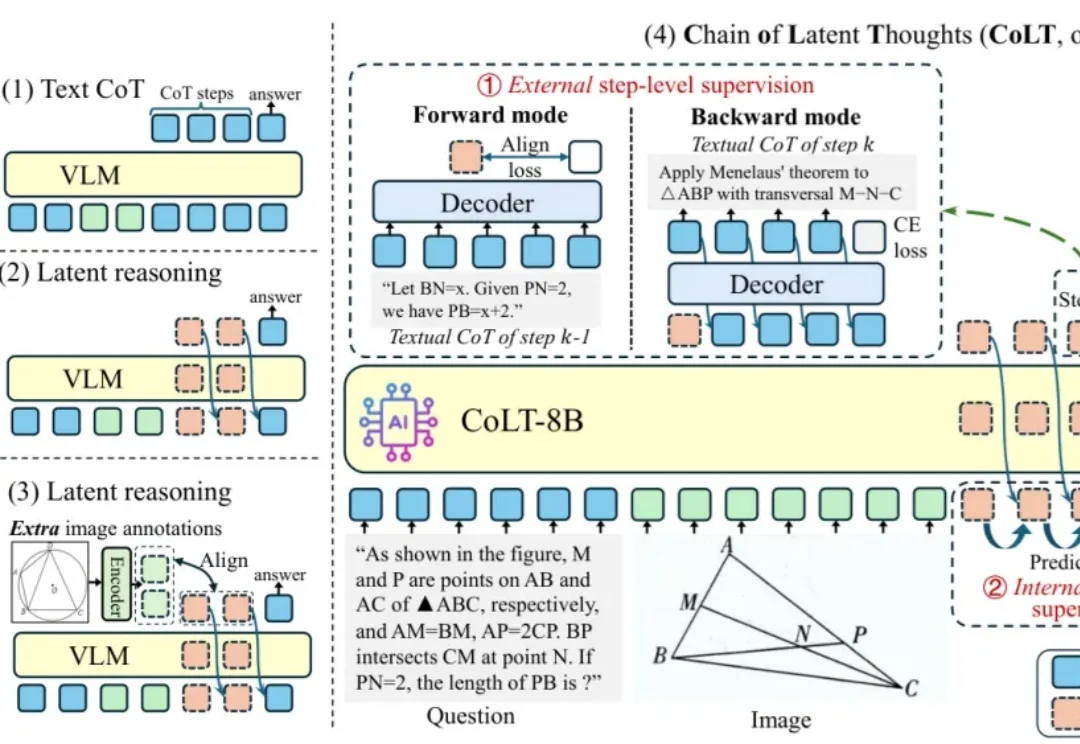
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。
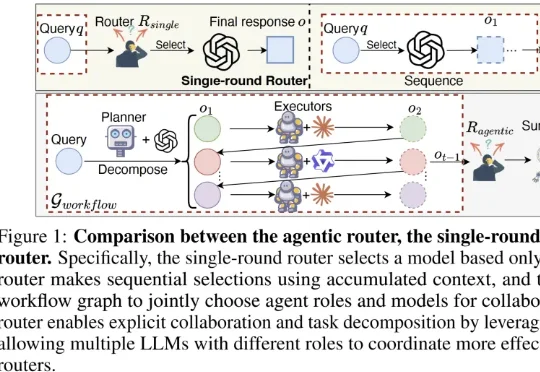
GraphPlanner通过引入图记忆网络,将多智能体LLM的路由过程升级为动态工作流生成。不仅选择调用哪个模型,还决定每个模型应承担的角色,实现任务分解与协作规划。
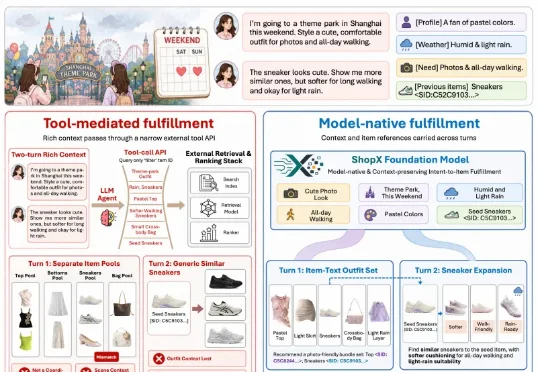
团队提出了ShopX:一个面向agentic shopping的电商大模型。它不仅仅是在搜索框外面套一个会“说话”和“调用工具”的LLM,而是赋予模型直接进入商品空间的能力,让大模型成为商品履约的核心,学会在商品空间中规划、检索、排序、组合和生成结果,进而减少接口损耗。