# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着基础模型的日益成熟,AI领域的研发重心正从“训练更强的模型”转移到“构建更强的系统”。在这个新阶段,适配(Adaptation) 成为了连接通用智能与垂直应用的关键纽带。
这正是UIUC(伊利诺伊大学香槟分校)领衔,联合斯坦福、普林斯顿、哈佛、加州理工、伯克利、华盛顿大学等全球顶尖高校团队在这两天发布的重磅综述《Adaptation of Agentic AI》中提出的核心论断。

这项工作终结了技术路线的碎片化讨论:它将提示工程(Prompt Engineering) 和微调(Fine-Tuning) 统一归纳为“适配”的两种形式。如果说基础模型是通用的“大脑”,适配就是让它能够精准指挥工具这一“肢体”的神经系统。本文将为您深度解读这篇定义了 Agent 开发新范式的“宪法级”文件,通过其精妙的2X2框架,找到最优的系统设计方案
为了理解“适配”,我借用了电影《环太平洋》里的设定。图片用nano banana pro生成。


那么,这个“同步”到底该怎么做?是让驾驶员去适应机甲的操作习惯?还是改造机甲来配合驾驶员的指令?这取决于您手中握着什么资源。
在深入具体的算法之前,我们需要先建立一个全局视角。研究者并没有把所有适配方法混为一谈,而是通过一个精妙的二维坐标系四大适配范式,将它们梳理得井井有条。

这不仅是一个学术分类,更是您在工程实践中的决策地图。您的位置,取决于两个最根本的问题:您手里有什么资源? 以及您想优化什么?
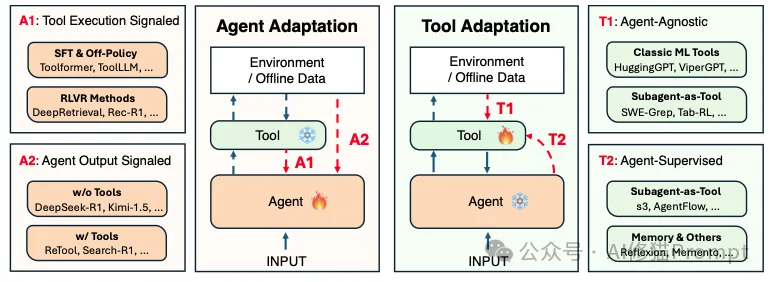
这个维度决定了我们是改(Agent)还是改工具(Tool)。这也直接对应了您在现实中的两种身份:

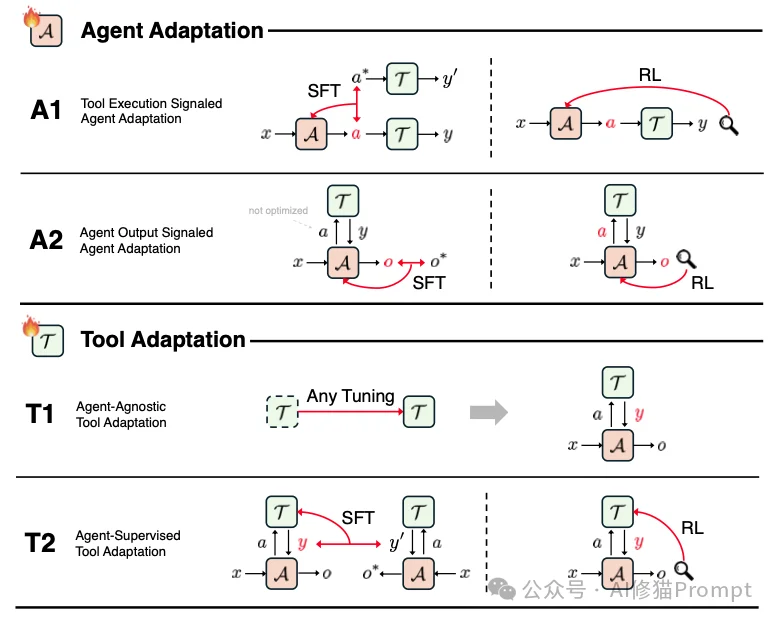
基于这两个维度,我们得到了四个象限:A1、A2、T1、T2。接下来,让我们逐一拆解这四种打造超级Agent的核心心法。
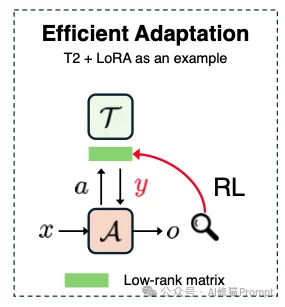
这个范式 (Tool Execution Signaled) 关注的是“工欲善其事,必先利其器”。如果您是拥有模型权重的白盒玩家,这是让模型学会使用复杂工具的第一步。

A1 方法的发展时间线(以工具执行结果作为信号进行代理适应)
在此范式下,我们通过修改代理(Agent)的参数,让它学会如何正确地调用工具。这里的“正确”,通常指的是物理或语法层面的正确。
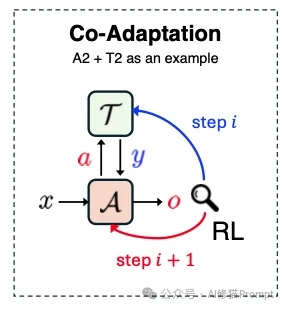
如果说A1是教“技法”,那么A2 (Agent Output Signaled) 就是在教“心法”和“策略”。同样是针对白盒玩家,A2的要求更高。
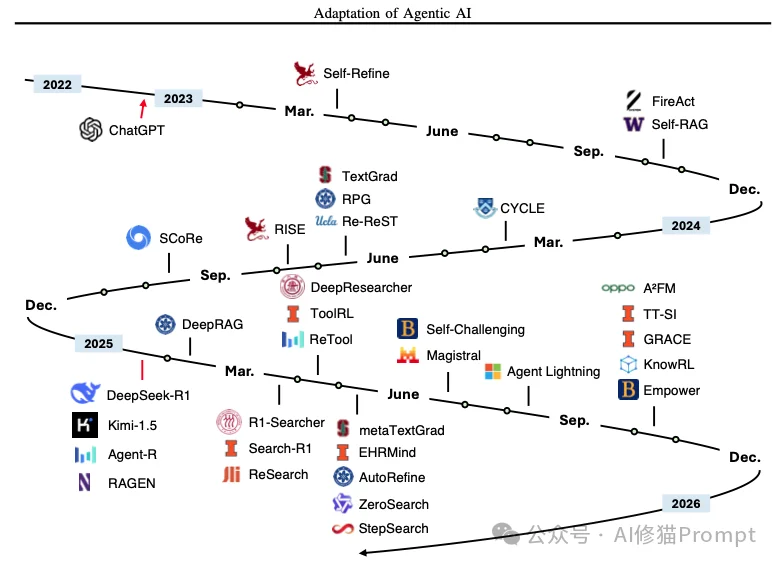
A2方法的发展时间线(以代理输出作为信号进行代理适应性调整)
在这个范式中,我们依然修改代理(Agent)的参数,但反馈信号不再是工具报错与否,而是最终任务完成得怎么样。
现在,我们将视角转向“改工具” (Agent-Agnostic)。对于只能使用API的黑盒玩家,或者是追求模块化的工程师,这是最直观的模式。
这是本篇论文中最具颠覆性、也最值得您关注的一个范式(Agent-Supervised)。它代表了工程思维的胜利。
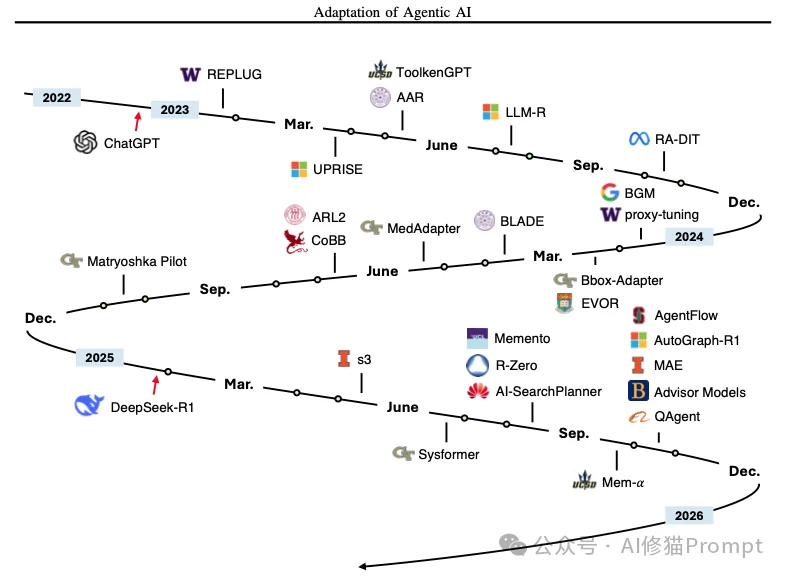
T2方法的发展时间线(由代理进行工具适应性调整,传统与记忆相关的方法不适用) 由于版面限制,此处未予详列。
它的逻辑是:既然大模型(Agent)太贵、太难训练,我们为什么不保持大模型不动,而去训练一个小工具来配合它呢? 研究者将其称为“共生反转”(Symbiotic Inversion)。
基于对四大范式的深入分析,论文指出,最有效的智能体系统并非单一范式的产物,而是代理适应(Agent Adaptation)与工具适应(Tool Adaptation)的战略性结合。在实际构建系统时,应依据资源约束、优化目标及系统演进需求,采取以下分层决策逻辑:

系统的物理形态决定了适配的可行域:
针对不同的性能瓶颈,应选择对应的优化范式:
论文强调,未来的主流趋势是混合系统,而非单一维度的优化。理想的架构设计应遵循以下两条路径的整合:

论文强调:最佳实践不是在四者中做单选,而是将A1/A2用于确立核心推理范式,将T1/T2用于构建模块化、可扩展的能力生态,从而实现系统的鲁棒性与高效性。
理论落地,我们来看看这些范式是如何支撑起当今最顶尖的AI应用的。
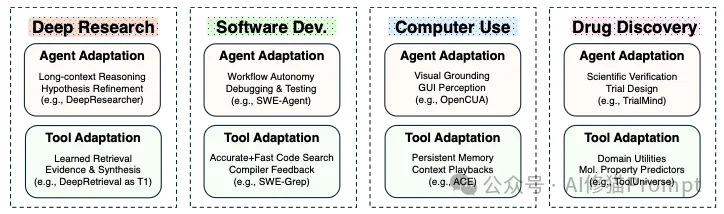
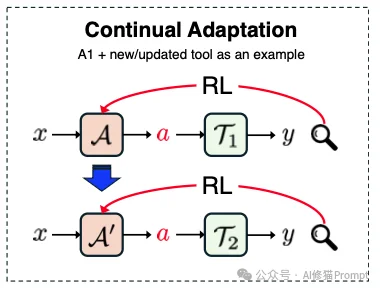
论文最后指出了一个激动人心的方向:协同适配 (Co-Adaptation)。

最后必须提醒一点,适配带来了能力,也带来了风险。
从“大模型”到“Agentic AI”,本质上是从单一的智力堆砌走向复杂的系统工程。
这篇论文最大的贡献,就是打破了“只改模型参数”的思维定势。如果您手里只有API,不要气馁,通过T2范式打磨工具,您一样可以构建出超越GPT-4原生表现的超级应用;如果您拥有本地模型,A1和A2的广阔天地正等待您去探索。
适配,就是让硅基智能真正“长出双手”,去触碰和改变这个物理世界的关键一步。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
