# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家
2022 年底,ChatGPT 横空出世,其能力震惊了整个世界。2024 年底,DeepSeek 以极低的训练成本和极高的性能再次震惊了世界。短短几年间,大模型疯狂迭代,能力不断提升,仅在美国,AI 领域的投资规模便超过了许多国家全年的 GDP!2025 年底,Google 强势推出 Gemini 3,模型能力突飞猛进,TPU 训练范式也对英伟达的生态发起了颠覆式挑战。
业界普遍认为 Gemini 3 是迈向通用人工智能(Artificial General Intelligence,AGI) 和超级人工智能(ASI,Artificial Super Intelligence,ASI)的关键突破,是人类和机器合作的惊人之作。然而,正如 Ilya Sutskever 于 11 月 26 日的访谈中指出:大模型 Scaling Law 和摩尔定律一样,迟早会因为物理限制而失效。因此,如何打开大模型训练的炼丹炉,看清黑盒子背后的基本原理,回答大模型是否已逼近其能力极限就成为迫在眉睫的问题了。但是,前人对大模型的理论研究一直停留在单一维度,使得人们只能看到大模型背后原理的冰山一角,对黑盒子的理解也失之片面。
11 月 3 日,我们在 arXiv 上挂出了一篇论文 Forget BIT, It is All about TOKEN: Towards Semantic Information Theory for LLMs [1]。该研究将统计物理、信号处理和信息论三者有机结合,系统地总结了对大模型背后数学原理的思考和理解,期望给全面揭示大模型的第一性原理带来曙光。过去一段时间,我们在以下的学术会议上分别报告了这方面的工作:
会上和专家、学者们有很多互动,也收到了不少有价值的反馈。同时也将论文发给了一些海内外的专家、学者们,也收到了不少意见和建议。但是,原论文涉及的领域很多、概念体系复杂,加之写法上很学术,因而比较晦涩难懂。
为了便于理解,这里尝试用通俗易懂的语言写一个文章系列来解读这篇论文,其中一些内容也是原论文没有包含的。预计至少包括以下三篇文章,每一篇围绕一个专题展开:
需要指出,我们的研究并不是要否定大模型的重要价值,它是一个非常强大的工具,当前形态就能极大提升人们整合和处理信息的效率,这是谁也无法否认的。我们想要探讨的是当前大模型的第一性原理,从而界定其能力极限,并探讨面向未来的技术路径。
2024 年诺贝尔物理学奖授予了 John Hopfield 和 Geoffrey Hinton,颁奖词为:For foundational discoveries and inventions that enable machine learning with artificial neural networks。许多人不太理解,甚至一些 AI 领域的人也认为诺贝尔奖开始蹭热点了。但实际上从早期的 Hopfield 网络开始,神经网络和统计物理就有非常深刻的联系。
Hopfield 本身就是一位物理学家,他于 1982 年提出了 Hopfield 网络,其联想记忆能力震惊了当时的世界 [2]。这一突破重新激发了人们对神经网络和 AI 的大范围研究。可以说,他对 AI 研究走出寒冬做出了不可磨灭的贡献。被称为 “AI 教父” 的 Hinton 则是第一位认识到统计物理方法在神经网络中有巨大价值的计算机科学家。1985 年,他与另外两位合作者提出了 Boltzmann 机,其关键就是引入了统计物理中的能量模型(Energy-based Model,EBM)[3][4]。除了两位诺奖得主外,还有一位女物理学家 Elizabeth Gardner 非常关键。1988 年,Gardner 三度出手,系统地研究了 Hopfield 网络的记忆容量问题,即到底能记住多少个随机模式 [5][6][7]。后来人们将这个容量称为 Gardner 容量。Gardner 用的方法就是统计物理中的 Spin Glass 模型和 Replica 方法。Replica 方法的提出者则是 2021 年诺贝尔物理学奖得主 Giorgio Parisi [8][9]。我们今年和他有一场访谈(视频链接:https://weixin.qq.com/sph/AlRVrYjAi),深入探讨了 AI 与统计物理的关系。
人们逐步认识到大模型的目标只有一个:预测下一个 Token。Transformer 是当前实现这一目标的有效架构。考虑一个 Decoder-only 的 Transformer 架构,按照从输入到输出的顺序,可以分解为 Attention 和 FFN 两个主要模块 [10]。本节将重点讨论 Attention 模块。

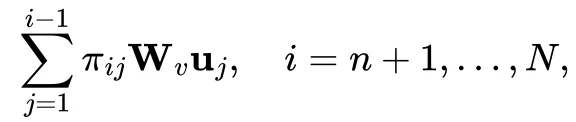

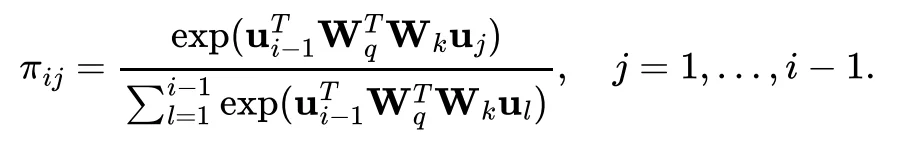

就是一个双线性型(Bilinear Form)。在数学上,双线性型是基于内积建模非对称关系的最简形式。因此,Attention 机制能够有效的捕捉自然语言中两个 Token 之间的非对称语义关系。

从这个角度看,Attention 机制的关键之一是学习一个组态(Configuration)B,使得语义相关性最高等价于能量函数最低。这个逻辑和面向 Attention 机制的基于隐变量 J 的变分推理解释,即证据下界(Evidence Lower Bound, ELBO)相吻合。详细推导参见论文中 ELBO 的相关章节,这里不再赘述。
以上分析可至少得到两点启发:




关于 Transformer 的记忆容量问题,学界已经取得了一些初步结果,归纳如下:

近年来,人们经常会用能力涌现来描述大模型为什么大就是好。从 Gardner 容量的角度看,其本质可以理解为随着参数量的增加,大模型记住的知识量超过了某个阈值,就出现了统计物理中的相变现象。实际上,Parisi 教授也是从相变的角度来研究 Shannon 容量的,并且提出:即使通信速率小于信道容量,也存在计算上困难的区域。因此,通过统计物理方法,有望从理论上解释模型规模和模型能力的尺度定律(Scaling Law),并最终解释能力涌现的相变现象。我们在这个方向也取得了一些初步成果 [22]。
泛化误差是刻画大模型实际效果的关键指标。基于 Transformer 的 EBM 形式,可以从理论上推导泛化误差界。详细的数学证明可以参见论文的对应章节。主要用到的数学工具是 Rademacher 复杂度和 Talagrand 不等式 [23]:


这个定义是非常普适的,但没有可操作性。随后 Granger 给出了一系列具体的方法,来检测两个时间序列是否有 Granger 因果关系。这些方法已经广泛应用于物理学、神经科学、社交网络、经济学和金融学等领域。


其中 L 为相互影响的长度。后续的相关研究则进一步印证:对于向量高斯自回归过程,传递熵和 Granger 因果是等价的 [27]。另一方面,传递熵也是有限长度版本的定向信息。这一概念由 1988 年香农奖得主 James Massey 在 1990 年提出 [28]。他在论文中也讨论了带反馈的通信系统的因果性问题。由此,我们引出了后续两篇的主要内容:
参考文献
1. B. Bai, "Forget BIT, it is all about TOKEN: Towards semantic information theory for LLMs," arXiv:2511.01202, Nov. 2025.
2. J. Hopfield, “Neural networks and physical systems with emergent collective computational abilities,” Proceedings of the National Academy of Sciences, vol. 79, no. 8, pp. 2554-2558, Apr. 1982.
3. D. Ackley, G. Hinton, and T. Sejnowski, "A learning algorithm for Boltzmann machines," Cognitive Science, vol. 9, no. 1, pp. 147-169, Jan. 1985.
4. G. Hinton, "A practical guide to training restricted Boltzmann machines," in Neural Networks: Tricks of the Trade, 2nd ed., Berlin, Germany: Springer, 2012, pp. 599-619.
5. E. Gardner, "The space of interactions in neural network models," Journal of Physics A: Mathematical and General, vol. 21, no. 1, pp. 257-270, Jan. 1988.
6. E. Gardner and B. Derrida, "Optimal storage properties of neural network models," Journal of Physics A: Mathematical and General, vol. 21, no. 1, pp. 271-284, Jan. 1988.
7. E. Gardner and B. Derrida, "Three unfinished works on the optimal storage capacity of networks," Journal of Physics A: Mathematical and General, vol. 22, no. 12, pp. 1983-1994, Jun. 1989.
8. M. Mezard, G. Parisi, and M. Virasoro, Spin Glass Theory and Beyond: An Introduction to the Replica Method and Its Applications. Singapore: World Scientific Publishing, 1987.
9. G. Parisi, In a Flight of Starlings: The Wonders of Complex Systems. Milan, Italy: Penguin Press, 2023.
10. A. Vaswani et al., "Attention is all you need," in Proc. 31st Annual Conference on Neural Information Processing Systems ’17, Long Beach, CA, USA, Dec. 2017.
11. E. Jaynes, Probability Theory: The Logic of Science. New York, NY, USA: Cambridge University Press, 2003.
12. A. Gu and T. Dao, "Mamba: Linear-time sequence modeling with selective state spaces," arXiv: 2312.00752, May 2024.
13. T. Dao and A. Gu, "Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality," arXiv: 2405.21060, May 2024.
14. DeepSeek-AI, “DeepSeek-V3.2: Pushing the frontier of open large language models,” DeepSeek, Hangzhou, China, Dec. 2025.
15. T. Cover, "Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition," IEEE Transactions on Electronic Computers, vol. EC-14, no. 3, pp. 326–334, Jun. 1965.
16. M. Talagrand, Mean Field Models for Spin Glasses - Vol. 1: Basic Examples. Berlin, Germany: Springer, 2011.
17.M. Talagrand, Mean Field Models for Spin Glasses - Vol. 2: Advanced Replica-Symmetry and Low Temperature. Berlin, Germany: Springer, 2011.
18. H. Ramsauer et al., "Hopfield networks is all you need," arXiv: 2008.02217, 28 Apr. 2021.
19. M. Geva, R. Schuster, J. Berant, and O. Levy, "Transformer feed-forward layers are key-value memories," in Proc. ACL Conference on Empirical Methods in Natural Language Processing ‘21, Punta Cana, Dominican Republic, Nov. 2021, pp. 5484–5495.
20. J. Fang et al., "AlphaEdit: Null-space constrained knowledge editing for language models," arXiv: 2410.02355, 22 Apr. 2025.
21. W. Fei et al., "NeuralDB: Scaling knowledge editing in LLMs to 100,000 facts with neural KV database," arXiv: 2507.18028, 24 July 2025.
22. X. Niu, B. Bai, L. Deng, and W. Han, "Beyond scaling laws: Understanding transformer performance with associative memory," arXiv: 2405.08707, 14 May 2024.
23. M. Mohri, A. Rostamizadeh, and A. Talwalkar, Foundations of Machine Learning, 2nd ed. Cambridge, MA, USA: The MIT Press, 2018.
24. C. Granger, "Testing for causality: A personal viewpoint," Journal of Economic Dynamics and Control, vol. 2, no. 1, pp. 329-352, Jan. 1980.
25. J. Pearl, Causality: Models, Reasoning, and Inference, 2nd ed. New York, NY, USA: Cambridge University Press, 2009.
26. T. Schreiber, "Measuring information transfer," Physical Review Letters, vol. 85, no. 2, pp. 461-464, Jul. 2000.
27. L. Barnett, A. B. Barrett, and A. K. Seth, "Granger causality and transfer entropy are equivalent for Gaussian variables," Physical Review Letters, vol. 103, no. 23, p. 238701, Dec. 2009.
28. J. Massey, “Causality, feedback and directed information,” in Proc. IEEE International Symposium on Information Theory ‘90, Waikiki, HI, USA, Nov. 1990.
文章来自于“机器之心”,作者 “白铂 博士”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
