# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

面对谷歌TPU的攻势,英伟达开始紧张了。
谷歌的 Gemini 3 和 Anthropic 的 Claude 4.5 Opus 等前沿模型,并非使用英伟达硬件训练,而是运行在谷歌最新的 Ironwood 架构 TPUv7 上。
TPU 的成果无需多言:Gemini 3 是全球最强模型之一,而且完全在 TPU 上训练。
连山姆·奥特曼也公开承认,Gemini 抢走了 OpenAI 的风头,“前景有些不妙”。
这意味着,一种可行的 GPU 替代方案已经到来。
英伟达也慌了,赶紧发布了一份安抚性的新闻稿,告诉所有人保持冷静,我们仍然遥遥领先。
英伟达的紧张不难理解,这几个月对 Google DeepMind、GCP 和 TPU 战线而言是一路大胜:
为什么在 Blackwell 还没完全铺开、英伟达的 GPU 帝国依然铜墙铁壁的情况下,TPU 却突然具备了挑战 GPU 的实力?
——英伟达的统治地位要结束了吗?
这一切还得从2006年开始唠起。
早在 2006 年,
谷歌就开始推销构建专门 AI 基础设施的想法, 但问题在 2013年发生了转变。谷歌开始意识到,如果想在任何规模上部署人工智能,就必须将现有的数据中心数量翻倍。因此,他们开始为 TPU 芯片奠定基础,并于 2016 年投入生产。
TPU 协议栈长期以来一直与英伟达的 AI 硬件抗衡,但它主要支持谷歌内部工作负载。过去,谷歌只通过 Google Cloud Platform 出租 TPU,外部团队无法直接购买。
直到最近,谷歌开始将 TPU 硬件直接出售给企业客户。
关键转折点在于谷歌与Anthropic达成的战略协议。今年九月初,就有消息称Anthropic 作为主要外部客户之一, 需求至少有 100 万个 TPU。这一消息在十月得到了 Anthropic 和谷歌的正式确认 。
关于 100 万颗 TPU 的分配结构:
据SemiAnalysis报道,Anthropic 的承诺为谷歌的利润增加了数十亿美元。此外,Meta 也是 TPU 的大客户。
即便作为竞争对手,OpenAI也计划租赁谷歌TPU。有消息称,今年OpenAI 希望通过 Google Cloud 租赁的 TPU 能够帮助降低推理成本,这可能会推动 TPU 成为英伟达 GPU 更廉价的替代品。

值得注意的是,OpenAI 甚至还没有部署 TPU,仅仅是存在可行的替代方案,就争取到了英伟达GPU大约 30%的折扣。
因此有分析师调侃道:“你买的TPU越多,你节省的英伟达GPU支出就越多。”
这句话真是狠狠打脸了老黄在介绍BlackWell时那句知名的口号:“买得越多,省得越多。”

从纸面规格看,TPUv7 “Ironwood” 的理论算力(FLOPs)和内存带宽已经接近英伟达最新一代 Blackwell GPU。但真正的杀手锏是:TPU极低的总拥有成本(TCO)。
根据分析:
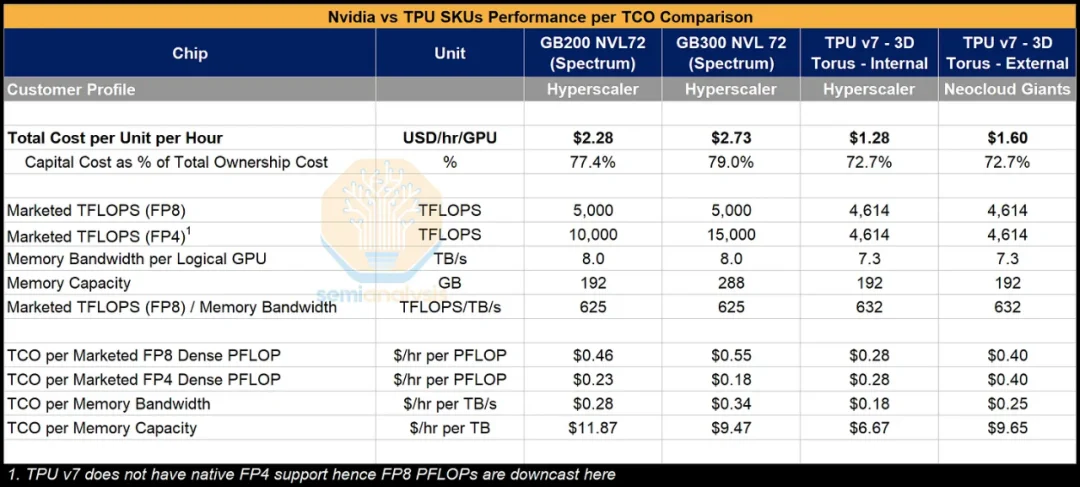
TPU 的架构还带来天然扩展优势:谷歌的系统能把 9,216 颗芯片联成一个高密度的训练域;而传统英伟达系统通常只有 64~72 颗芯片能做到紧密互联。这使得 TPU 更适合超大规模 AI 训练任务。
另一个关键因素是 Anthropic 的工程实力。团队中有前 Google 编译器专家,既熟悉 TPU 软件栈,也精通自家模型架构。他们可以通过定制内核提升 TPU 利用效率,从而实现 更高的模型 FLOP 利用率(MFU) 和更优的 $/PFLOP 性能。
综合考虑更低的 TCO 和更高的有效算力:
换句话说,即便谷歌或 Anthropic 仅实现 GB300 FLOPs 的一半,成本也能持平。凭借顶尖的编译器团队和对模型的深度理解,Anthropic 在 TPU 上的 MFU 潜力甚至可能达到 40%,这意味着每单位有效训练 FLOP 的成本可降低约 62%,带来巨大的经济优势。
长期以来,软件生态是 TPU 最大的短板。和所有非英伟达加速器一样,TPU 生态系统中的外部开发者数量远少于 CUDA 生态系统。CUDA 是行业标准,开发者要迁移到 TPU 需要重写大量工具链。
但现在情况正在改变,因为谷歌正在三件事上投入大量资源:
TPUv7 支持原生 PyTorch 集成,包括急切执行、完全支持分布式 API、torch.compile 以及 PyTorch 工具链下的自定义 TPU 内核支持。目标是让 PyTorch 能像在 Nvidia GPU 上一样轻松运行 TPU。
谷歌还大力参与 vLLM 和 SGLang 这两个流行的开源推理框架,并宣布通过一个非常“独特”的集成,支持 vLLM 和 SGLang 的测试版 TPU v5p/v6e。

谷歌的目标很明确:让开发者无需重建生态,就能无痛切换到 TPU。
不过,TPU 软件栈的核心XLA 编译器仍未开源,文档也不完善。这导致从高级用户到普通用户都感到沮丧,无法调试代码出了什么问题。此外,他们的 MegaScale 多重训练代码库也不是开源的。SemiAnalysis 认为,如果能开源,将显著降低 TPU 的采用门槛。
此外,为了让数十万颗 TPU 快速落地,Google 还采用了一种非常激进的融资策略:
在这些交易中,谷歌充当“最终兜底者”,如果运营方失败,Google 保证继续支付租金。
这使得大量旧的加密挖矿数据中心被迅速改造成 AI 数据中心,也让 TPU 的部署速度大幅提升。
面对谷歌的威胁,英伟达正在准备反击。其下一代 “Vera Rubin” 芯片,预计将在 2026~2027 年推出,将采用相当激进的设计,包括:
而谷歌计划中的应对方案 TPUv8,则采用了双重策略。据了解,谷歌计划发布两个变体:一个与长期合作伙伴博通(代号“Sunfish”)共同开发,另一个与联发科(代号“Zebrafish”)合作开发。
但TPUv8的设计稍显保守。有分析师指出,该项目存在延误,且依赖架构避免了竞争对手中激进使用台积电的 2 纳米工艺或 HBM4。
SemiAnalysis也指出,一开始,谷歌在硅芯片设计理念上相较于英伟达更为保守。历史上,TPU 出厂时峰值理论 FLOP 数量明显少于相应的英伟达 GPU 和更低的内存规格。
如果英伟达 Rubin 按计划实现性能跃升,TPU 当下的成本优势可能会被彻底抹平。甚至可能出现,英伟达 Rubin(特别是 Kyber Rack)比 Google TPUv8 更便宜、更高效的情况。
此外,TPU 也并非完美。它在特定深度学习场景中表现出色,却远不如 GPU 灵活。GPU 能运行各种算法,包括非 AI 工作负载。如果明天出现一种全新的 AI 技术,GPU 基本可以立即运行;TPU 则可能需要编译器或内核优化。
此外,从 GPU 体系迁移出来的成本依然高昂,特别是对于深度依赖 CUDA、自定义 kernel 或尚未针对 TPU 优化的框架的团队。
WEKA 的首席人工智能官Val Bercovici 建议:“当企业需要快速迭代、快速上市时,应选择 GPU。GPU 使用标准化基础设施、拥有全球最大的开发者生态、适合动态复杂的工作负载,并能轻松部署在现有本地数据中心,而无需进行电力或网络的重构。”
由于 GPU 更普及,对应工程人才也更多。TPU 则需要更稀缺的技能。Bercovici 也表示:“要充分发挥 TPU 的潜力,需要能写自定义 kernel 与优化编译器的工程深度,这类人才极为稀缺。”
总的来说,AI 硬件的竞争愈演愈烈,但现在预测谁将获胜还太早,甚至无法确定是否会有一个唯一的赢家。TPU 的性价比和架构优势确实让人眼前一亮,但英伟达的 GPU 在生态、软件和成熟度上依然不可小觑。在英伟达、谷歌快速迭代,以及亚马逊也加入竞争的背景下,未来性能最高的 AI 系统很可能是混合架构,同时整合 TPU 与 GPU。
那么评论区的大佬们,你们怎么看这场 TPU 与 GPU 的较量?
是否认为TPU 已经具备挑战 GPU 的实力?
还是觉得英伟达靠 CUDA 护城河仍难撼动?
欢迎写下你的看法。
参考链接:
https://newsletter.semianalysis.com/p/tpuv7-google-takes-a-swing-at-the
https://venturebeat.com/ai/how-googles-tpus-are-reshaping-the-economics-of-large-scale-ai
文章来自于“51CTO技术栈”,作者 “听雨”。


