# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 的脑回路,终于也开始学会做减法了。
就在最近,OpenAI 悄悄开源了一个“奇葩”模型——仅 0.4B 参数,但 99.9% 的权重是 0。

没错,你没看错。一个几乎“空着”的大脑,反而更聪明、更透明了。
我说怎么有点眼熟,原来正好是前段时间刷到的一篇的 OpenAI 论文"Weight-sparse transformers have interpretable circuits"《权重稀疏的 Transformer 具有可解释性特征》的开源实现。
他们发现,让神经网络“不全连”,反而能让它更聪明、更可解释。
有人甚至直言:这种极致稀疏、功能解耦的思路,可能会让当下热门的 MoE(混合专家模型)走上末路。
过去几年,AI 的能力一路狂飙,从写作、编程到科研样样精通,但问题也越来越明显——它虽强,却太神秘。我们能看到结果,却看不懂过程。

尤其是当 AI 已经开始参与科学研究、教育决策、甚至医疗诊断时,这种说不清自己在想什么的智能,显然让人不太踏实。
于是,AI 科学家们开始思考:
👉 我们能不能真正看懂神经网络是怎么思考的?
👉 能不能设计出一种从结构上就清晰、可解释的 AI?
这就是 OpenAI 这篇论文要讲的事。
他们想从根子上解决问题——从一开始就训练一个“整洁”的大脑。
论文标题:
Weight-sparse transformers have interpretable circuits
论文链接:
https://cdn.openai.com/pdf/41df8f28-d4ef-43e9-aed2-823f9393e470/circuit-sparsity-paper.pdf
要理解 OpenAI 这套新方法有多“逆天”,我们得先看看当下神经网络的真实模样——一句话形容:乱到让人头皮发麻。

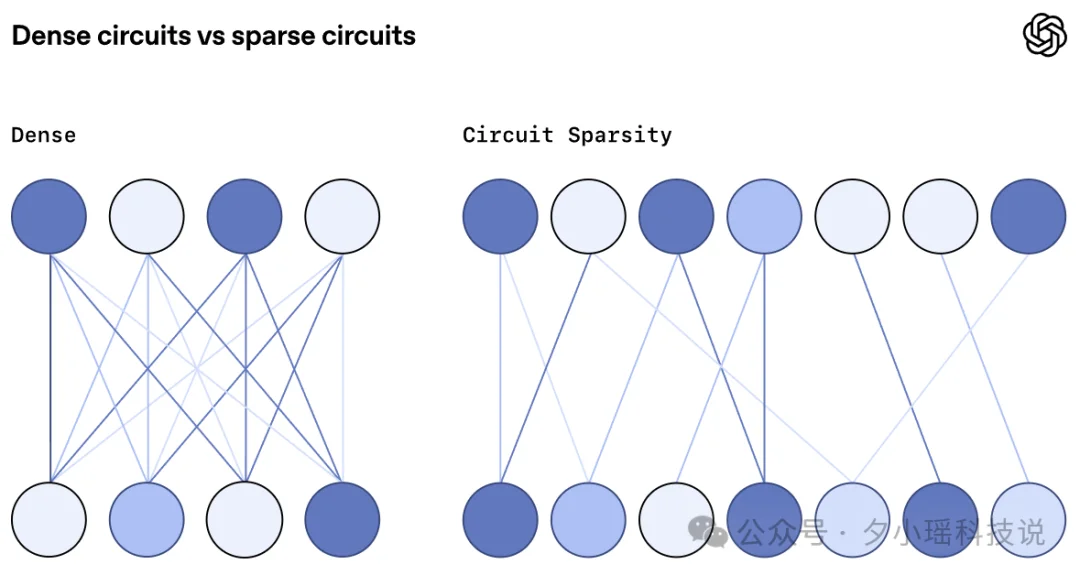
传统神经网络,也叫 Dense Networks(密集网络),它们的连线方式很朴素也很暴力:
每一层的每个神经元,都要和下一层的所有神经元连一条线。
想象一下一个房间,里面站着一百个人,每个人都要和其他所有人各牵一根线……没几秒,这房间就变成“猫抓了五十次的毛线球”。

随着模型变大,这种混乱会呈指数级爆炸。
在这种乱麻结构里,单个神经元往往会执行多种不同的功能:
猫的图片它管、法语句子它也管,甚至还会跑去参与推理任务......
这种神经元“多线程兼职”现象叫 Superposition(功能叠加)。
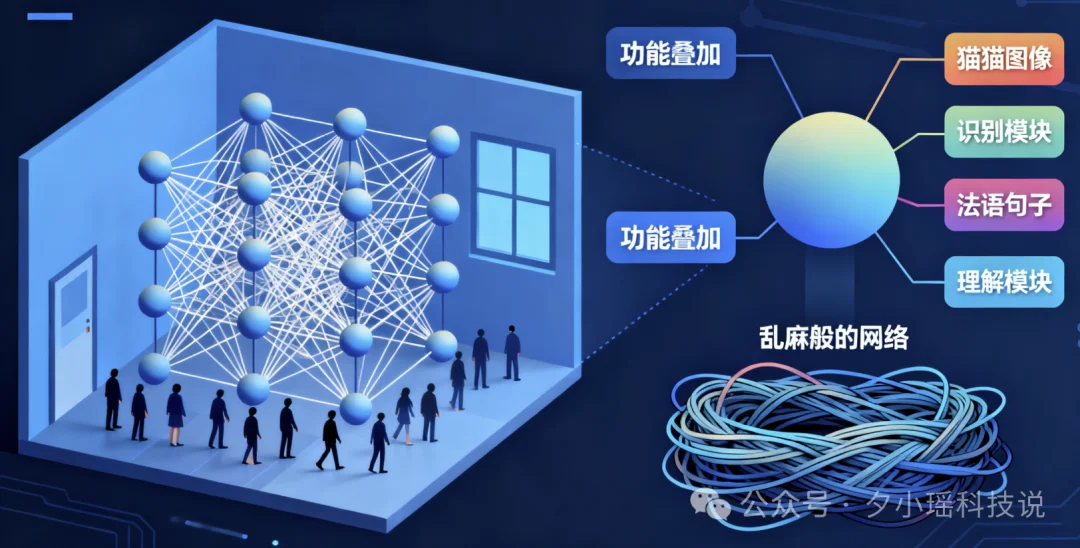
它的问题是:
你一旦想问——“这个神经元到底负责什么?”
它就像一个离职交接不清楚的老员工一样:
业务太多,讲不清楚。。。

可解释性研究过去几年都在努力想办法:
从外面观察损失曲线、激活模式、注意力可视化……
但本质上,这就像试图通过拉扯毛线球外侧几根线,来猜里面的结构。
离真正“看懂大脑”还是差了十万八千里。
问题卡在这儿:我们一直在给一团本来就缠成死结的“毛线球”做体检——量了血压,拍了片,做了可视化报告,但毛线依然是一团毛线。
与其在事后想尽办法解释这种先天就混乱的结构,一个更激进的问题开始浮现出来:能不能从一开始,就别把它织成这样?
当大家还在试图给这团毛线球做 CT、照 X 光、打标签的时候,OpenAI 换了个脑洞:
我们能不能,不从解毛线开始,而是从一开始就织一张整洁的?

也就是说——与其想办法解释一个本来就乱七八糟的网络,不如让它一出生就规规矩矩:别乱连,别多连,别到处伸手。
这便是权重稀疏”(Weight-sparse)模型的核心思想。
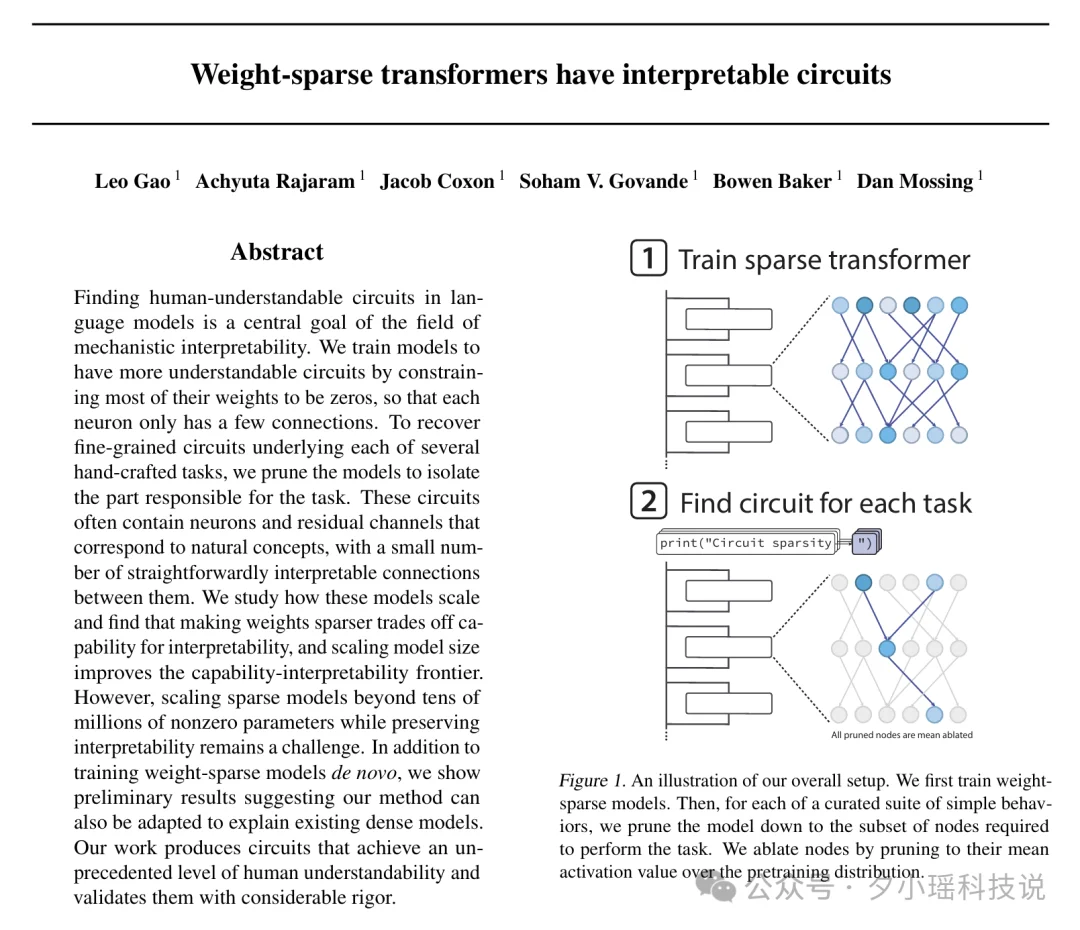
新研究中,在训练语言模型时,研究人员使用了一种与 GPT-2 相似的架构,但增加了一个关键的约束:强制模型中绝大多数的权重为零。
什么意思?
由于每个神经元只能从少数几个上游通道读取信息,或向下游少数几个通道写入信息,模型就被“劝退”了,不再将概念表征分散到多个残差通道中,也不会使用超出严格需要的神经元来表示单个概念。
这种方法就像是要求一位工程师在布线时,必须走线清晰,每个接口功能单一,不要把所有电线都缠在一起。
不过,把线剪掉、结构变干净,只是第一步。
要回答“它是不是真的可解释”,就得进一步追问:在这样一张极简的线路板上,具体是哪几条线、哪几个元件,在共同完成一项明确的功能?
为了衡量稀疏模型在多大程度上解开了其计算过程,研究者引入了“电路”(Circuits)的概念。
这里的“电路”指的是模型中负责执行某个特定行为的、最小化的那一部分网络结构。研究人员手动策划了一套简单的算法任务,对于每项任务,他们都对模型进行“修剪”(Pruning),直到找到能够完成该任务的最小“电路”,然后检查这个电路有多简单。
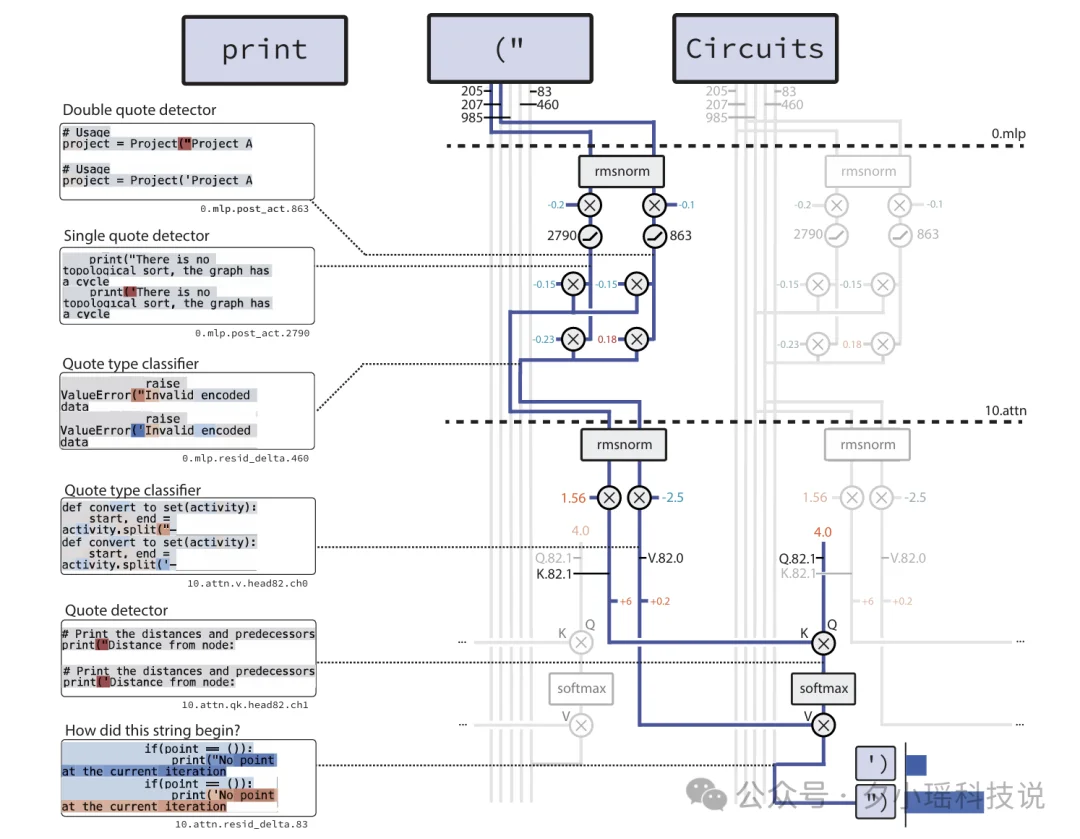
为使这一概念更直观,论文给出了模型处理 Python 代码任务的一个案例,任务很简单:
在 Python 中,字符串开头是什么引号,结尾也必须用同样的引号。
比如:
在传统的密集模型中,这可能涉及到成百上千个神经元的复杂互动,最后谁贡献了啥你根本解释不清。

但在 OpenAI 训练的可解释模型中,研究者发现了一个清晰解耦的“电路”,整个流程分为四步,讲得清清楚楚:
① 编码
模型在不同残差通道里,分别记录:
② 分类处理
第 0 层的 MLP 做两件事:
③ 跳回去找开引号
第 10 层注意力一出手:
④ 输出匹配引号
最后一步:模型根据复制回来的信息,输出 ' 或 " 。
这个被找到的引号匹配电路非常简洁:仅涉及 5 条残差通道、第 0 层 MLP 的 2 个神经元,以及第 10 层注意力机制中的 1 个查询-键通道和 1 个值通道。
就这么点。。。
而且研究人员做了个非常硬核的验证:
这次是真的看明白了。没有任何旁门左道,稀疏模型里的任务完全靠正经逻辑完成!!
但咱先别急,就算是在这些相对小的稀疏模型里,仍然有部分计算路线无法完全解释。放在巨大模型里面,怎么办呢?

OpenAI 认为未来有两条路:
一是给现有“大黑箱”做手术(Dense → Sparse Circuits)。
怎么办?
这就是所谓的 Circuit Extraction(电路提取)。
二是进化出“天生可解释”的大模型(Train Sparse from the Start)。
就像这篇论文做的那样:
从训练之初,就给模型施加稀疏度约束,逼它长成线条清晰的极简大脑。
在前面的研究里,OpenAI 试图从结构层面让模型的大脑变得“干净”——靠稀疏连接、靠可解释电路,让思考路径本身更清晰、更可靠。
但大脑的运行不仅取决于“线怎么连”,还取决于“记什么、不记什么”。
当下的大型模型和智能助手似乎无所不知、过目不忘。然而,这表面上的优点,却可能让 AI 的大脑变成一间杂乱无章的仓库:什么都往里塞,久而久之反而影响了服务质量和安全。

就像一个人如果对所有经历过的事都记得清清楚楚,他的大脑可能被痛苦和噪音填满,难以专注当下。
这个时候,就需要来一场认知上的“断舍离”。

首先,从隐私和伦理角度看,一个永远记得你所有对话的助手并不可爱。想象一下,你正在写演讲稿,它突然冒一句“要不要讲你那次很痛苦的经历?那感觉想必相当糟糕。
其次,从技术性能上讲,恰当的遗忘有助于模型避免“过载”。这样做一方面消除了模型记住大量无用甚至错误信息对后续回答的干扰,另一方面也防止它对旧细节过度执着。毕竟,对 AI 而言,无差别地记住所有细节反而可能导致“信息噪音”掩盖真正有用的知识。
从稀疏专家模型到机器遗忘术,我们看到 AI 领域一个有趣的转变:让 AI“少做点、少记点”,反而让它变得更聪明了。
稀疏网络教会 AI 精打细算地分配“大脑线路”——该连的连,不该连的断;
机器遗忘术则教会它在记忆空间里“轻装前行”——该留的留,不该留的散。
一个发生在结构层,一个发生在记忆层,方向不同,却殊途同归:摒弃冗余,聚焦关键。
当 AI 既不会傻傻地把所有电路都连在一起浪费算力,也不会傻傻地把所有往事都铭记于心无法释怀——也许,我们距离真正聪明又善解人意的机器伙伴就更近了一步。
文章来自于“夕小瑶科技说”,作者 “丸美小沐”。


