# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,随着o1、DeepSeek-R1等模型的爆发,Long Chain-of-Thought(Long CoT)已成为提升LLM复杂推理能力的标配。
然而,“长思考”并非总是完美的。我们常发现模型会陷入 “过度思考”(Overthinking)的陷阱:为了得出一个简单的结论,模型可能会生成数千个冗余Token,甚至在错误的路径上反复横跳(Backtracking)。这不仅浪费了宝贵的算力,还增加了推理延迟。
如何让模型在“深思熟虑”的同时,保持“思维敏捷”?
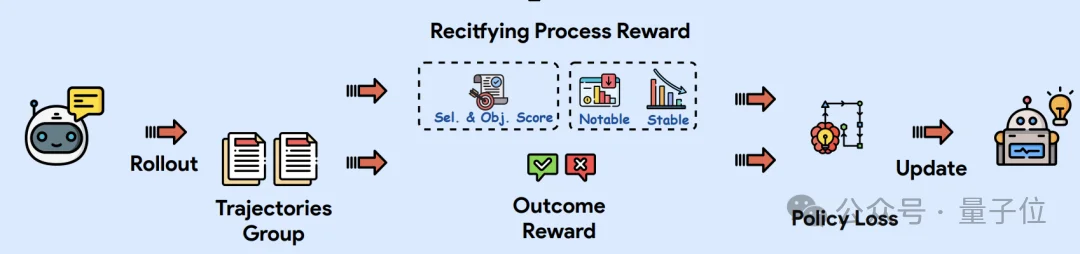
近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。
这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:
RePro基于这样一个核心思想:将模型的推理轨迹(Trajectory)看作是在损失曲面上寻找最优解的路径。
基于上述视角,RePro设计了一套过程奖励机制,直接嵌入到RLVR(如PPO,GRPO)流程中。
RePro设计了一个可计算的“目标函数J”,用于量化模型当前的置信度。具体来说:
模型在当前推理上下文下,生成正确答案各个token的平均对数概率。
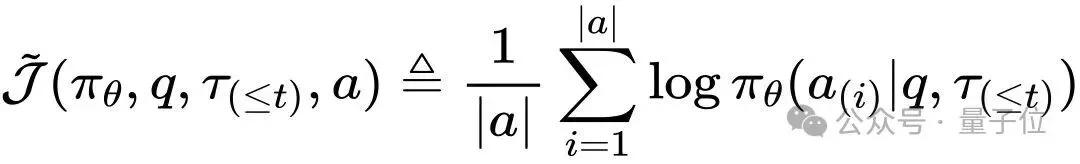
直觉解释:
这个指标越高,说明模型越“自信”答案正确,是一个合理的优化代理指标。
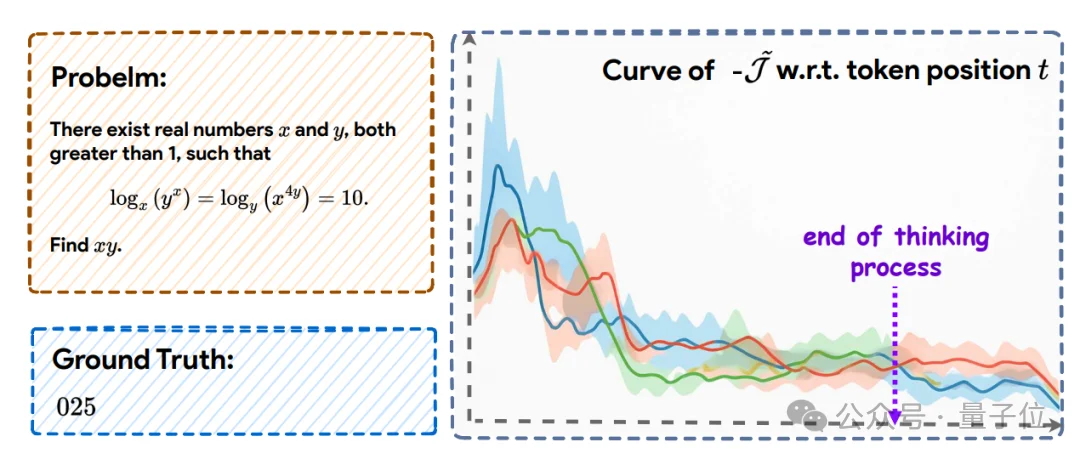
团队发现,正确的推理路径上,J̃会平稳上升,而“胡思乱想”的路径则震荡或停滞。
为了量化推理质量,RePro将J̃的变化拆解为两个维度:
基于代理目标函数,REPRO将推理矫正形式化为:在推理轨迹上最大化目标函数J̃的增长速率与增长平滑性的双重优化问题。
相较于传统强化学习仅关注最终结果(Outcome Reward)的稀疏反馈机制,REPRO引入了过程感知的轨迹优化范式:
强度不足(如梯度消失或步长过小)对应增长速率惩罚稳定性差(如优化振荡)对应平滑性惩罚高效下降则同时满足高增长率与高稳定性,获得正向激励
该方法鼓励模型生成逻辑连贯且语义收敛的推理链。

基于J序列,RePro引入了两个评分:
Magnitude Score(强度评分):衡量目标函数的提升幅度
强度评分Smagn旨在回答一个问题:这一段思考,到底让模型离答案近了多少
在优化理论中,梯度的大小决定了下降的快慢。在推理中,这意味着一段有效的CoT应该显著提升模型对答案的信心。REPRO通过比较当前步骤后的目标函数值J̃与基线值J̅(即不进行任何思考直接回答的信心)来计算这一增益。
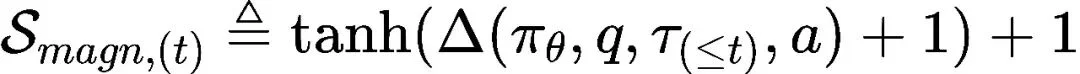
其中,Δ代表相对增益:

这里使用tanh函数的目的是将分数归一化到(0,1]区间。在实际训练中,某些步骤可能会导致对答案的信心指数级暴涨(例如终于算出了关键中间变量),如果不加限制,这种巨大的奖励信号可能会导致梯度爆炸或训练不稳定。
Stability Score(稳定性评分):衡量J是否平滑上升
稳定性评分Sstab旨在回答另一个问题:这段思考的过程是顺畅的,还是充满了犹豫和反复?
如果将J̃的变化看作一条曲线,理想的推理应该是一条单调上升的曲线。如果曲线上下波动,说明模型陷入了自我怀疑或逻辑混乱。为了量化这种“波动”,RePro利用了Kendall’s Tau相关系数。
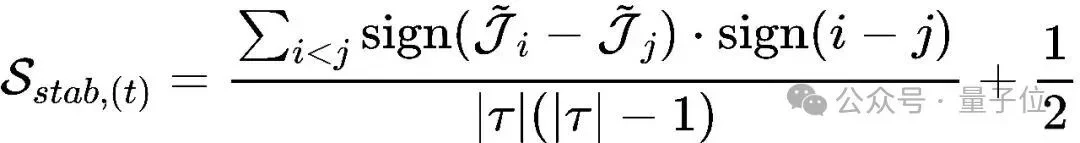
这一公式计算的是J̃值序列与时间步序列{1,…,t}之间的秩相关性。
高稳定性(接近1):每一步的J̃值都比前一步高,这表明模型每一步都在进步,没有回撤。这对应于优化过程中沿着最速下降方向的平滑移动。
低稳定性(接近0或负值):序列杂乱无章,进两步退一步,甚至出现严重的逻辑倒退。这对应于模型在鞍点附近的随机摆动,消耗了步数(Token)但未取得实质进展。
Magnitude Score和Stability Score两者加权构成最终过程评分S,可用于判断某段思维路径是否值得强化或惩罚。
直接为每个token打分代价太高,于是RePro采用熵值筛选策略:
分段:将推理链按逻辑段落(如换行符\n\n)分割为{c1, c2,…, cN}。
熵计算:计算每个段落首Token的熵ℋ(ci,(0))。
Top-k筛选:只选择熵最高的前k个段落(Top-k Segments)进行REPRO奖励计算。
这种策略不仅大幅降低了计算开销(从全序列计算变为只计算k个点),还起到了“好钢用在刀刃上”的效果——只在模型最迷茫、最关键的时刻给予指引,而在其自信流畅的时刻(低熵区域)保持静默,避免过度干预。
然后,通过计算过程评分的提升量ΔS,作为这一片段的“过程级奖励”,与最终正确与否结合,作为RL的优势函数输入。
这种方法既高效又精准,能引导模型在关键决策点生成更优推理。
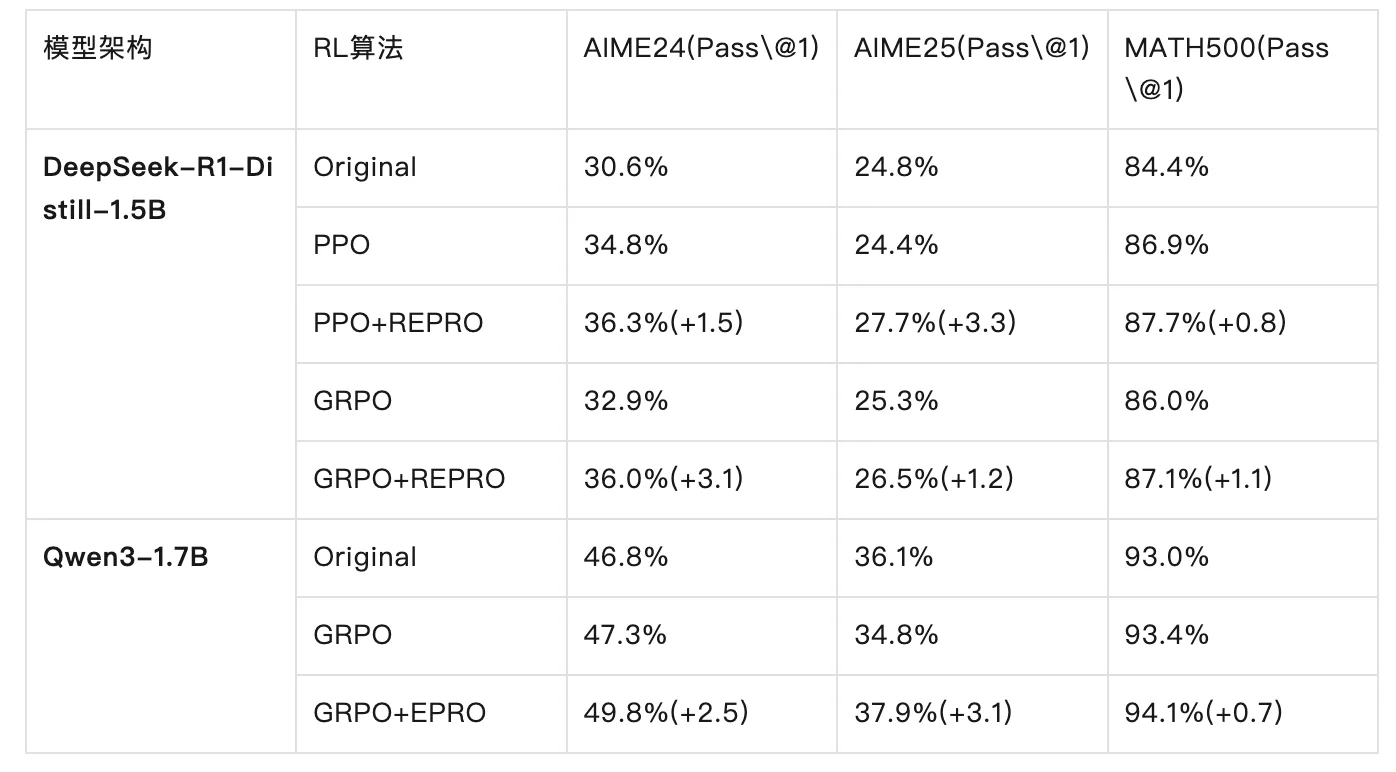
RePro在数学、科学、编程等多个任务上进行了广泛实测,包括:
并在以下模型上进行训练测试:
在所有RL算法(PPO、REINFORCE++、GRPO)下,RePro都带来了稳定提升。
并且,这种改进不仅出现在数学任务,在科学和代码任务上也有类似表现,表明RePro具备良好的泛化能力。
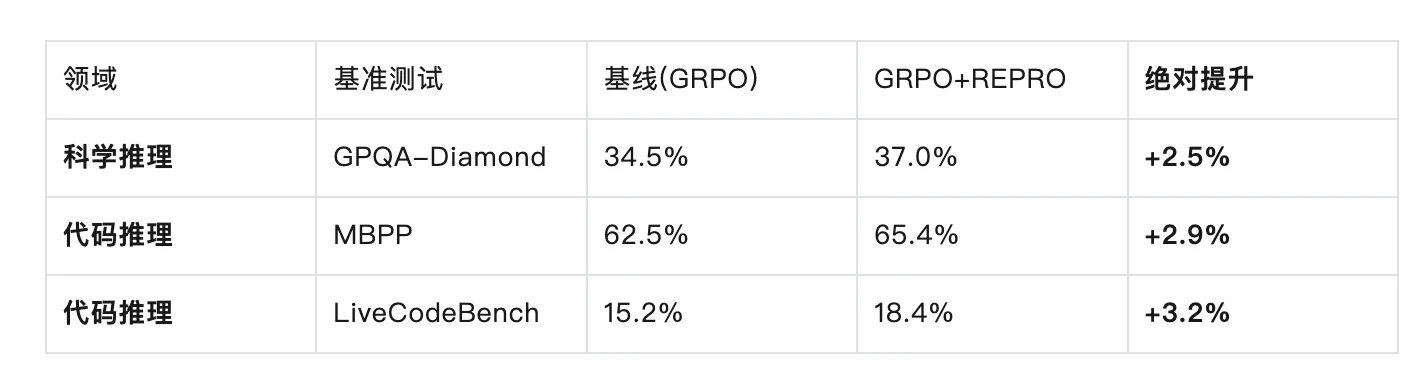
除了准确率,它还提升了哪些关键指标?
随着训练进行,RePro模型生成的平均token数量稳步下降:
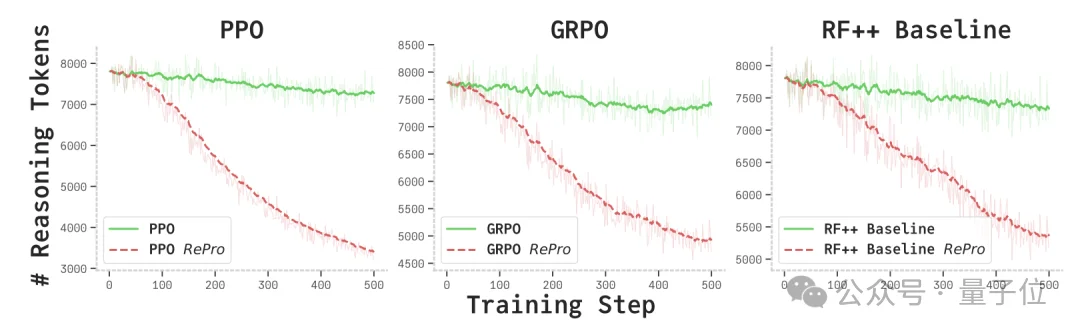
这意味着模型学会了少说废话,在更短的路径内给出更准的答案。
Re+Pro模型在推理过程中出现的“反复检查”或“思路绕圈子”的比例显著下降。
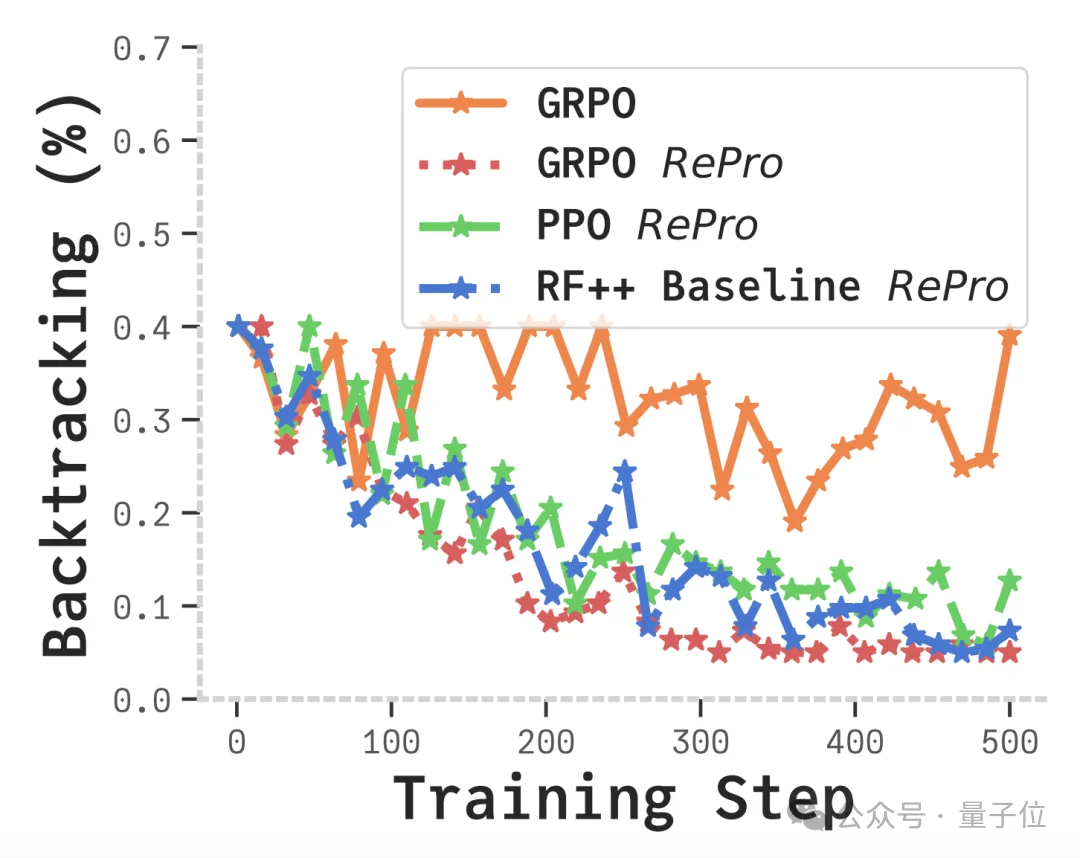
RePro的成功证明了:更好的推理不一定需要更长的CoT,而是需要更“有效”的优化路径。
通过将Optimization Lens(优化视角)引入后训练阶段,RePro为解决Long CoT的效率瓶颈提供了一个优雅且通用的解法。它告诉大模型:不仅要算对,还要算得漂亮。
论文:https://arxiv.org/abs/2512.01925
Github:https://github.com/open-compass/RePro
文章来自于微信公众号 “量子位”,作者 “量子位”



