# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!
目前,模型、代码均已开源,4 步编辑一条视频,训练数据 VideoCoF-50k 预计本周内开源!


在 AIGC 时代,视频编辑已经有了长足进步,但仍存在一个明显的痛点:
能不能既要高精度,又不要 Mask?
VideoCoF 给出了肯定的答案。
VideoCoF 的核心灵感来自于大语言模型(LLM)中的思维链(Chain-of-Thought)。研究团队认为,视频生成模型也应该具备类似的推理能力。
为此,他们提出了 Chain of Frames (CoF) 机制,将视频编辑过程重构为三个阶段:

这种显式的推理过程,让模型学会了主动建立编辑指令与画面区域的对应关系,从而实现了无需 Mask 的高精度编辑。

除了推理能力,视频编辑的另一个难题是长度限制。很多模型只能编辑短视频,一旦视频变长,动作就会变形或崩坏。
VideoCoF 引入了独特的 RoPE(旋转位置编码)对齐策略:
这意味着,你用极小的成本训练出的模型,可以在推理时处理远超训练长度的视频,且保持动作流畅、无纹理突变和伪影。

除了架构设计的精妙,VideoCoF 最令人印象深刻的当属其惊人的数据效率。
为了验证效果,研究团队构建了一个包含添加、删除、替换及风格迁移的高质量实例级数据集,并在 VideoCoF-Bench 上进行了严格测评。
尽管训练数据量仅为基线的 1/20,VideoCoF 却实现了性能的反超:
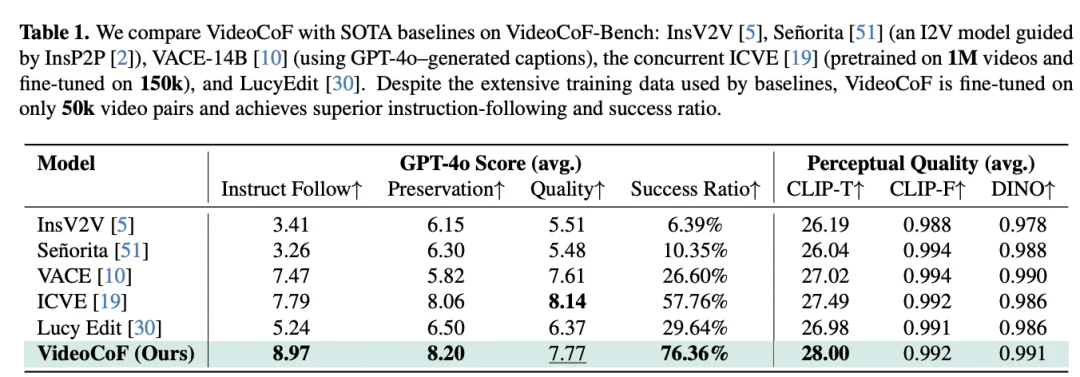
VideoCoF 的核心在于「先推理,再编辑」。那么,如果去掉推理帧,直接让模型硬算,效果会怎样?
研究团队进行了详细的消融实验(Ablation Study)。结果显示,相比于没有推理环节的 Naive Temporal in Context 基线:
这有力地证明了:显式的时序推理(See-Reason-Edit)不仅是锦上添花,更是实现高精度视频编辑的关键。
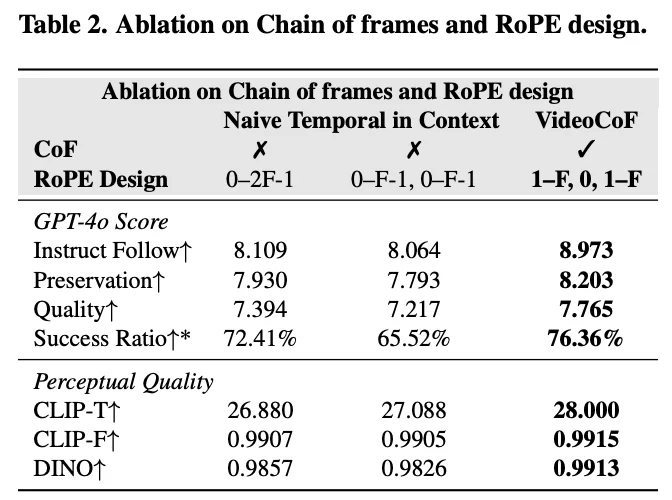
除了「要不要推理」,VideoCoF 团队还深入研究了「推理帧到底该长什么样」,是像分割模型那样用黑白掩码?还是像圈图那样用红圈?
在 Table 3 的消融实验中,团队对比了三种形式:
最终杀器:渐变灰 (Progressive Gray) 。VideoCoF 发现,推理帧不应只是一个静态的「定位图」,而应充当从「源视频」到「编辑视频」的时序过渡桥梁。
因此,团队设计了一种透明度渐变(如 0% → 25% → 50% → 75%)的灰色掩码。这种设计不仅明确了「哪里要改」,更给模型一种「变化正在发生」的动态暗示。
实验结果(Table 3)显示,相比于静态的红 / 黑掩码,渐变灰设计直接将指令遵循得分(Instruct Follow)从 7.5/7.8 拉升到了 8.97,证明了细节设计对模型性能的巨大影响。
VideoCoF 展现了强大的通用编辑能力,无论是增删改查,还是局部风格迁移,都能精准搞定:

VideoCoF 是一项通过「时序推理」统一视频编辑任务的开创性工作。它不仅解决了无 Mask 编辑的精度问题,还通过高效的数据利用(仅 50k 样本)和巧妙的 RoPE 设计,实现了低成本、高性能、长视频支持的视频编辑。对于社区而言,VideoCoF 证明了 Better Reasoning > More Data,为未来的视频生成与编辑研究提供了新的思路。
文章来自于“机器之心”,作者 “UTS 博士生杨向鹏”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
