# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
做agent简单,但是做能落地的agent难,做能落地的长周期agent更是难上加难!
这是不是你搞agent开发时的常态?
长周期 Agent落地失效,通常来说,会分两类典型模式:
第一种发生在任务初期:收到“搭建类 claude.ai 的 Web 应用”这类高阶指令后,采用贪心策略一次性推进全量开发,执行中逐步丢失上下文,最终在功能开发半途耗尽上下文窗口;后续新实例面对无进度文档的半成品代码库,需要耗费大量精力梳理复盘,才能恢复应用基础功能。
第二种发生在项目中后期:已有部分功能落地后,新 Agent 因缺乏全局目标认知,仅看到局部功能可用便过早判定任务完成,忽略大量未实现的功能模块。
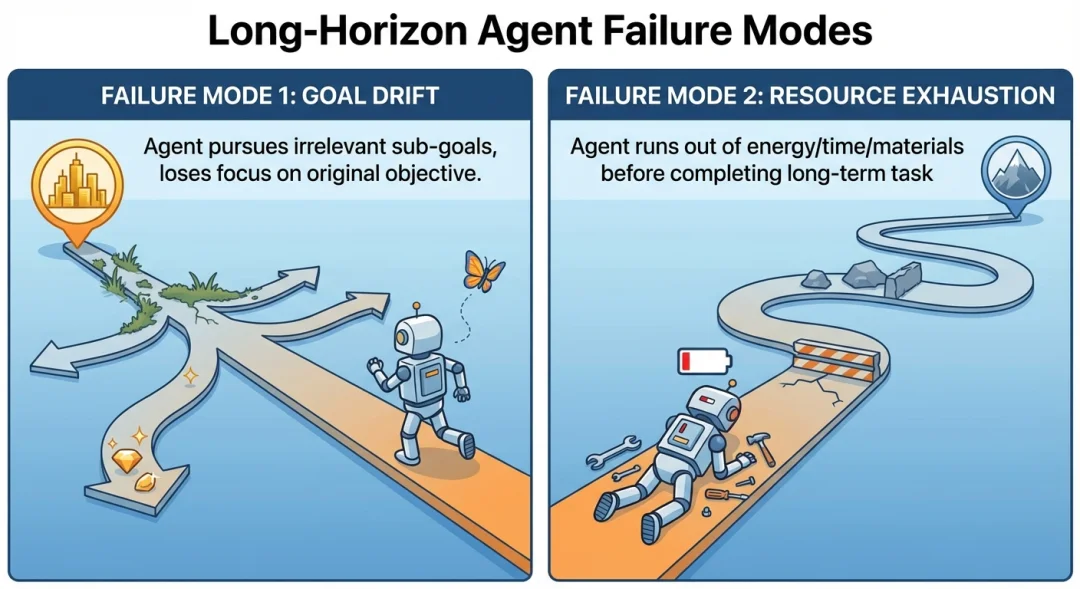
表面上看,这两种失效模式发生在项目的不同阶段、表现形式也截然不同,但深挖本质就会发现,其核心原因完全一致:Agent无法准确确认任务切分的粒度,进而导致多个会话间的上下文传递出现断裂或偏差。
既然找到了问题的根源,那么该如何针对性解决这一核心痛点?
本文将从架构设计、状态恢复、功能验证三个核心维度,详细介绍如何通过双Agent架构、基于文件与向量数据库的状态恢复机制,以及测试驱动的功能验证,系统性破解长周期Agent的落地难题。
要解决任务切分粒度不准和上下文传递失效的问题,首先需要从架构层面搭建清晰的分工机制。
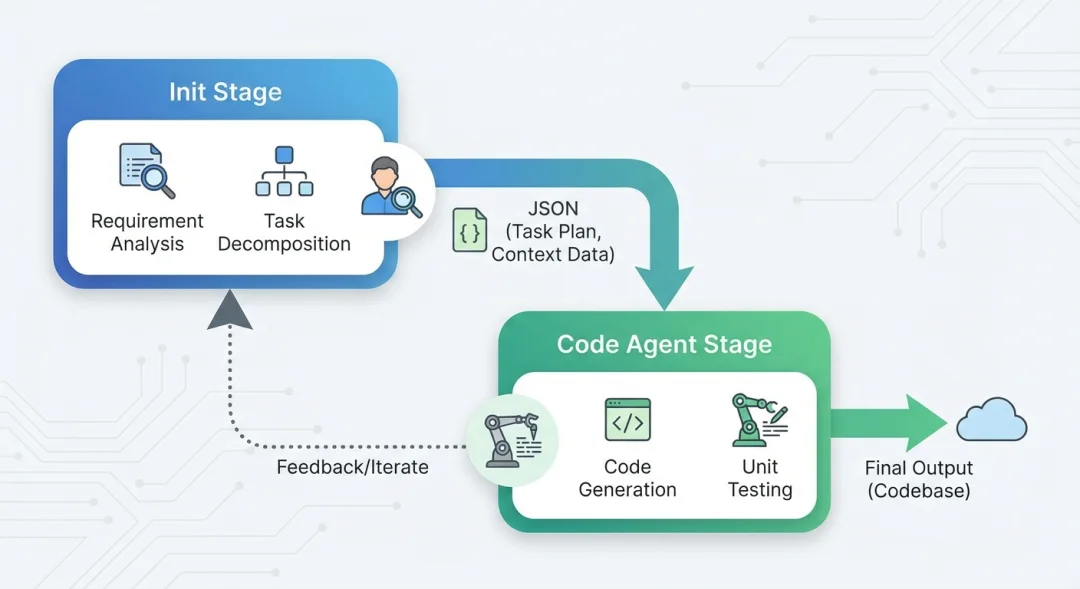
不久前,Anthropic 发布了一套双 Agent 架构方案,这套方案由两个agent组成:Initializer Agent + Coding Agent。
其中,Initializer Agent的核心职责是“当领导”,负责统筹全局,具体需要完成三件核心工作:
第一是任务拆解,即把用户的高级需求精准展开为具体的、可验证的功能点。以claude.ai克隆项目为例,Initializer Agent不会停留在构建一个对话应用这种模糊表述上,而是会将其细化为200多项具体功能,每一项都清晰描述了用户可执行的具体操作和对应的预期结果,让后续开发有明确的执行标准;
第二是进度跟踪,通过创建进度追踪文件,实时记录每个功能的完成状态,让开发进度可视化,避免出现局部完成即判定整体结束的误判;
第三是环境搭建,编写初始化脚本(init.sh),提前配置好开发所需的基础环境,确保后续Coding Agent能快速启动开发,无需在环境配置上耗费额外精力。
与Initializer Agent的统筹角色相对应,Coding Agent的职责是充当“专家”,在Initializer Agent的指挥下聚焦具体功能的落地执行。
其核心工作逻辑是增量迭代:每轮会话只选择一个功能进行实现,完成后先进行充分测试,再用描述性的提交信息将代码提交到Git,同步更新进度文件,最后结束会话,,从根本上避免了半成品代码堆积和上下文丢失的问题。
需要特别注意的是,进度追踪列表的格式选择对Agent的执行效率影响极大。这里更推荐采用JSON格式,尽量不要用Markdown格式,因为模型在编辑JSON时更倾向于精准修改特定字段,但处理Markdown时容易产生意外的格式变化或整体重写。这种差异在处理包含数百个功能项的大型列表时会尤为明显,可能直接导致进度追踪失效。
一个标准的功能项JSON结构如下:
{
"category": "functional",
"description": "New chat button creates a fresh conversation",
"steps": [
"Navigate to main interface",
"Click the 'New Chat' button",
"Verify a new conversation is created",
"Check that chat area shows welcome state",
"Verify conversation appears in sidebar"
],
"passes": false
}
这种结构化格式让 Agent 能够清晰地理解每个功能的范围和验证标准,同时通过 passes 字段追踪完成状态,为跨会话的进度衔接提供可靠依据。
在解决了任务切分和增量开发的问题后,另一个影响长周期Agent落地的关键痛点在于:跨会话的状态恢复与经验复用。
起初,基于进度文件与Git的状态恢复机制在项目初期能正常运行,但随着项目规模扩大,三类问题会逐渐凸显:一是Git历史提交次数超过数百次后,线性扫描的效率会大幅下降,无法快速定位关键信息;二是基于文本的查找只能匹配关键词,无法理解“JWT刷新令牌”与“用户认证”这类语义关联,导致历史经验无法有效复用;三是各项目的经验被孤立存储,无法跨项目迁移复用,增加了重复开发成本。
向量数据库通过语义检索解决了这些问题。
其核心逻辑是将进度记录、Git提交信息等历史数据转换为向量嵌入,当Agent需要查询历史信息时,只需输入查询语句,向量数据库就能在毫秒级响应时间内找到语义相关的内容。
在这一场景中,Milvus数据库的优势尤为突出:一方面,Milvus Lite支持轻量化部署,可像SQLite一样直接嵌入应用,无需复杂的集群配置;另一方面,我们也可以采用Milvus的docker、k8s版本,全都原生支持主流的嵌入模型API,且通过TextEmbedding功能,Agent无需手动处理向量生成,直接用自然语言查询语句就能检索历史记录,大幅降低了使用门槛。
即便解决了任务切分和记忆复用问题,长周期Agent仍可能因功能验证不充分导致落地失效。
因为,很多时候,Agent在实现功能后,仅通过简单的代码测试或curl命令测试就标记功能完成,但这类测试往往无法覆盖真实使用场景,很容易遗漏实际应用中的问题——这一痛点在Web应用开发中尤为明显。
要解决这一问题,可以让Agent使用浏览器自动化工具进行端到端测试。对于Web应用而言,就是通过Puppeteer等工具,模拟真实用户的操作流程:打开页面、点击按钮、填写表单、检查页面元素等,只有当功能通过这种全流程的真实场景测试后,Agent才能将其标记为完成。
这种测试方式让 Agent 能够发现仅从代码层面无法察觉的问题。比如一个对话功能,代码逻辑可能完全正确,API 返回也符合预期,但在浏览器中可能因为 CSS 问题导致用户看不到回复内容。通过浏览器自动化测试,Agent 可以截图验证页面显示是否符合预期,从而发现这类问题。
但这种方法也有局限性。某些浏览器原生功能,特别是系统级弹窗(如确认对话框、文件选择器),无法被 Puppeteer 这样的自动化工具访问。依赖这些原生弹窗的功能往往更容易出现测试盲区。在设计应用时需要考虑这一点,尽量使用可测试的自定义 UI 组件替代原生弹窗。
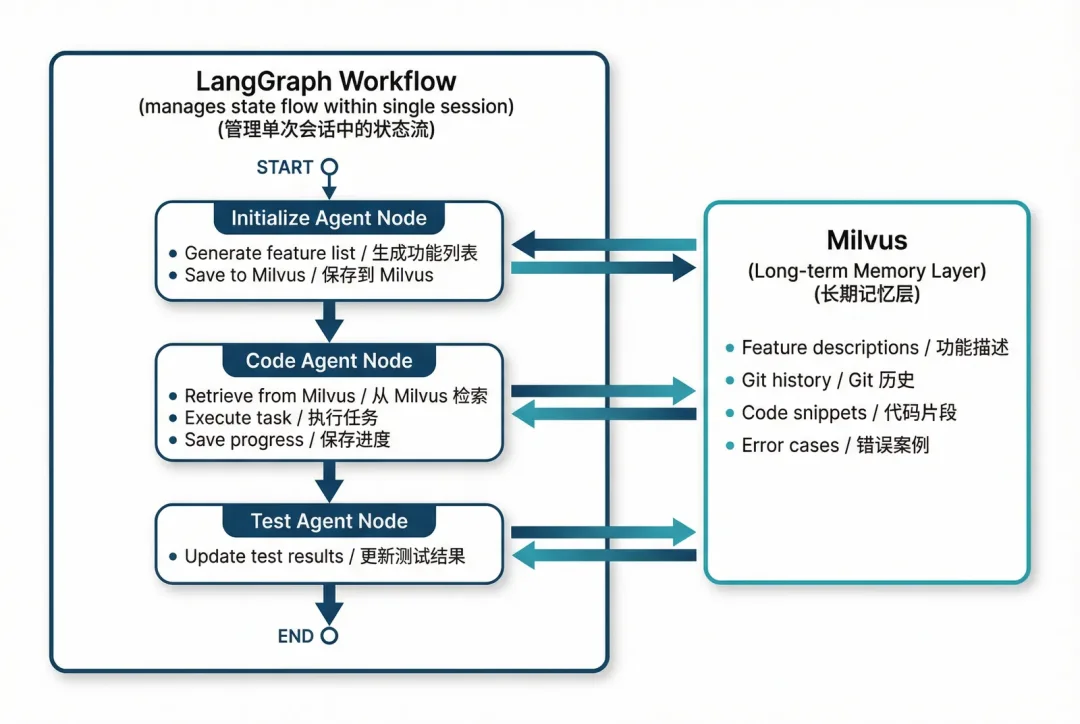
为了让上述方案总结更容易理解,下面通过一个实操示例,展示如何通过LangGraph和Milvus的协同,实现长周期任务重,双Agent的状态管理与记忆复用。
该示例的核心逻辑是“短期记忆+长期记忆”的协同工作:LangGraph的检查点机制负责维护单个会话内的状态一致性,确保会话内的开发流程不中断;当需要跨会话查询历史信息时,由Milvus提供语义检索支持,帮助Agent快速恢复上下文,彻底避免从零开始的冷启动问题。
from sentence_transformers import SentenceTransformer
from pymilvus import MilvusClient
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, Annotated
import operator
import subprocess
import json
# ==================== 初始化 ====================
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
milvus_client = MilvusClient("./milvus_agent_memory.db")
# 创建集合
if not milvus_client.has_collection("agent_history"):
milvus_client.create_collection(
collection_name="agent_history",
dimension=384,
auto_id=True
)
# ==================== Milvus操作函数 ====================
def retrieve_context(query: str, top_k: int = 3):
"""从Milvus检索相关历史(核心要素:语义检索)"""
query_vec = embedding_model.encode(query).tolist()
results = milvus_client.search(
collection_name="agent_history",
data=[query_vec],
limit=top_k,
output_fields=["content"]
)
if results and results[0]:
return [hit["entity"]["content"] for hit in results[0]]
return []
def save_progress(content: str):
"""保存进度到Milvus(长期记忆)"""
embedding = embedding_model.encode(content).tolist()
milvus_client.insert(
collection_name="agent_history",
data=[{"vector": embedding, "content": content}]
)
# ==================== 核心要素1:Git提交 ====================
def git_commit(message: str):
"""Git提交(原文核心要素)"""
try:
# 实际项目中会执行真实的Git命令
# subprocess.run(["git", "add", "."], check=True)
# subprocess.run(["git", "commit", "-m", message], check=True)
print(f"[Git提交] {message}")
return True
except Exception as e:
print(f"[Git提交失败] {e}")
return False
# ==================== 核心要素2:测试验证 ====================
def run_tests(feature: str):
"""执行测试(原文强调的端到端测试)"""
try:
# 实际项目中会调用Puppeteer等测试工具
# 这里简化为模拟测试
print(f"[测试验证] 正在测试功能: {feature}")
# 模拟测试结果
test_passed = True # 实际会根据测试结果返回
if test_passed:
print(f"[测试通过] {feature}")
return test_passed
except Exception as e:
print(f"[测试失败] {e}")
return False
# ==================== 状态定义 ====================
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
features: list# 所有功能列表
completed_features: list # 已完成功能
current_feature: str # 当前正在处理的功能
session_count: int # 会话计数器
# ==================== 双Agent节点 ====================
def initialize_node(state: AgentState):
"""初始化Agent:生成功能列表和工作环境"""
print("\n========== 初始化Agent启动 ==========")
# 生成功能列表(实际会根据需求生成详细的功能清单)
features = [
"实现用户注册功能",
"实现用户登录功能",
"实现密码重置功能",
"实现用户资料编辑",
"实现会话管理功能"
]
# 保存初始化信息到Milvus
init_summary = f"项目初始化完成,生成{len(features)}个功能点"
save_progress(init_summary)
print(f"[初始化完成] 功能列表: {features}")
return {
**state,
"features": features,
"completed_features": [],
"current_feature": features[0] if features else "",
"session_count": 0,
"messages": [init_summary]
}
def code_node(state: AgentState):
"""编码Agent:实现、测试、提交(核心循环节点)"""
print(f"\n========== 编码Agent会话 #{state['session_count'] + 1} ==========")
current_feature = state["current_feature"]
print(f"[当前任务] {current_feature}")
# ===== 核心要素3:从Milvus检索历史经验(跨会话记忆) =====
print(f"[检索历史] 查询与'{current_feature}' 相关的历史经验...")
context = retrieve_context(current_feature)
if context:
print(f"[检索结果] 找到 {len(context)} 条相关记录:")
for i, ctx in enumerate(context, 1):
print(f" {i}. {ctx[:60]}...")
else:
print("[检索结果] 无相关历史记录(首次实现此类功能)")
# ===== 步骤1:实现功能 =====
print(f"[开始实现] {current_feature}")
# 实际会调用LLM生成代码
implementation_result = f"已实现功能: {current_feature}"
# ===== 步骤2:测试验证(核心要素) =====
test_passed = run_tests(current_feature)
if not test_passed:
print(f"[会话结束] 测试未通过,需要修复")
return state# 测试失败则不推进
# ===== 步骤3:Git提交(核心要素) =====
commit_message = f"feat: {current_feature}"
git_commit(commit_message)
# ===== 步骤4:更新进度文件 =====
print(f"[更新进度] 标记功能为已完成")
# ===== 步骤5:保存到Milvus长期记忆 =====
progress_record = f"完成功能: {current_feature} | 提交信息: {commit_message} | 测试状态: 通过"
save_progress(progress_record)
# ===== 步骤6:更新状态并准备下一个功能 =====
new_completed = state["completed_features"] + [current_feature]
remaining_features = [f for f in state["features"] if f not in new_completed]
print(f"[进度统计] 已完成: {len(new_completed)}/{len(state['features'])}")
# ===== 核心要素4:会话结束(明确的会话边界) =====
print(f"[会话结束] 代码库处于干净状态,可安全中断\n")
return {
**state,
"completed_features": new_completed,
"current_feature": remaining_features[0] if remaining_features else "",
"session_count": state["session_count"] + 1,
"messages": [implementation_result]
}
# ==================== 核心要素3:循环控制 ====================
def should_continue(state: AgentState):
"""判断是否继续下一个功能(实现增量循环开发)"""
if state["current_feature"] and state["current_feature"] != "":
return "code"# 继续执行下一个功能
else:
print("\n========== 所有功能已完成 ==========")
return END
# ==================== 构建工作流 ====================
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("initialize", initialize_node)
workflow.add_node("code", code_node)
# 添加边
workflow.add_edge(START, "initialize")
workflow.add_edge("initialize", "code")
# 添加条件边(实现循环)
workflow.add_conditional_edges(
"code",
should_continue,
{
"code": "code",# 继续循环
END: END# 结束
}
)
# 编译工作流(使用MemorySaver作为检查点器)
app = workflow.compile(checkpointer=MemorySaver())
# ==================== 使用示例:演示跨会话恢复 ====================
if __name__ == "__main__":
print("=" * 60)
print("演示场景:长周期Agent的多会话开发")
print("=" * 60)
#===== 会话1:初始化 + 完成前2个功能 =====
print("\n【场景1】第一次启动:完成前2个功能")
config = {"configurable": {"thread_id": "project_001"}}
result = app.invoke({
"messages": [],
"features": [],
"completed_features": [],
"current_feature": "",
"session_count": 0
}, config)
print("\n" + "=" * 60)
print("【模拟场景】开发者手动中断(Ctrl+C)或上下文窗口耗尽")
print("=" * 60)
# ===== 会话2:从checkpoint恢复状态 =====
print("\n【场景2】新会话启动:从上次中断处继续")
print("通过相同的thread_id,LangGraph自动恢复checkpoint...")
# 使用相同的thread_id,LangGraph会自动从checkpoint恢复状态
result = app.invoke({
"messages": [],
"features": [],
"completed_features": [],
"current_feature": "",
"session_count": 0
}, config)
print("\n" + "=" * 60)
print("演示完成!")
print("=" * 60)
print("\n关键要点:")
print("1. ✅ 双Agent架构(initialize + code)")
print("2. ✅ 增量循环开发(条件边控制循环)")
print("3. ✅ Git提交(每个功能完成后提交)")
print("4. ✅ 测试验证(端到端测试)")
print("5. ✅ 会话管理(明确的会话边界)")
print("6. ✅ 跨会话恢复(thread_id + checkpoint)")
print("7. ✅ 语义检索(Milvus长期记忆)")
此前,市面上的agent方案中,多采用单一Coding Agent处理所有编码相关任务,但在真实的软件开发流程中,不同阶段的需求差异极大。
因此需要多 Agent 专业分工:测试 Agent 关注边界条件,质量保证 Agent 负责架构检查,清理 Agent 处理重构和文档。每个 Agent 针对专门领域优化提示和工具集,通过结构化接口协作,就像真实的开发团队。
值得注意的是,这套方案的核心原则:结构化初始环境、增量式进展、状态追踪、验证测试,并非仅适用于软件开发场景,还可迁移到其他长周期任务中:例如科学研究中的数周连续实验、金融建模中的多步骤复杂计算、法律文档的多轮迭代审查等。
随着向量数据库技术的成熟和多Agent框架的完善,让AI可靠完成复杂长周期任务,已经从理论探索逐步进入工程实践阶段,未来将释放更多生产力价值。

Zilliz黄金写手:尹珉
文章来自于“Zilliz”,作者 “尹珉”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
