# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天还是聊聊生产级agent怎么搭这回事。
前面几期内容,我们聊了agent 常见的坑有哪些,memory怎么管理,还有一些rerank细节,今天从部署层面看看怎么选一个不错的agent框架。
现如今,针对复杂场景,多agent架构已经成为默认选择,相应的框架也已经数不胜数,但它们多多少少都存在两个问题,要么重demo,轻生产,稳定性有待提升;要么过于灵活,导致在需要快速交付、迭代的场景中,略显笨重。
针对这个问题,国产框架Agno 靠着高性能,以及快速落地生产,短短几个月,就拿下了30K+star。
那么它与LangGraph的区别是什么?怎么将其快速在生产环境部署?
本文将一一解答。
Agno是专为生产环境设计的多智能体框架。它的架构分为两层:Agno框架层负责定义智能体的逻辑,AgentOS运行时层负责把这些逻辑变成可对外服务的HTTP接口。
其中,Agno框架层提供了三个核心抽象:Agent(智能体单元)、Team(多智能体协同)、Workflow(工作流编排)。开发者用纯Python代码定义智能体的能力、工具和知识源,框架负责LLM调用、工具执行、上下文管理。整个过程没有复杂的图编排,没有额外的DSL,都是直接的函数调用。
AgentOS运行时层则是生产部署的关键。它是异步优先、无状态的执行引擎,内置FastAPI集成,可以把本地开发的Agent直接转化为生产级HTTP服务。AgentOS提供了会话管理、流式响应、监控端点、水平扩展能力。开发者不需要自己写API层代码,也不需要考虑多线程和并发控制,AgentOS在底层已经处理好了这些问题。
整体的架构详情如下:
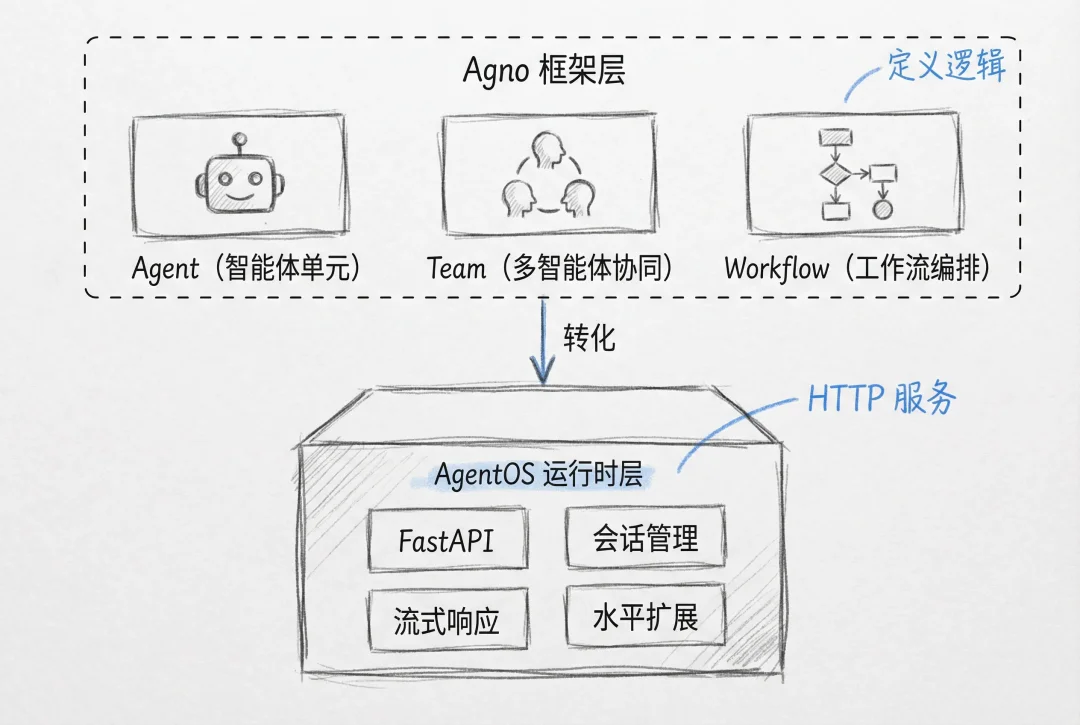
不难发现,与目前的主流多agent 框架LangGraph 相比,LangGraph 采用的是图状态机设计,将智能体系统建模为节点和边的组合,适合需要精确控制执行流程的场景。
Agno 则是独立的端到端解决方案,从框架层到运行时层提供完整的技术栈。开发者无需自行集成 API服务、会话管理和监控工具,AgentOS 已内置这些能力,强调的是快速从开发到生产的路径。
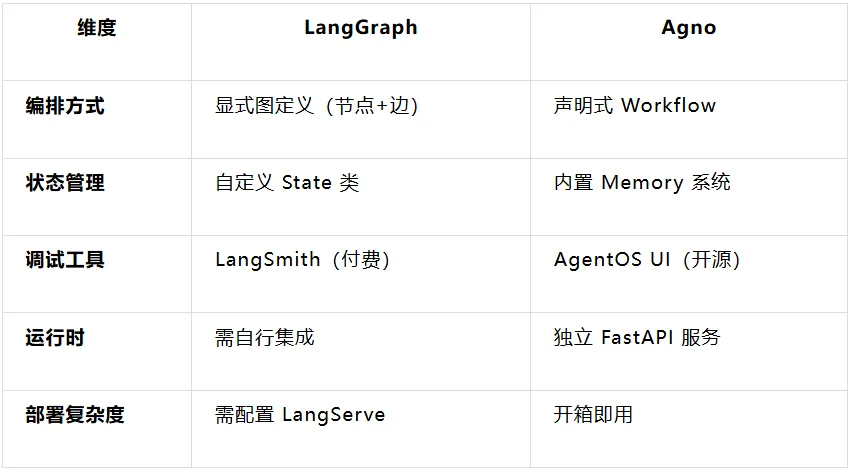
整体来看,LangGraph 重灵活控制,Agno 重快速交付。
在做选型时,我们可以根据项目阶段、技术栈和定制化需求权衡,必要时通过 POC 验证。
确定了框架层的选型后,在记忆层,我们依然推荐选择Milvus,主要出于几个考虑。
Agno官方文档提供了Milvus的一级集成,agno.vectordb.milvus模块封装了连接管理、嵌入生成、批量写入等生产必需的功能。相比需要自己处理连接池和错误重试的方案,原生支持大幅降低了集成成本。
Milvus还能提供三种部署模式(Lite/Standalone/Distributed),可以从本地文件(./milvus.db)逐步升级到分布式集群。虽然切换过程需要数据迁移和配置调整,但代码层面的API接口保持一致,对于需要快速验证原型、然后逐步扩展到生产的团队来说比较实用。

我们先用单Agent演示基础流程,然后在生产环境的关键设计部分展示如何扩展到多智能体协同。这个demo构建一个知识库助手,并通过AgentOS提供HTTP服务。
wget <https://github.com/Milvus-io/Milvus/releases/download/v2.5.12/Milvus-standalone-docker-compose.yml> -O docker-compose.yml
docker-compose up -d
docker-compose ps -a

import os
from pathlib import Path
from agno.os import AgentOS
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.knowledge.knowledge import Knowledge
from agno.vectordb.milvus import Milvus
from agno.knowledge.embedder.openai import OpenAIEmbedder
from agno.db.sqlite import SqliteDb
os.environ["OPENAI_API_KEY"] = "you-key-here"
data_dir = Path("./data")
data_dir.mkdir(exist_ok=True)
knowledge_base = Knowledge(
contents_db=SqliteDb(
db_file=str(data_dir / "knowledge_contents.db"),
knowledge_table="knowledge_contents",
),
vector_db=Milvus(
collection="agno_knowledge",
uri="http://192.168.x.x:19530",
embedder=OpenAIEmbedder(id="text-embedding-3-small"),
),
)
# 创建Agent
agent = Agent(
name="Knowledge Assistant",
model=OpenAIChat(id="gpt-4o"),
instructions=[
"你是一个知识库助手,帮助用户查询和管理知识库的内容。",
"使用中文回答问题。",
"在回答问题之前,始终先搜索知识库。",
"如果知识库为空,友好地提示用户上传文档。"
],
knowledge=knowledge_base,
search_knowledge=True,
db=SqliteDb(
db_file=str(data_dir / "agent.db"),
session_table="agent_sessions",
),
add_history_to_context=True,
markdown=True,
)
agent_os = AgentOS(agents=[agent])
app = agent_os.get_app()
if __name__ == "__main__":
print("\n🚀 启动服务...")
print("📍 http://localhost:7777")
print("💡 请在UI中上传文档到知识库\n")
agent_os.serve(app="knowledge_agent:app", port=7777, reload=False)
python knowledge_agent.py
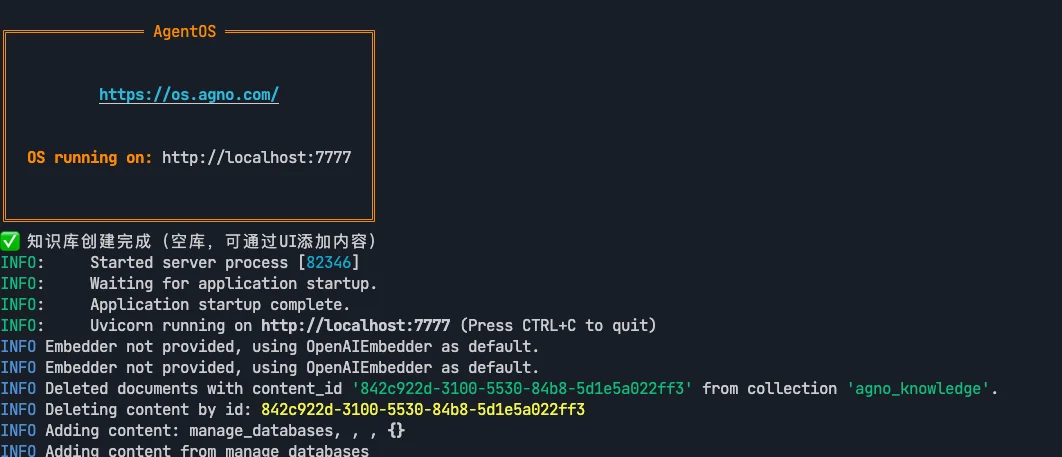
https://os.agno.com/
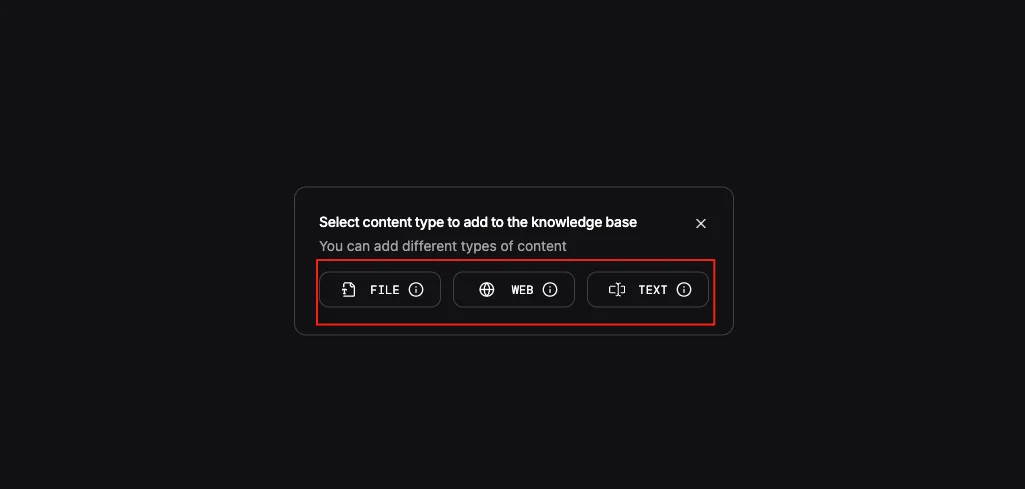
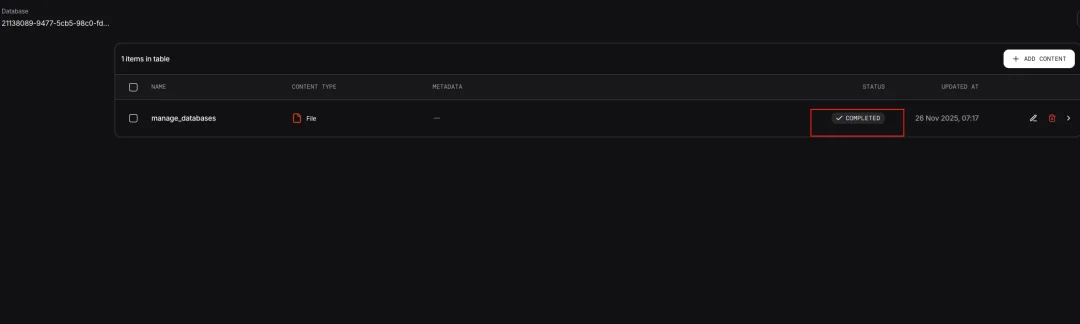
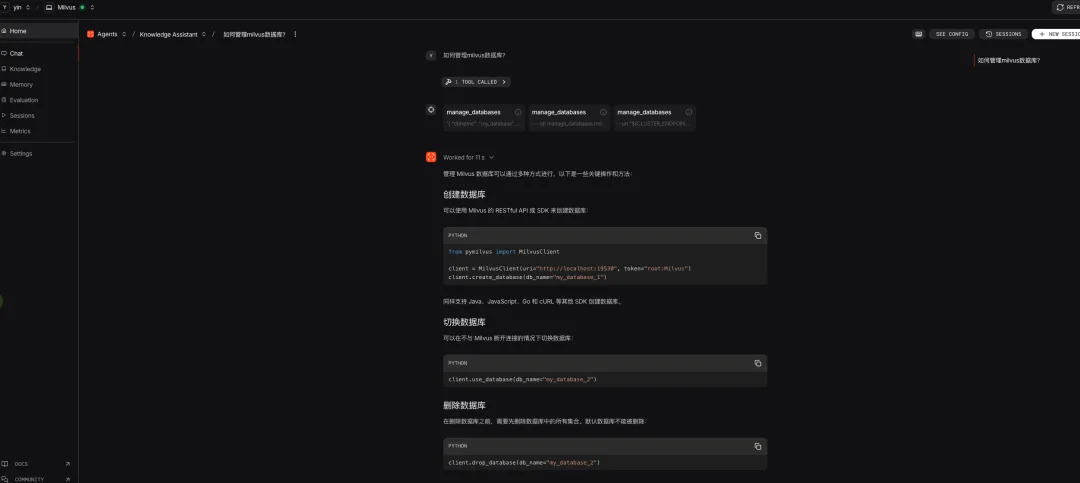
Milvus在这里的作用是提供高性能的语义检索能力。当知识库助手收到一个技术问题,它会通过search_knowledge工具把问题转换为向量,在Milvus中找到最相关的文档片段,然后基于这些片段生成回答。Milvus提供了三种部署模式,可以根据业务需求选择合适的方案,代码层面的接口保持一致。
上面的demo展示了基本用法,但如果要用于生产环境,还有几个架构层面的问题需要理解。
Agno的Team模式支持share_member_interactions=True配置,这会把前序智能体的完整交互历史传递给后续智能体。如果第一个智能体从Milvus检索了某些数据,后面的智能体可以直接使用,不需要重复检索。这有两个效果:检索成本被摊销(一次查询,多次使用),以及检索质量被放大(如果第一次查询的结果不准确,错误会在整个团队中传播)。所以在多智能体系统中,Milvus的检索准确率比单智能体场景更重要。
补充Team代码示例:
from agno.team import Team
analyst = Agent(
name="数据分析师",
model=OpenAIChat(id="gpt-4o"),
knowledge=knowledge_base,
search_knowledge=True,
instructions=["分析数据并提取关键指标"]
)
writer = Agent(
name="报告撰写者",
model=OpenAIChat(id="gpt-4o"),
knowledge=knowledge_base,
search_knowledge=True,
instructions=["基于分析结果撰写报告"]
)
team = Team(
agents=[analyst, writer],
share_member_interactions=True, # 共享知识检索结果
)
Agno的AgentOS是无状态的,可以水平扩展多个实例。会话历史存储在关系型数据库中,但这些是流程状态(谁说了什么)。真正的领域知识(向量化的文档、报告)完全存储在Milvus中。这种架构解耦的好处是:Agno层压力大了,加实例;Milvus压力大了,扩查询节点。两者互不影响,可以独立优化资源配置。Agno需要CPU和内存(LLM推理),Milvus需要磁盘I/O和GPU(向量计算),硬件需求也完全不同。
Agno本身有持续评估能力,但引入Milvus后需要扩展监控范围。实际运行中,你需要关注检索准确率(返回的文档是不是真的相关)、答案忠实度(回答是基于检索内容还是LLM瞎编的),以及端到端延迟的拆解——把总耗时分解到查询嵌入、向量检索、上下文构建、LLM推理这几个阶段,才能定位具体瓶颈。
监控这些指标的目的是及时发现系统退化。比如你的Milvus数据量从100万涨到1000万,如果发现检索延迟明显变长,就该考虑调整索引参数或者升级部署模式了。

Zilliz黄金写手:尹珉
文章来自于“Zilliz”,作者 “尹珉”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
