# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。

他们正式提出了递归语言模型(Recursive Language Models, RLM)。聚焦于如何在不重新训练模型的情况下,让现有的模型处理比其物理上下文窗口大几个数量级的信息?在此之前,业界解决长文本主要靠“硬抗”(做大显存、优化 Attention 算法,如Ring Attention)。RLM告诉大家:方向错了。对于超长、超复杂的任务,不要试图把所有东西塞进短期记忆(Context Window),而应该像人类一样,利用外部工具(Python 变量)和笔记,分而治之。
这或将成为2026年最热的方向,因为它太诱人了,这是一种与模型无关 (Model-Agnostic) 的方法。任何公司只要有现成的LLM,套上RLM的壳,就能立刻拥有处理1000万+token的能力。
新年第一个工作日,修猫将为您解读这篇论文。用最直观的逻辑带您理解:为什么RLM可能是2026年大模型应用架构的关键转折点。
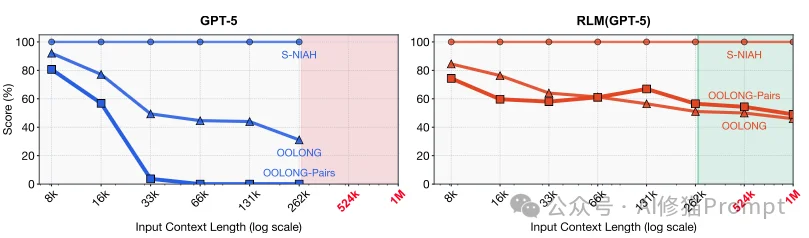
首先,我们需要达成一个共识:物理上的上下文窗口变大,并不等于模型的有效推理能力变强。
尽管现在的模型(如GPT-5)已经支持极长的上下文,但研究者指出,模型依然面临 “上下文腐烂”(Context Rot) 的问题。这就好比虽然能把整本书的内容塞进脑子里,但当书太厚时,开始记不住中间的细节,甚至产生幻觉。
这篇论文最精彩的洞察之一,是根据计算复杂度将长文本任务分为了三类。您会发现,传统的长上下文模型在面对高复杂度任务时,几乎是束手无策的:

RLM的设计哲学并非凭空产生,而是直接借鉴了计算机科学中经典的Out-of-core Algorithms(核外算法) 思想。

在传统的计算系统中,当数据集规模远超主存(RAM)容量时,我们不能一次性加载所有数据,而是需要设计算法,策略性地将磁盘(Disk)上的数据分块调入内存处理。
RLM将这一概念映射到了大模型推理中:
传统的Long-Context LLM试图通过线性偏置或Ring Attention等技术“扩容内存”。而RLM则是承认内存(注意力窗口)的局限性,转而通过符号化操作(Symbolic Interaction)来管理数据搬运。模型不再是被动接收所有token,而是作为CPU,主动决定何时从“磁盘”(变量)中读取哪些数据块进入“内存”(子模型上下文)。
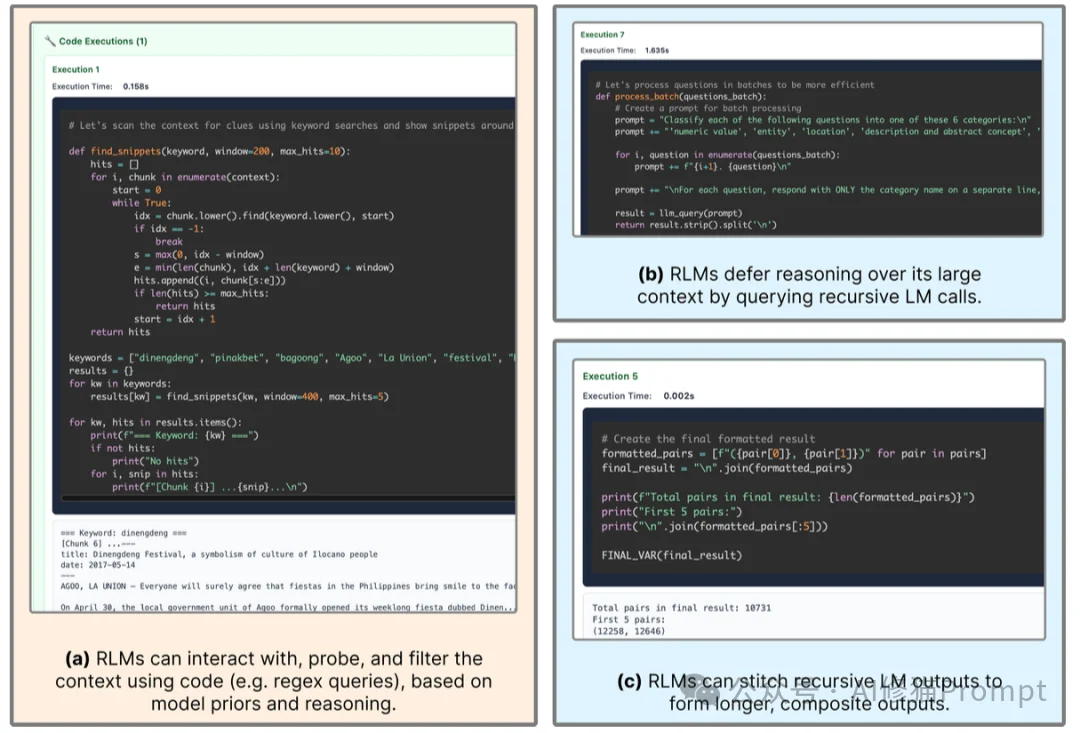
RLM的技术核心在于它构建了一个Read-Eval-Print Loop (REPL)环境,将自然语言推理转化为代码执行过程。将提示词视为环境的一部分。这就好比不再要求模型“背诵”整本书,而是让模型坐在书桌前,书桌上有一台装了Python环境的电脑。
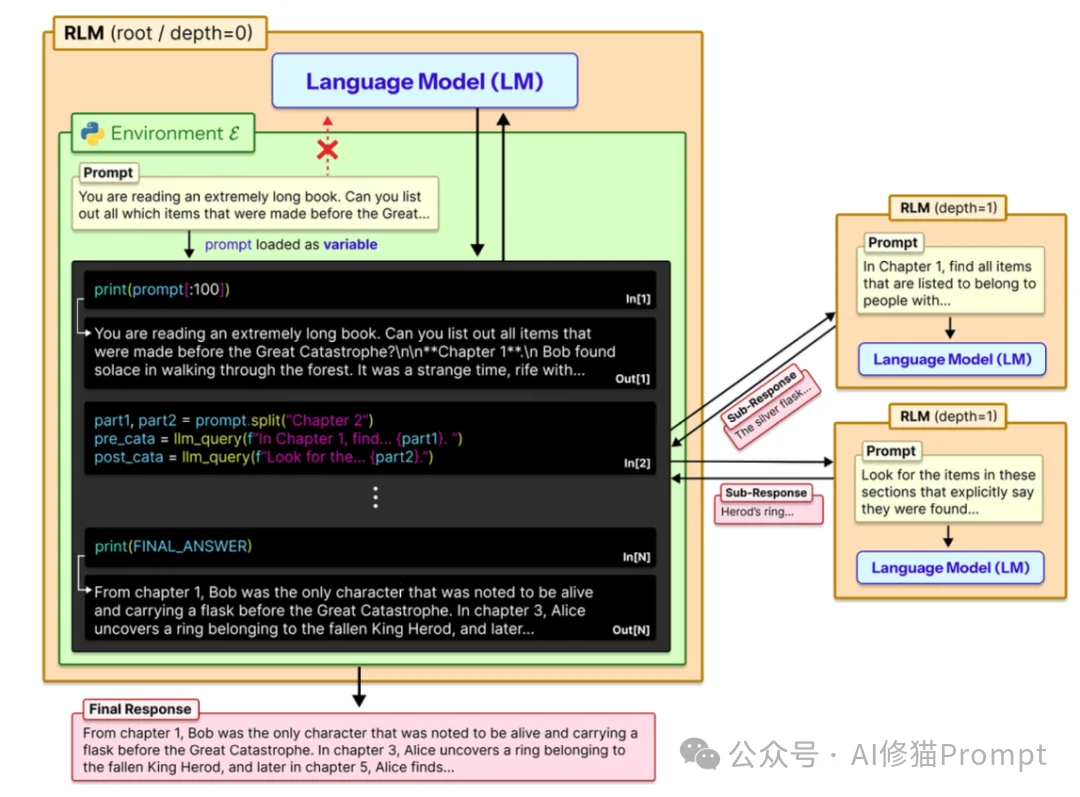

llm_query()
context 的切片加上特定的查询指令)。RLM的推理过程本质上是一个状态机。
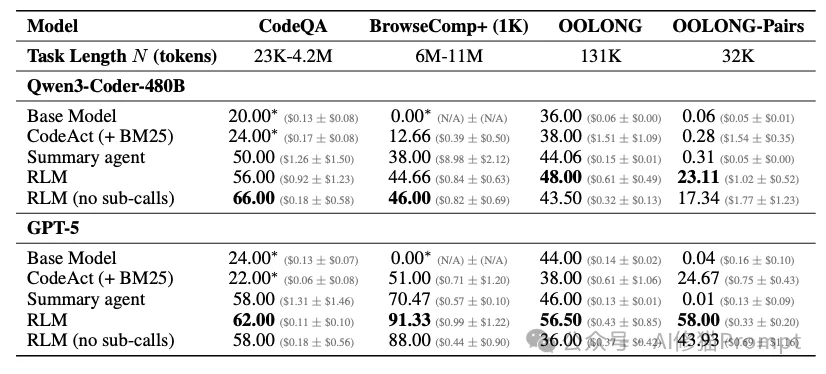
summary_list = [...]),会作为Python变量驻留在内存中。print() 函数将中间结果输出到标准输出流,RLM架构截获这些输出并将其回传给模型,形成“观察(Observation)”反馈。FINAL() 或 FINAL_VAR() 标签来封装最终答案,以此区分“思考过程”和“最终结论”。研究者使用了两个前沿模型进行测试:闭源的GPT-5和开源的Qwen3-Coder-480B。在高难度任务上,RLM获得了非常出色的表现。


您可能会担心:递归调用这么多次,成本会不会爆炸?
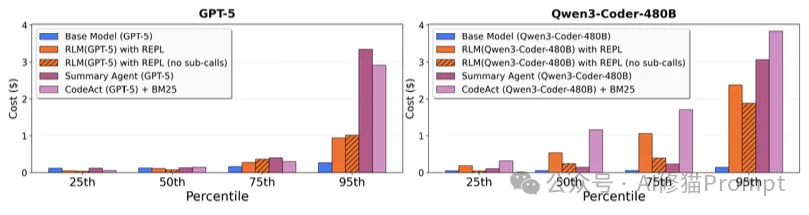
研究者的发现很有趣:
论文中对任务复杂度的形式化分析是理解RLM优势的关键。研究者提出,有效上下文窗口不能脱离任务复杂度独立讨论。
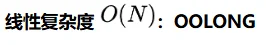
任务特征:需要对文本中的每一个块进行语义转换并聚合。

RLM解法:通过Python的 for 循环遍历切片。

这里,虽然总计算量仍是线性的,但单次LLM调用的上下文长度被压缩到了常数级,规避了长窗口下的注意力衰减。

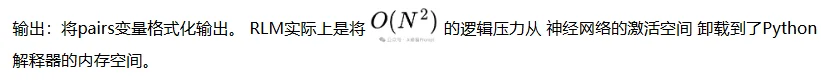
让研究者感到兴奋的,不是分数的提升,而是模型在没有经过任何微调(Fine-tuning)的情况下,仅通过Prompt Engineering(详见论文附录D)和环境交互,RLM就涌现出了类似高级工程师的调试行为。
在GPT-5的RLM轨迹中,观察到模型会利用“正则探针”来优化I/O。
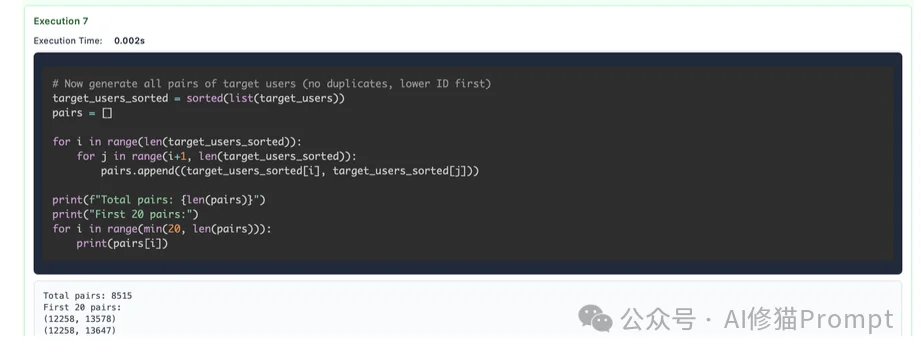
keywords = ["festival", "pageant"])。re.search 扫描 context 变量,仅提取命中位置前后的窗口(Window)文本。传统的RAG(检索增强生成)往往只能检索片段,容易丢失全局信息。而RLM通过Python变量,实现了动态分块与递归 (Dynamic Chunking),做到了信息的“无损传递”。它可以把前10万字总结成一个变量,传给处理后10万字的步骤,从而实现了真正的全文档理解。
\n 为分隔符。对于长输出任务(Long Generation),标准模型的最大输出token数往往受限。RLM通过将子结果存入List变量,最后利用Python的 "".join(results)函数将它们拼接成最终答案,一次性输出或分批输出,突破了Output Token Limit。
模型表现出了明显的“慢思考”特征。时在得出答案后,会不仅直接输出,而是再发起一个新的 llm_query,把刚才找到的证据喂回去,问子模型:“这个证据能支撑这个结论吗?”。
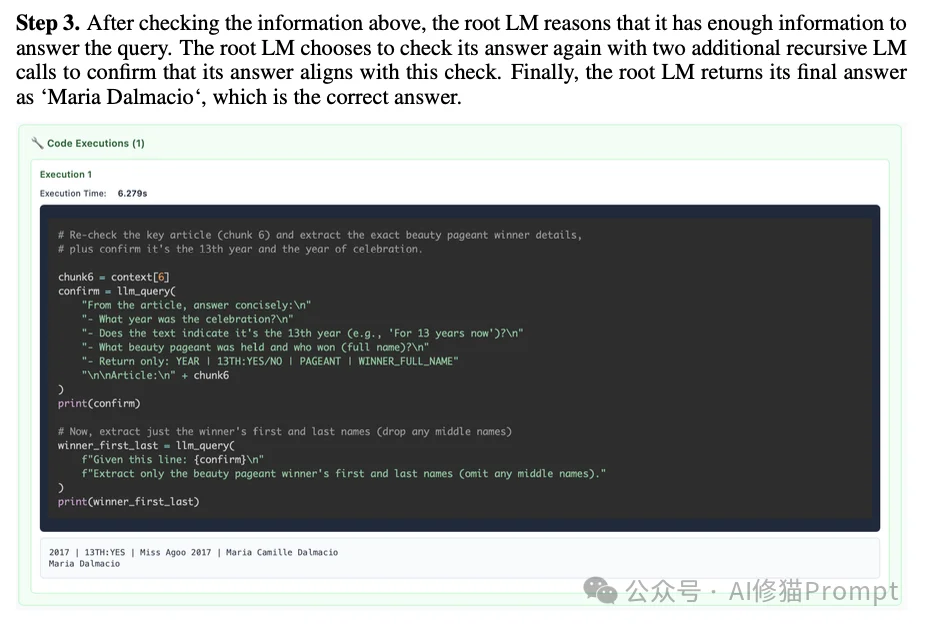
种自我验证机制有效地抵抗了长上下文中的幻觉问题。
尽管原理优雅,但作为2025年底发布的新技术RLM在当前的工程实现上仍存在明显瓶颈,这也是未来优化的方向。研究者诚实地列出了当前的局限性。
第一是速度问题
当前的实现是同步的(Sequential/Blocking)。当Root LM调用llm_query时,整个进程必须等待HTTP请求返回。在处理大规模分块任务(如处理1000个文档)时,这会导致极高的Wall-clock time(运行时间)。研究者考虑未来引入 async/await 机制,允许LLM发出并行请求。
第二是模型能力的硬门槛
RLM对基座模型的Code Generation和Instruction Following能力有极高要求。论文指出,小参数模型(如Qwen3-8B)由于无法编写正确的Python逻辑或无法正确管理环境状态,导致任务失败。这是一种“强者恒强”的架构。
第三是成本的长尾分布
虽然中位数成本较低,但RLM的成本分布具有“长尾效应”。在某些死循环或过度验证(Over-verification)的Case中(例如Qwen3-Coder反复验证5次答案),成本会飙升。这需要通过强化学习(RL)来对齐模型的“搜索/停止”策略。
Recursive Language Models的本质并不是一个新的模型架构,而是一种推理时的操作系统(OS for Inference)。
它通过将Context视为Disk,将LLM视为CPU,将REPL视为RAM,成功地在现有Transformer架构之上,通过软件工程手段解决了无限上下文的难题。
对于AI从业者而言,这篇论文揭示了一个战略方向:在2026年,与其在Training-time死磕昂贵的长窗口训练,不如在Inference-time投资能够编写递归代码的Agentic架构。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
