# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
7B量级模型,向来是端侧部署与个人开发者的心头好。
轻量化特性让它能灵活适配各类终端场景,而强劲性能又能覆盖图像信息抽取、文档理解、视频解析、物体定位等高频需求。
刚刚,华为重磅推出开源新玩家openPangu-VL-7B,直接瞄准这一核心场景精准发力。
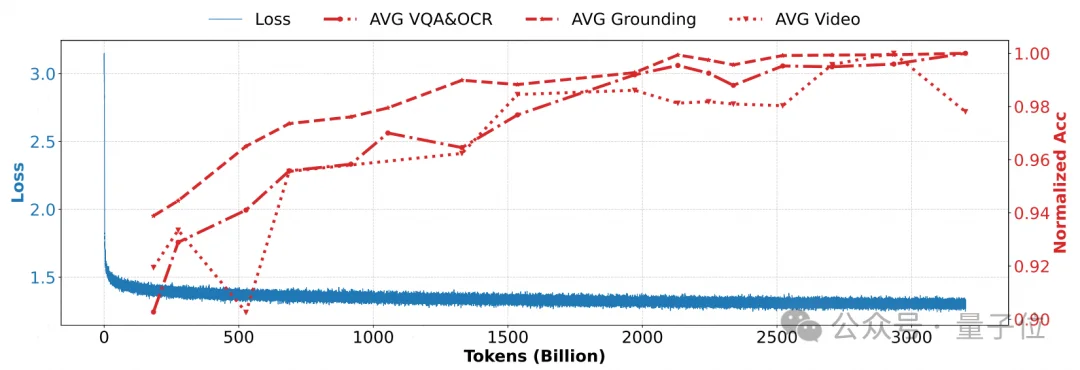
昇腾原生的模型结构,让openPangu-VL-7B的推理性能极具性价比:
720P图像在单张Ascend Atlas 800T A2卡上首字模型推理时延(ViT与LLM模型时延和)仅160毫秒,能够进行5FPS的实时推理;训练阶段的MFU更是达到42.5%。
更值得关注的是,模型在预训练阶段完成了3T+tokens的无突刺集群长稳训练,为开发者使用昇腾集群提供了极具价值的实践参考。
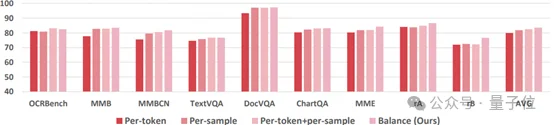
openPangu-VL-7B在通用视觉问答、文档图表理解&OCR、视觉定位、短视频理解等核心任务上表现突出,在开源榜单中力压同量级模型,展现出强悍的综合实力。
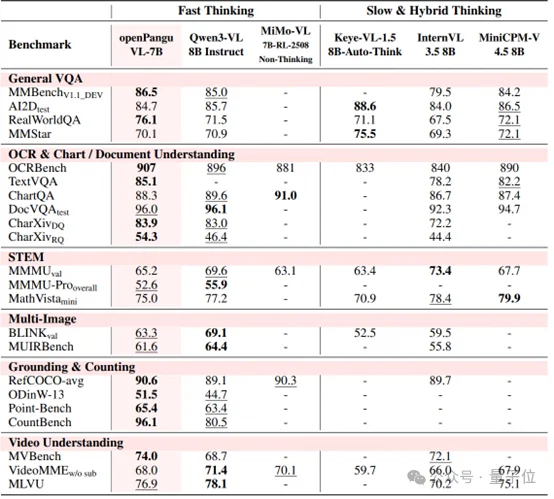
官方提供的cookbook也展现了模型在这些领域的优异能力。
比如我们给模型一张菜品图,让模型找到一共有多少个樱桃番茄,模型能够点出所有的位置并正确计数。

给模型一张年报截图,模型也能将其转变为markdown格式,省去了人工摘录的痛苦。
除了亮眼的榜单成绩和针对昇腾的训推优化,技术报告中还披露了若干核心技术细节,揭秘模型高性能背后的设计巧思:

业界传统视觉编码器多针对GPU架构设计,没有充分发挥昇腾硬件优势。
团队通过大量先导实验与性能分析,找到模型结构的最优平衡点——相同参数量下,该视觉编码器在昇腾芯片上的吞吐较使用窗注意力的ViT-H系列编码器提升15%。
同时,采用多标签对比学习框架,让模型具备更优的细粒度理解能力,为后续VLM训练中的视觉定位数据学习筑牢基础。
为解决不同长度训练样本的学习均衡问题,openPangu-VL-7B创新采用 “加权逐样本损失+逐令牌损失” 的混合训练方案,加权系数由令牌位置和样本重要性动态决定。
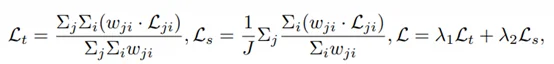
这一设计让模型在训练中既能吃透长回复数据,也不忽视短回复信息,避免 “顾此失彼”,消融实验已充分验证其有效性。
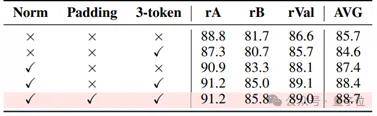
区别于业界主流的0-999定位方案,openPangu-VL-7B采用000-999千分位带填充相对坐标完成视觉定位。
整齐的三个token进行位置回归,不仅降低了模型学习难度,更显著提升了格式遵从性,让定位任务的精度和效率同步提升。
此外,技术报告还深入探索了预训练数据配比、位置编码、模型融合等关键策略,为开发者提供了全面的技术细节参考。
对于昇腾使用者而言,openPangu-VL-7B 的开源无疑是一大利好。
这款兼具轻量化、高性能与强通用性的多模态模型,既为端侧开发和个人使用提供了新选择,也将进一步丰富昇腾生态的应用场景,为创新注入新动力。
模型链接:
https://ai.gitcode.com/ascend-tribe/openPangu-VL-7B
技术报告:
https://ai.gitcode.com/ascend-tribe/openPangu-VL-7B/blob/main/doc/technical_report.pdf
文章来自于“量子位”,作者 “允中”。


