# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天在讲Milvus的Attu之前,我们先来唠一段计算机行业的八卦。
不知道有多少人见识过早年的DOS系统?
那是一个必须靠敲代码、输命令才能完成开机、建文件的时代,“会开电脑就已经很厉害了”,在那时候,还不是骂人的话

雷布斯在内,中国的第一代互联网精英们,都是这个时代的受益者。但很快,随着Windows的图形界面出现,它把复杂指令变成了点图标、拖窗口这样的简单操作,电脑的普及率也随之大幅提升。
当然,很多人对这个故事可能也不太熟,因为已经是40年前的事情了。
但很难相信,PC行业四十年前就完成的事情,在数据库行业,还是进行时状态。直到今天,操作很多数据库,想查一条数据、建一个数据集合,我们都得写专门Python/Go脚本;甚至只是切换不同环境的数据库,都要手动改配置。
开发做这些自然轻车熟路,但对RAG、推荐系统等场景的业务人员来说,门槛不低。
这也是今天为什么介绍Milvus的Web管理工具Attu的原因(尽管已经推出两三年了),但这绝对是我用过最好用的可视化界面替代命令行的数据库产品!
Attu是Milvus的全功能Web管理界面,就像MySQL有了Workbench、Redis有了RedisInsight,让你用浏览器就能完成所有数据库操作。
Attu采用前后端分离架构:React前端提供可视化操作界面,Node.js中间层封装Milvus SDK并暴露RESTful API,底层直连Milvus完成数据操作。
简单说就是给Milvus套了个Web壳,把命令行操作变成图形界面点击。技术栈选型上,React负责UI交互,Express.js处理WebSocket实时推送,底层通过官方Node.js SDK与Milvus 2.x通信。
痛点1:管理数据对象要写代码查看集群有哪些Collection、Partition、Database,或者创建、修改、删除这些对象,都需要写Python/Go脚本调用SDK。Attu提供Web界面,点击就能完成所有管理操作。
痛点2:向量数据看不懂查询返回的768维向量是一串浮点数,无法直观判断数据内容。Attu自动显示向量维度和关联的标量字段,让数据可读。
痛点3:验证查询效果慢测试RAG召回效果需要写脚本执行Search,每次修改参数都要重新运行代码。Attu提供Search界面,输入查询条件立即返回结果,实时查看召回内容和相似度分数。
痛点4:多环境切换麻烦开发、测试、生产环境的Milvus地址不同,每次切换需要修改代码配置。Attu支持保存多个连接配置,一键切换不同环境。
Attu 支持连接Milvus Standalone和Zilliz Cloud,可灵活使用本地或云托管数据库。本文采用Standalone部署方式进行实操。
环境准备Docker 20.10+ Docker Compose 2.0+
前提条件:
部署standalone模式Milvus
wget https://raw.githubusercontent.com/milvus-io/milvus/refs/tags/v2.6.3/deployments/docker/standalone/docker-compose.yml
docker-compose up -d
docker-compose ps -a
方式一:Docker一键启动(推荐)
bash
docker run -d \
--name attu \
-p 8000:3000 \
-e MILVUS_URL=http://host.docker.internal:19530 \
zilliz/attu:2.6.1
#访问 http://localhost:8000
方式二:Kubernetes中运行
kubectl apply -f https://raw.githubusercontent.com/zilliztech/attu/main/attu-k8s-deploy.yaml
访问主页面并登录
Milvus Address: localhost:19530(Docker用户填host.docker.internal:19530)
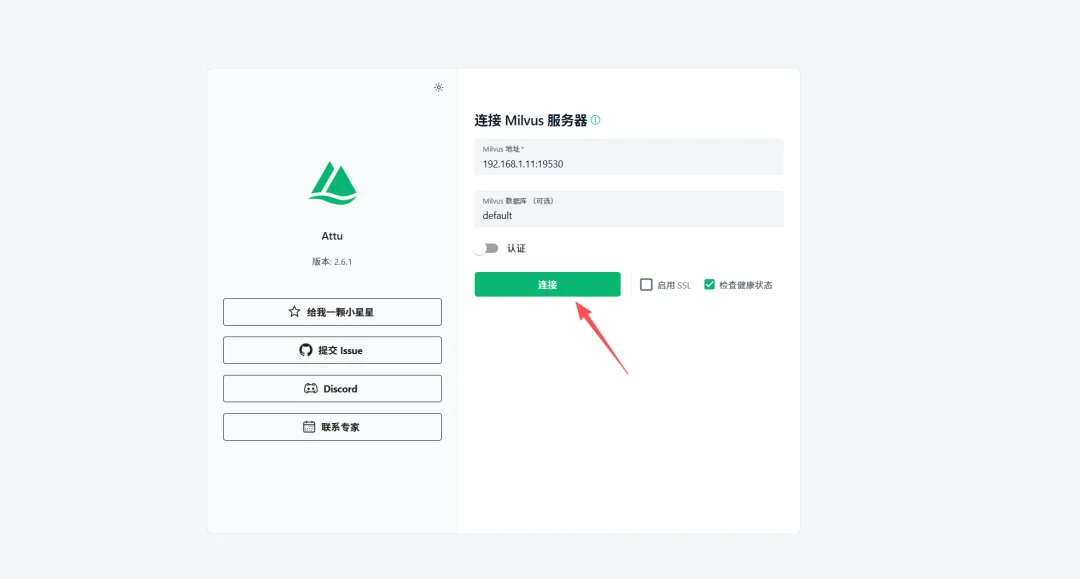
效果说明:
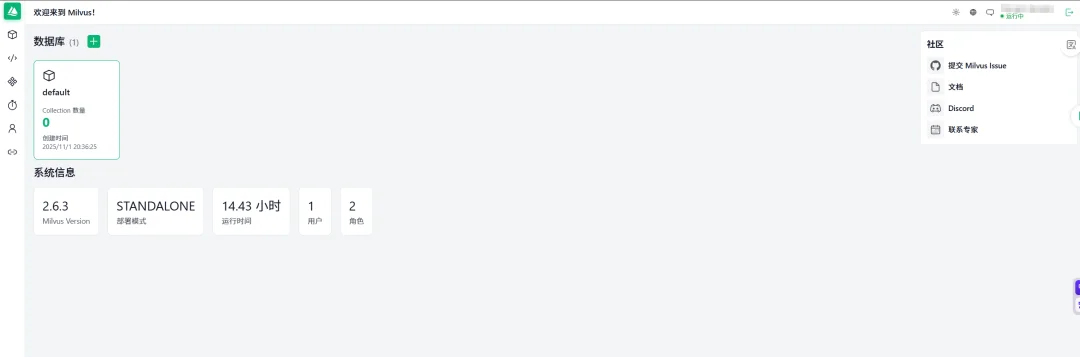
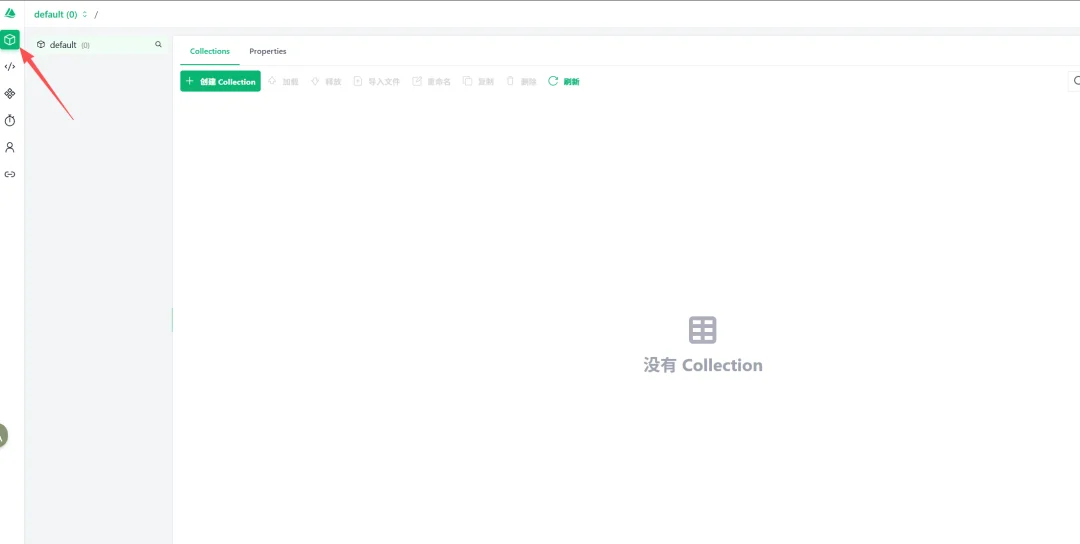
2.数据库、集合和分区管理
这是Attu最核心的功能,相当于MySQL Workbench的表管理模块。
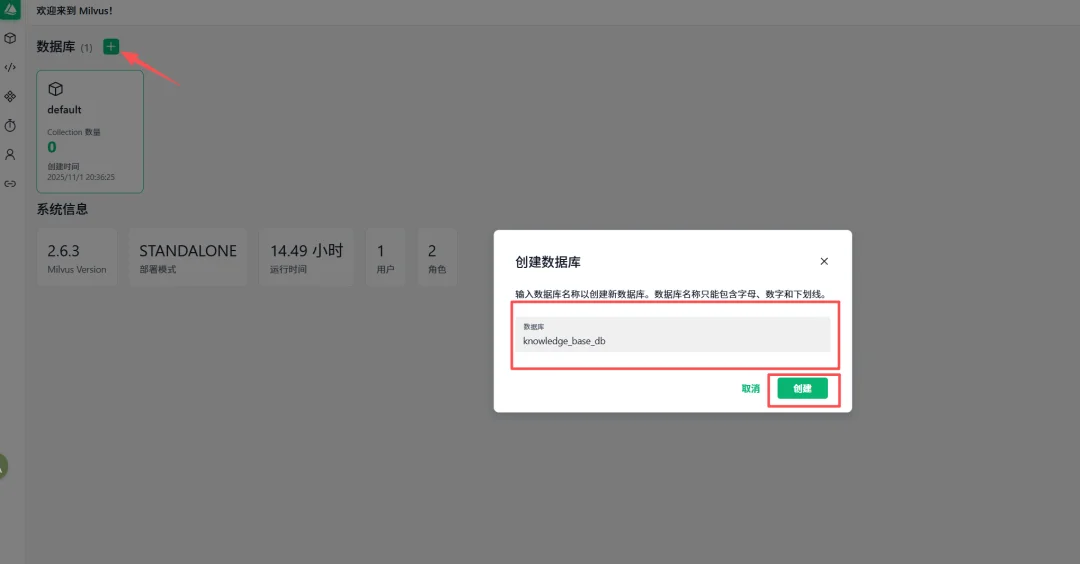
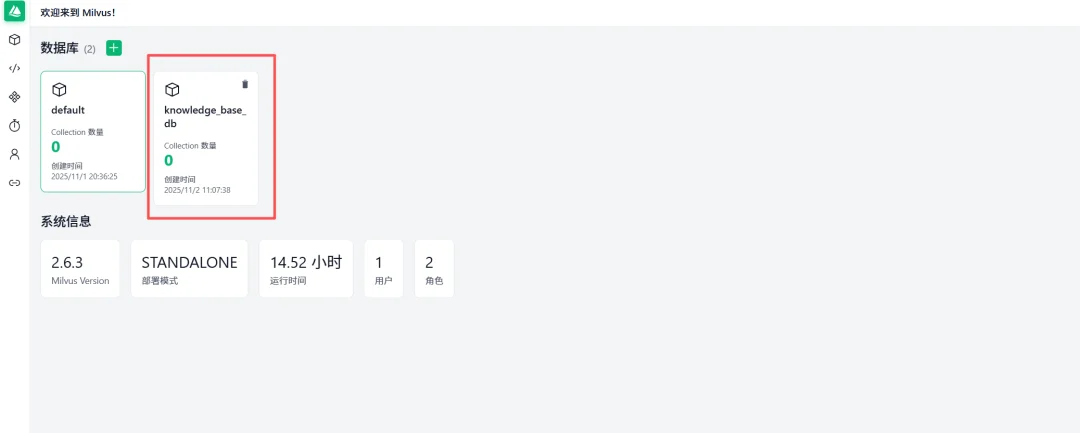
2.1 创建Database(Milvus 2.4+支持)
使用场景:
点击左上角“+”号,输入数据库名称(如:knowledge_base_db)后创建
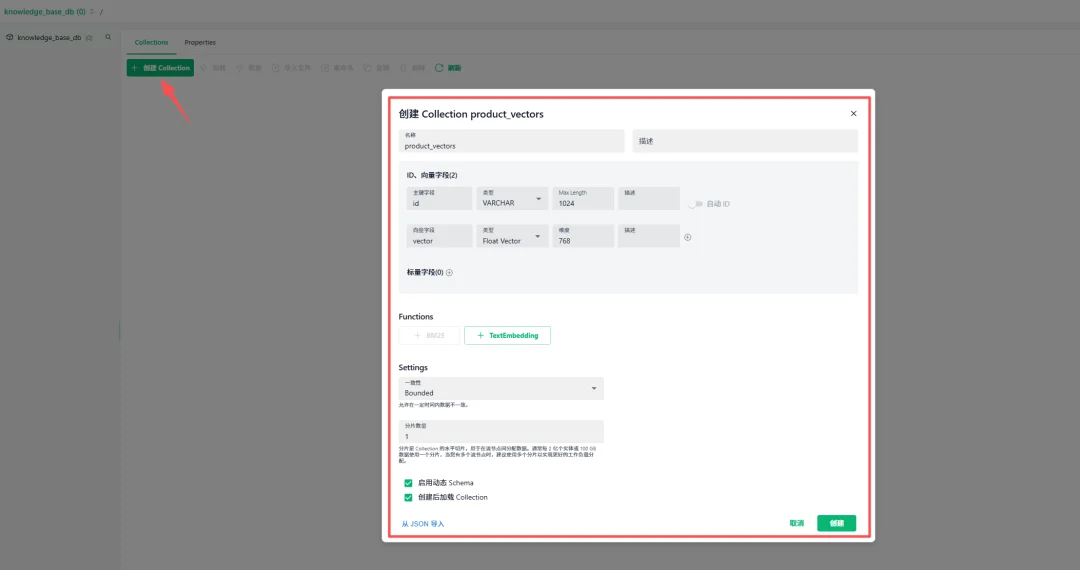
2.2创建Collection(核心功能)
Collection 是向量数据库中存储数据的基本单位,类似于关系型数据库中的表。
配置基本信息(新手建议):
Collection名称: product_vectors
描述: 商品向量搜索集合
字段配置
主键字段:
-名称: id
- 类型: VARCHAR
- Max Length: 64
- 自动ID: 否
向量字段:
- 名称: vector
- 类型: Float Vector
- 维度: 768
Functions
BM25: 不启用
TextEmbedding: 不启用
Settings
一致性级别: Bounded
分片数量: 1
启用动态 Schema: ✅ 是
创建后加载: ✅ 是
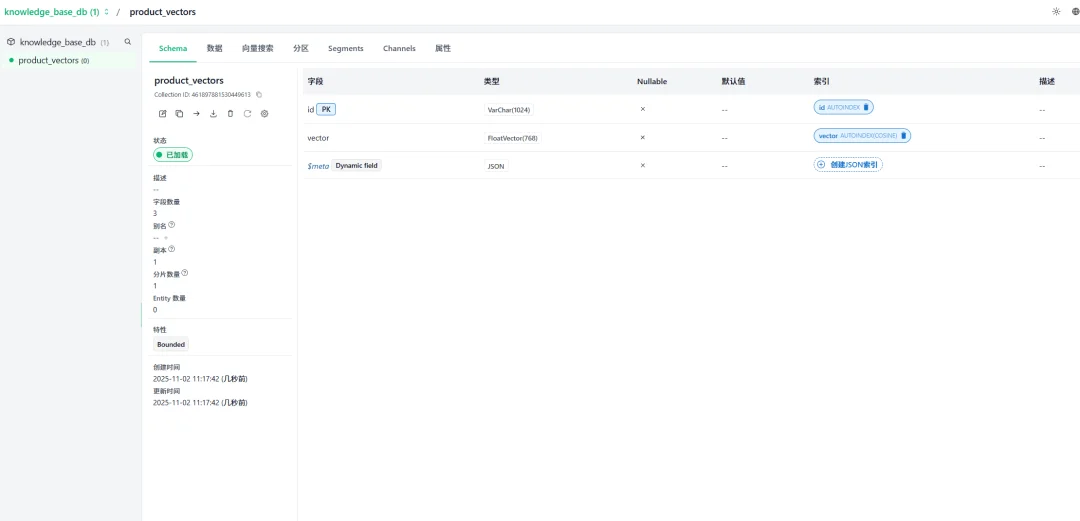
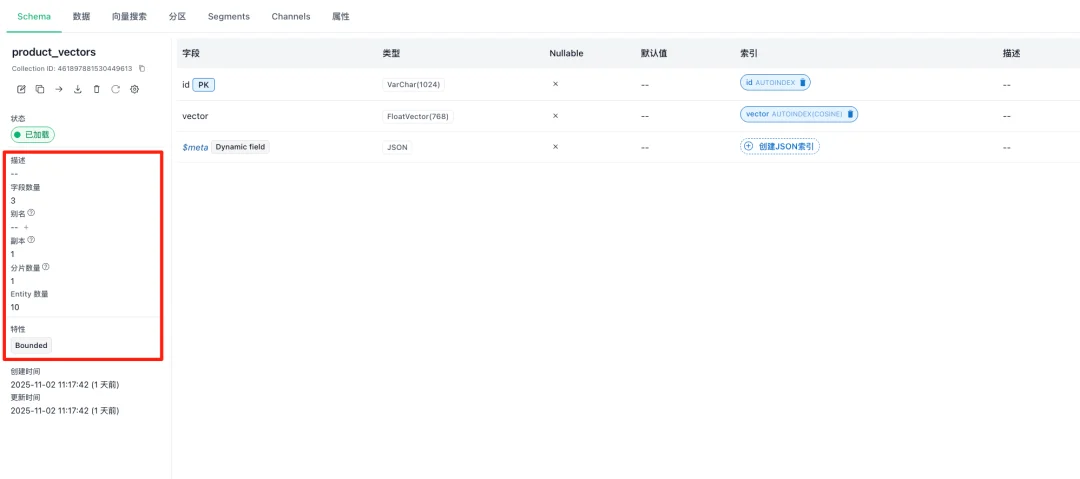
2.3Schema定义
这是product_vectors集合的数据模型定义界面,展示了集合的核心结构:
字段定义
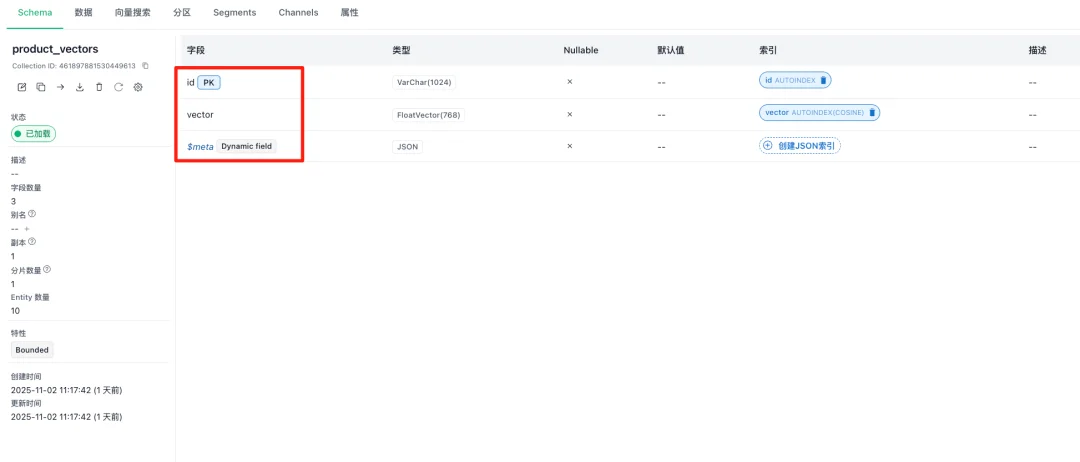
左侧包含了集合的状态信息
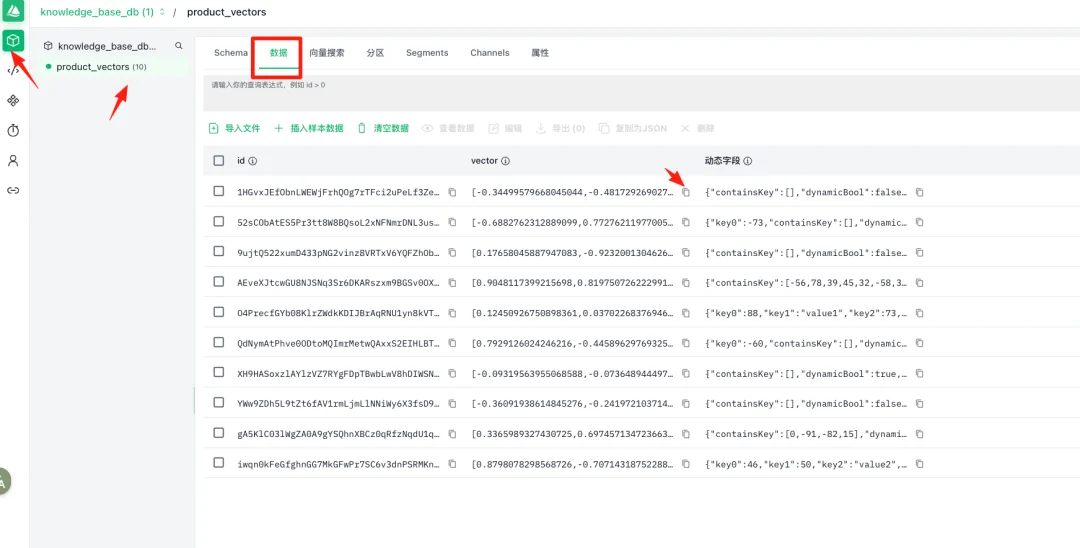
2.4数据插入(Import Data)
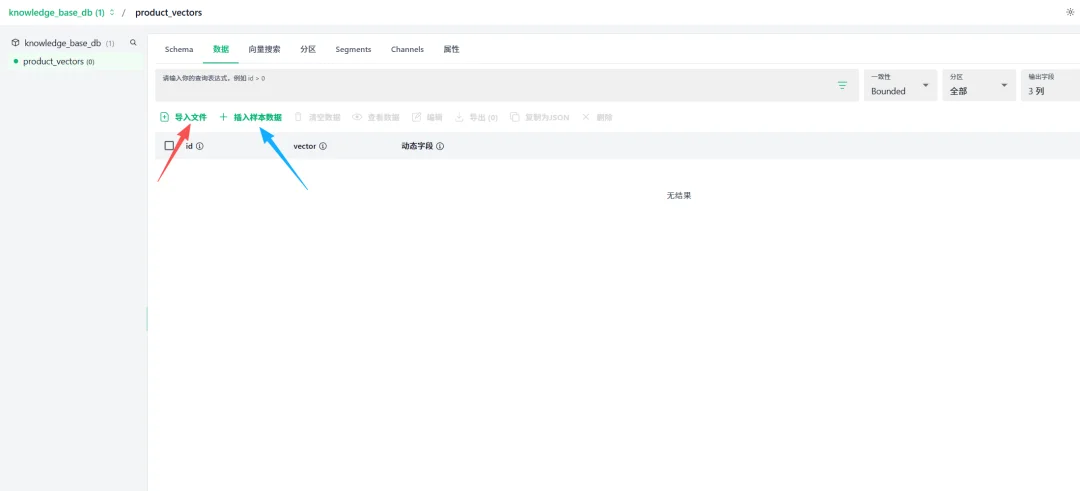
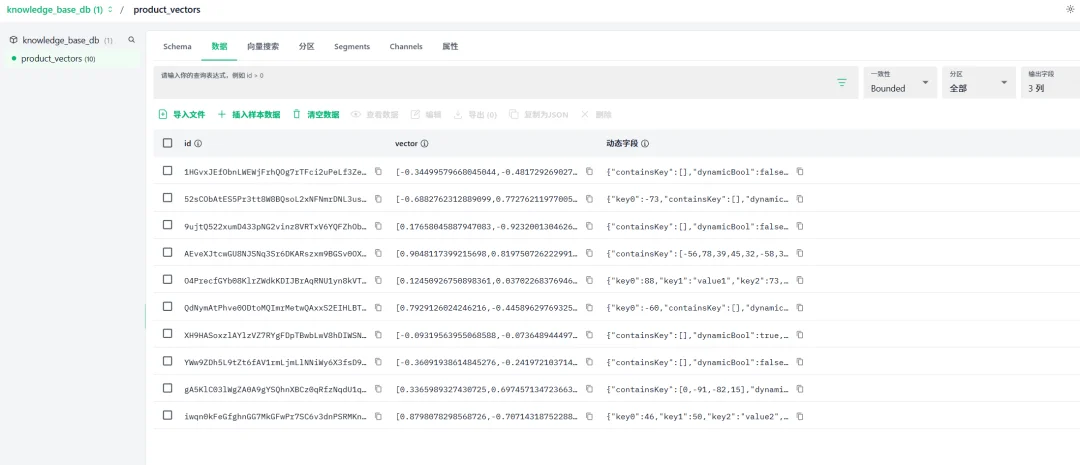
数据:浏览和管理collection中存储的具体数据记录
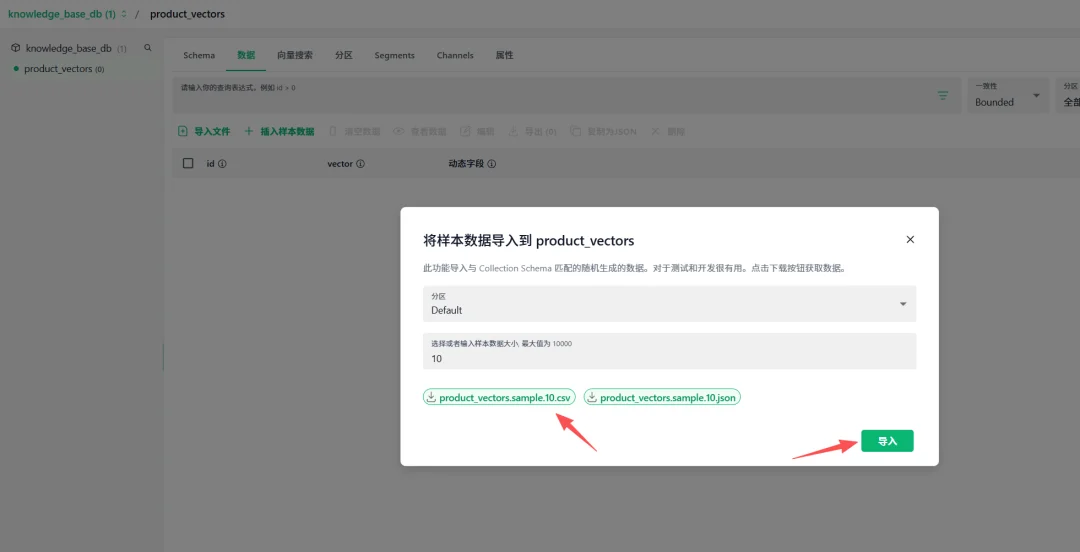
进入Collection详情页数据标签,可导入文件。这里采用示例数据导入
2.5向量搜索配置
这是向量相似度搜索的查询配置界面,用于执行向量检索操作:
2.5.1查询参数设置
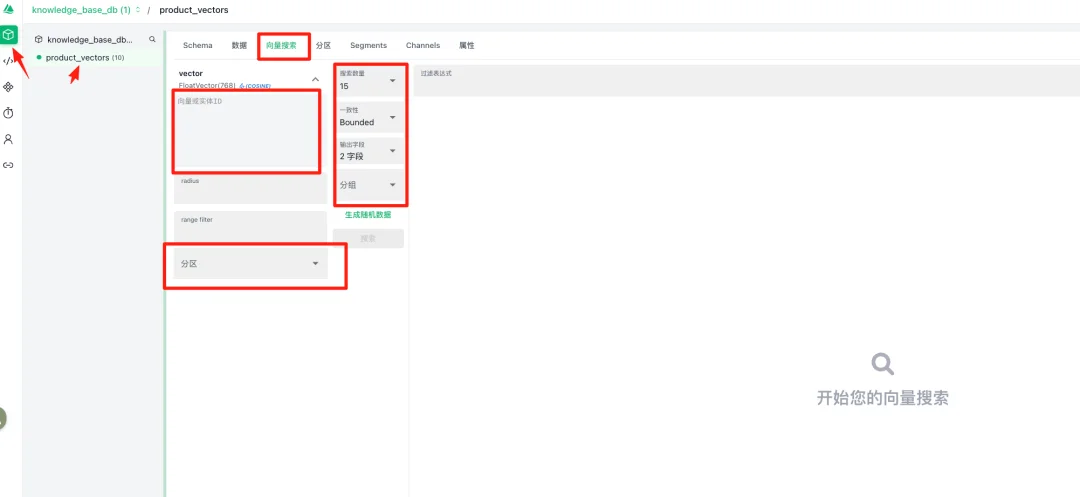
2.5.2如何查询?
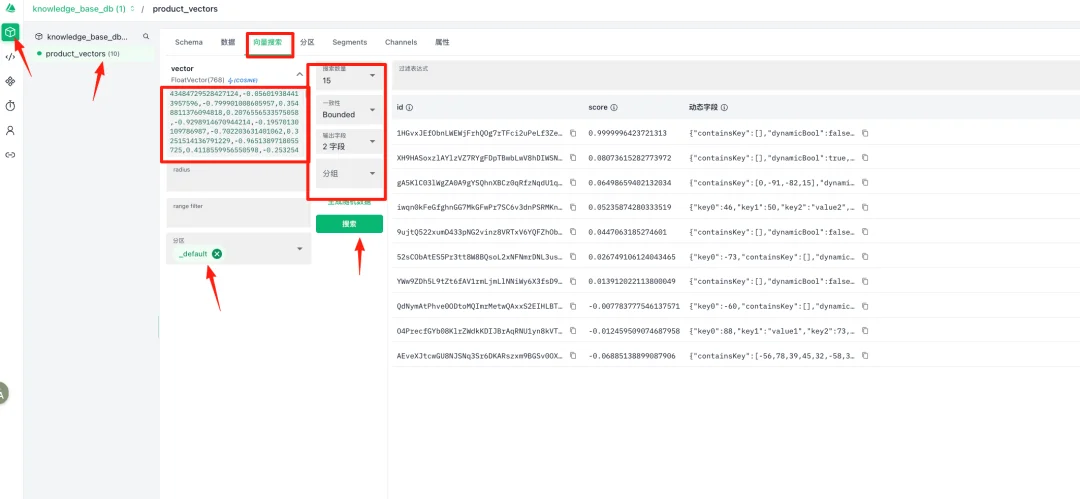
(1)选择数据标签里面找到已有数据的vector进行复制
(2)输入vector点击搜索按钮进行查询
说明:参考2.5.1查询参数进行自定义查询
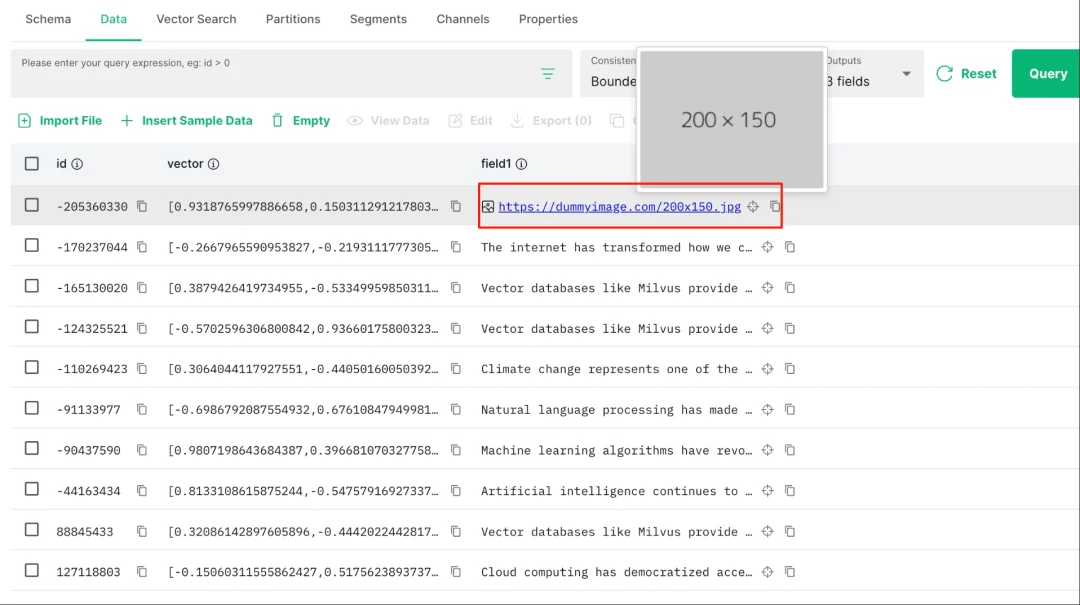
(3)查看数据(支持查看图片)
(4)删除数据
说明:选中并删除一条数据
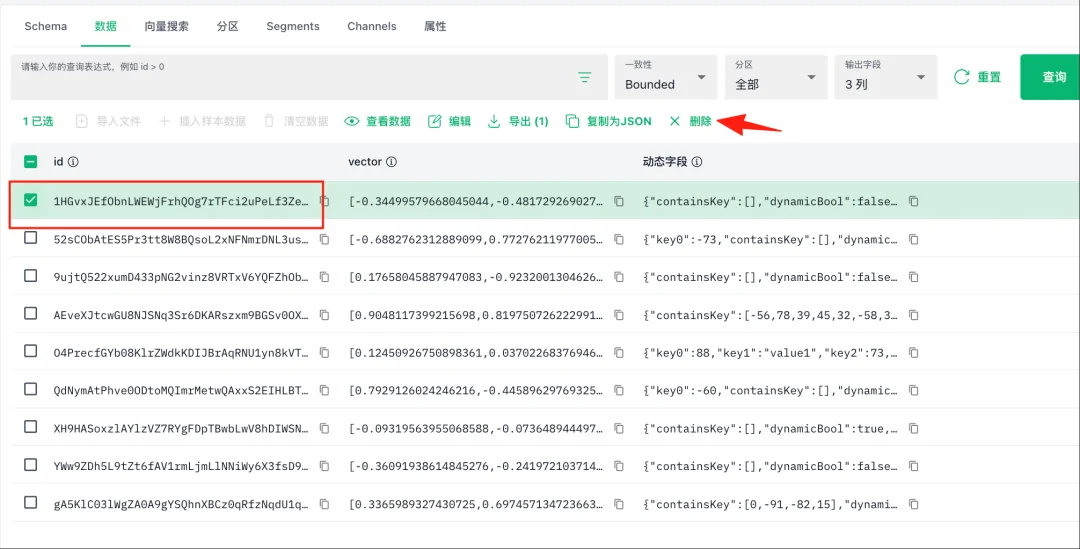
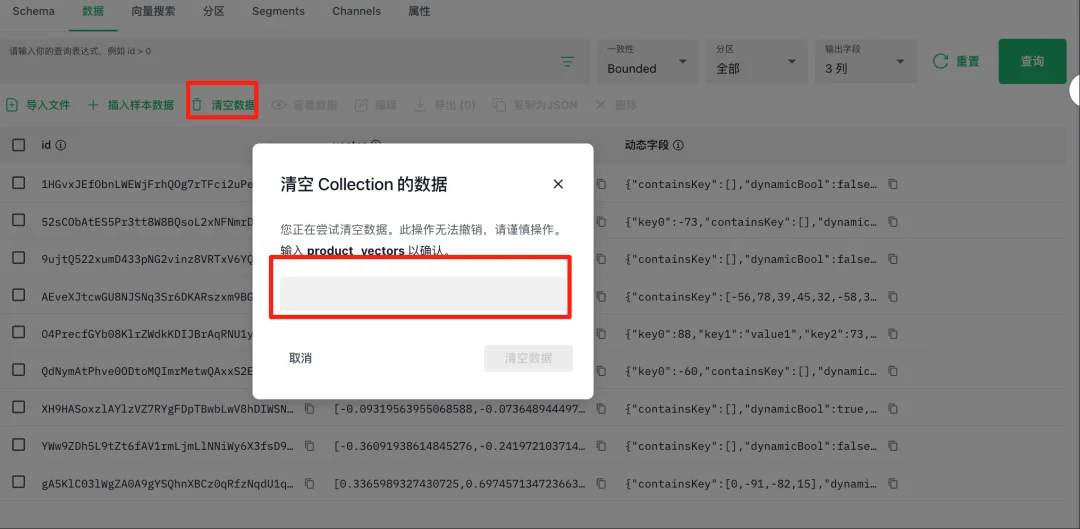
说明:清空整个collection数据(须谨慎)
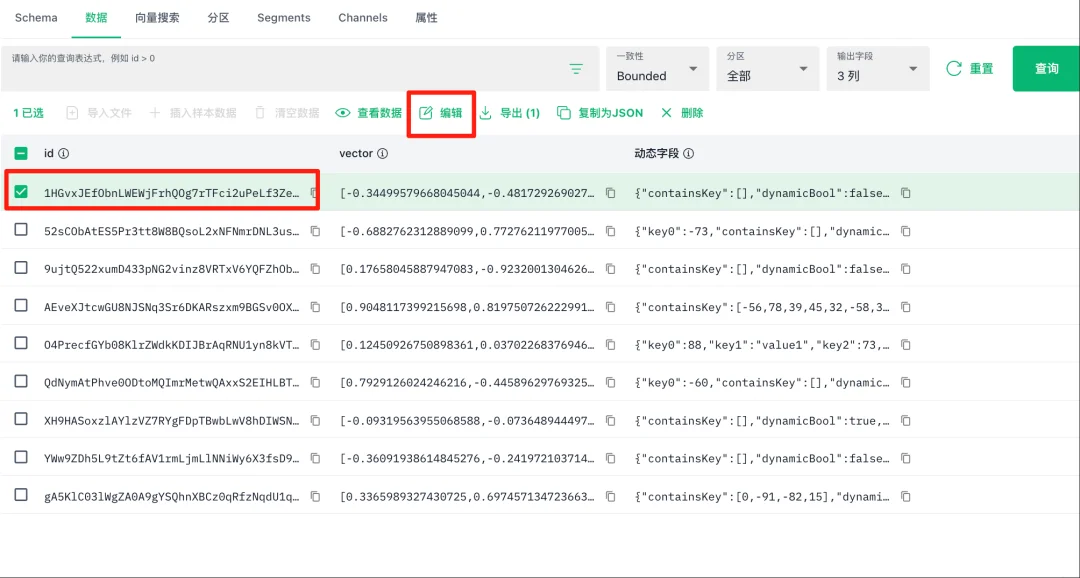
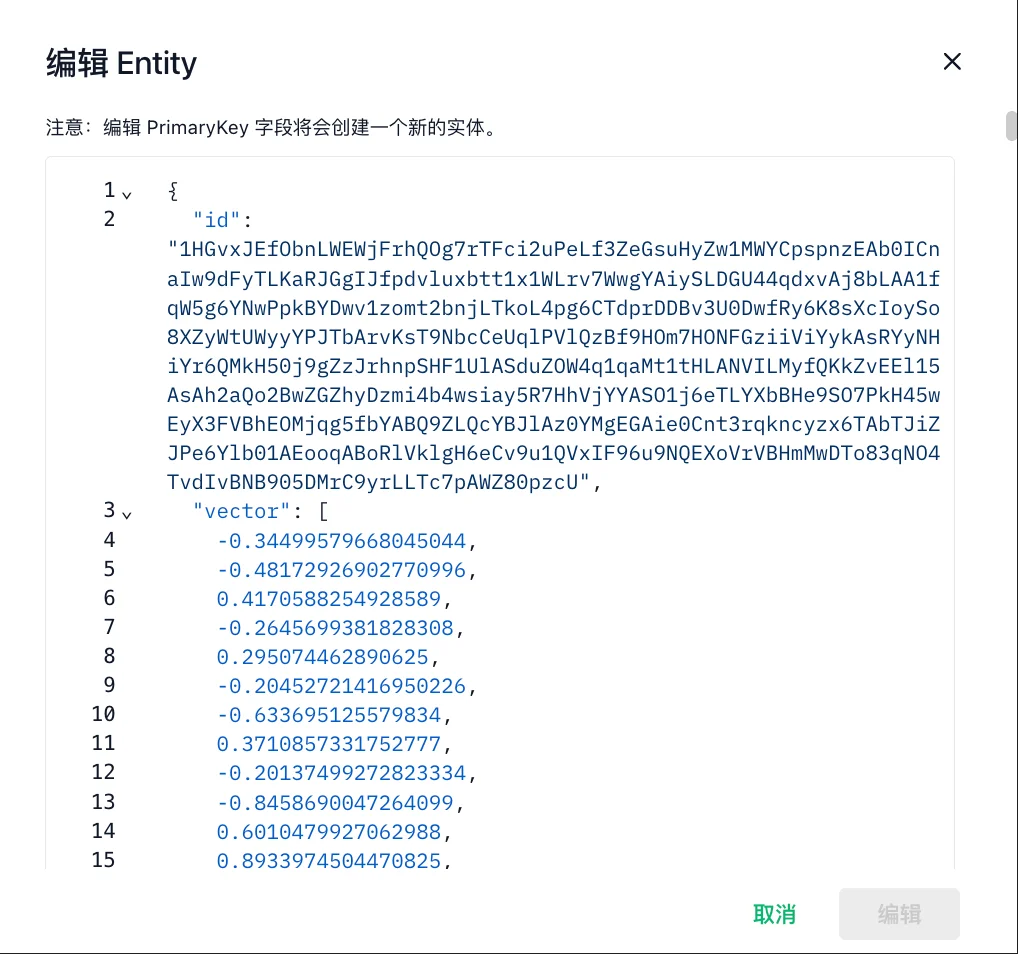
(5)修改数据
说明:支持upsert
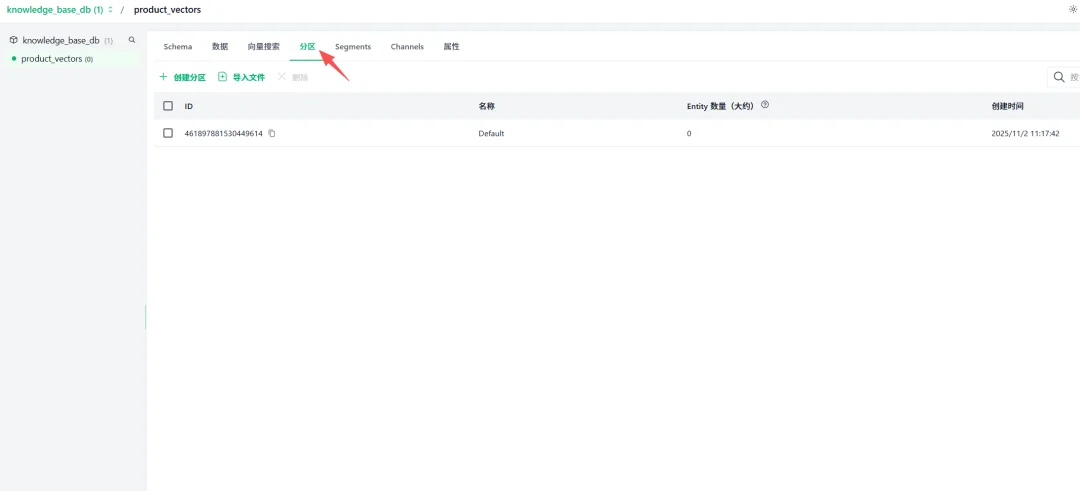
2.6分区(Partition)管理
分区是 Collection 内部的逻辑隔离单元,用于将数据按业务需求分组存储:
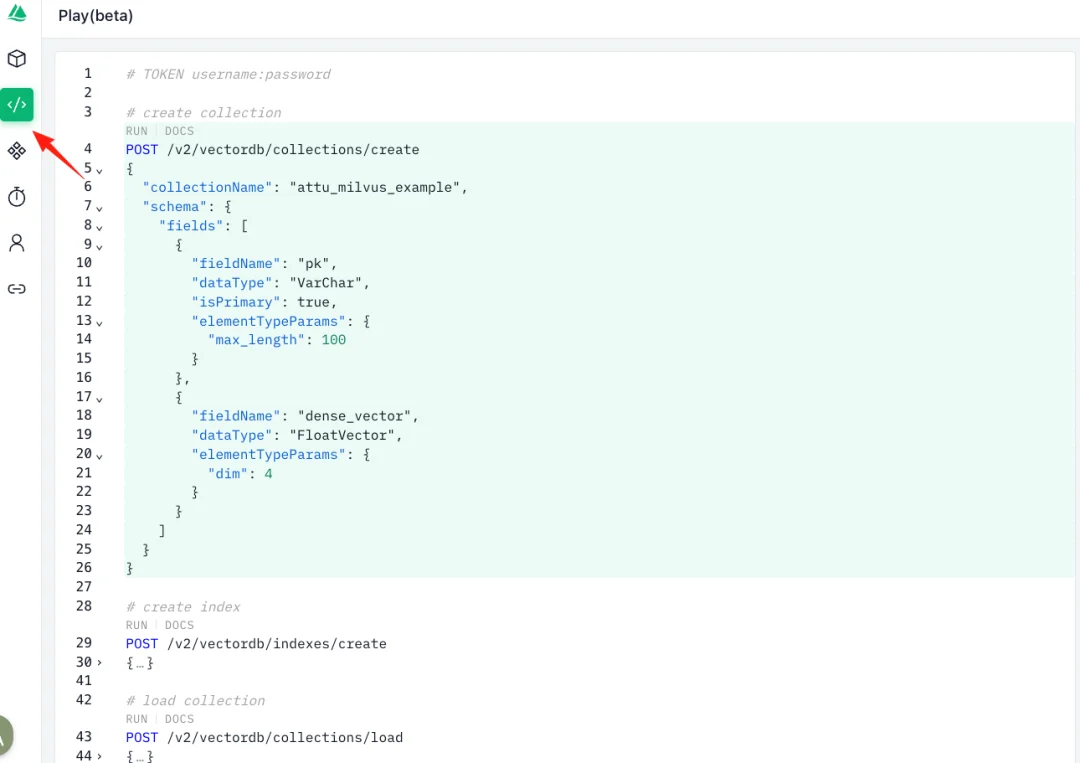
3.Play功能
Play(beta) 是Attu提供的一个API测试平台,让你可以直接在网页上测试Milvus的各种操作,而不需要编写完整的程序代码。
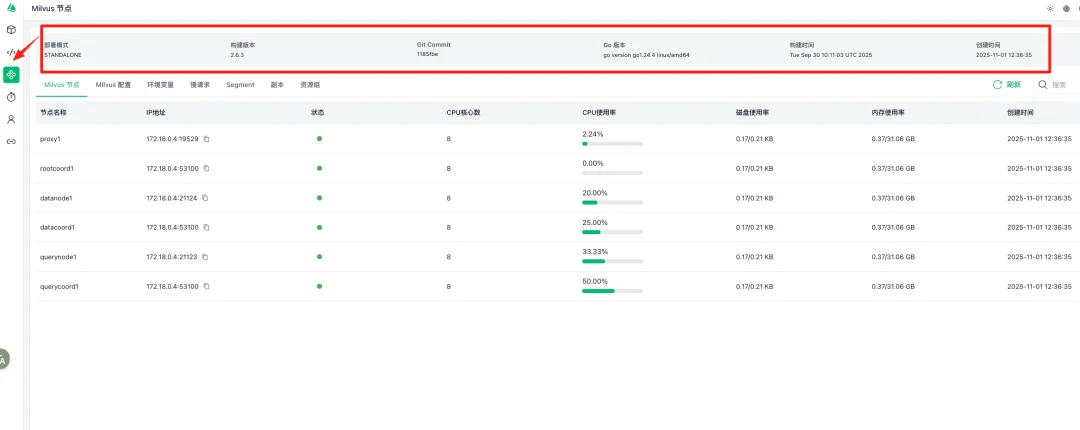
4.Milvus运维管理界面
这是系统健康监控仪表板,让管理员可以实时查看Milvus集群的运行状态。
界面顶部展示了Milvus系统的核心信息。当前系统运行在STANDALONE单机模式下,使用的是2.6.3版本。除了版本号外,系统还详细记录了代码的Git提交版本号、Go语言运行环境信息,以及系统的构建时间和部署创建时间,这些时间戳帮助管理员追溯系统的部署历史。
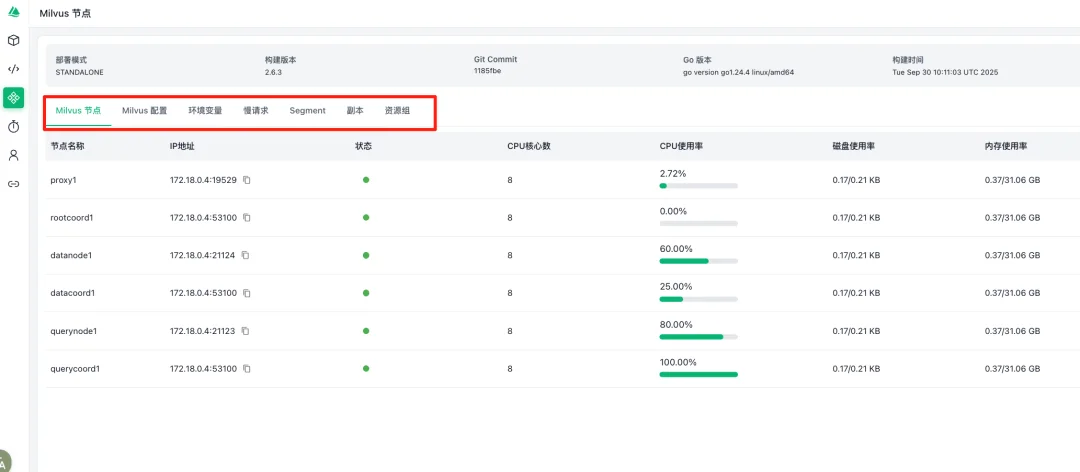
下方页签停留在Milvus节点标签,该页面用于查看所有服务组件的运行状态。往下依次是Milvus配置和环境变量标签,分别用于查看系统的配置参数和环境设置。慢请求标签则专门用于监控那些响应缓慢的查询操作,帮助定位性能瓶颈。再往下的Segment和副本标签,分别管理数据段信息和数据副本的分布情况。最后是资源组标签,用于查看集群的资源分配状况。这些功能模块共同构成了Milvus的相对完整运维监控体系。
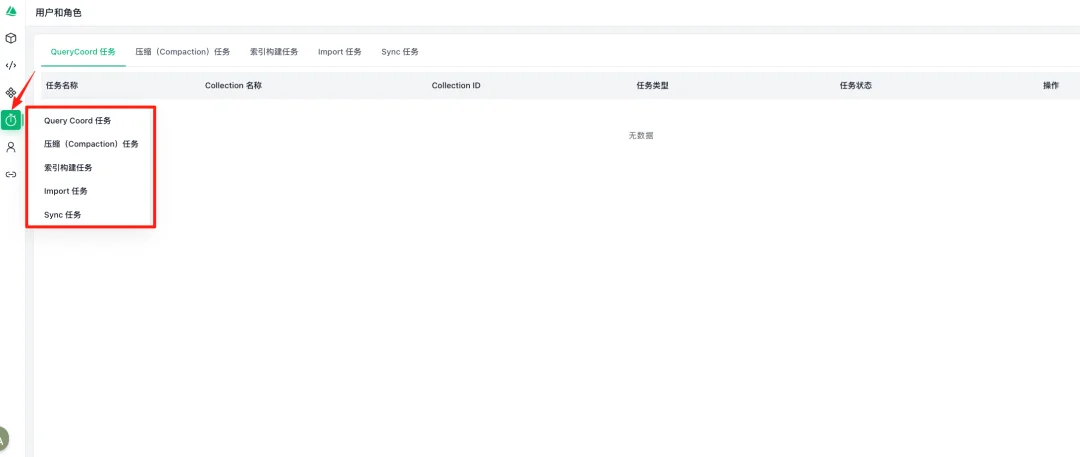
5.任务管理界面
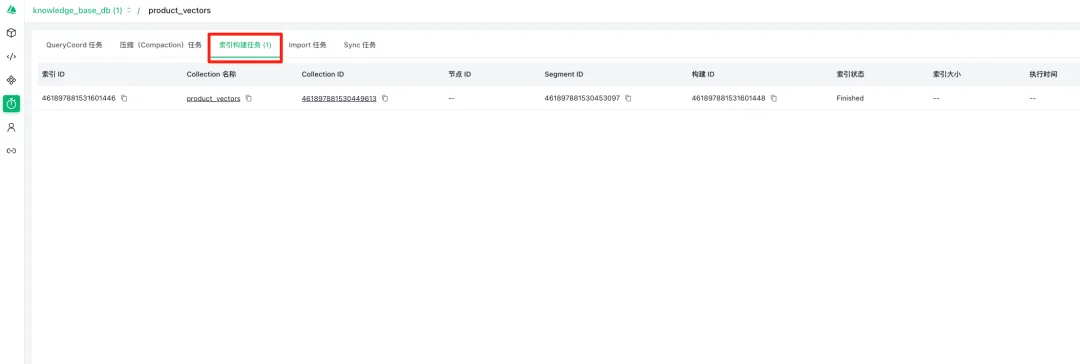
Milvus 节点的任务管理页面,包含五种任务类型:QueryCoord 任务、压缩(Compaction)任务、索引构建任务、Import 任务和 Sync 任务。界面以表格形式展示任务信息,包含任务名称、Collection 名称、Collection ID、任务类型、任务状态和操作等字段。
6.RBAC 权限管理界面
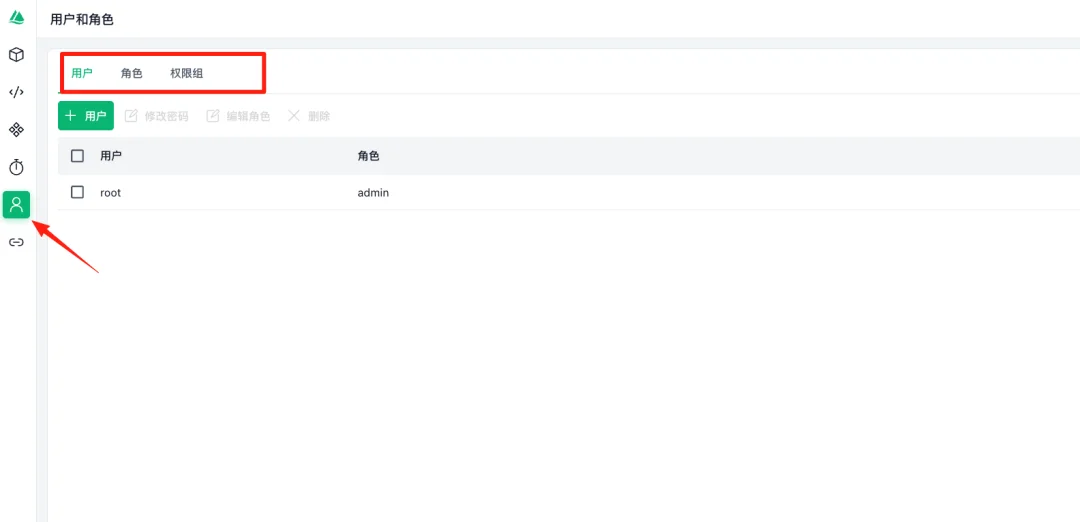
用户和角色管理页面,采用 RBAC(基于角色的访问控制)模型。界面分为用户、角色、权限组三个标签页。用户管理模块提供添加用户、修改密码、编辑角色、删除等功能。表格展示用户与角色的对应关系,示例中root 用户被分配了 admin 角色。
创建步骤如下
前提条件:
必须要以root用户重新登录attu,默认密码Milvus。
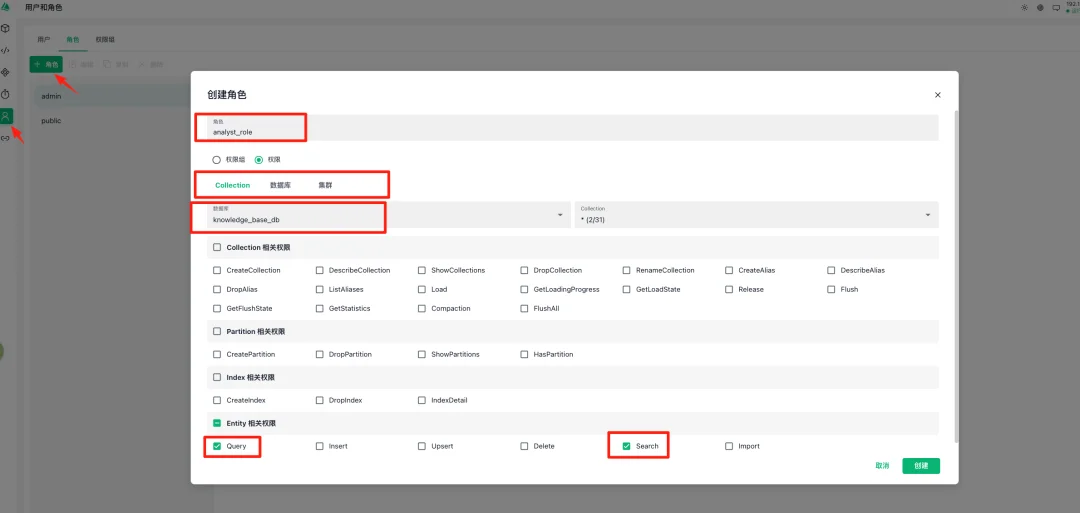
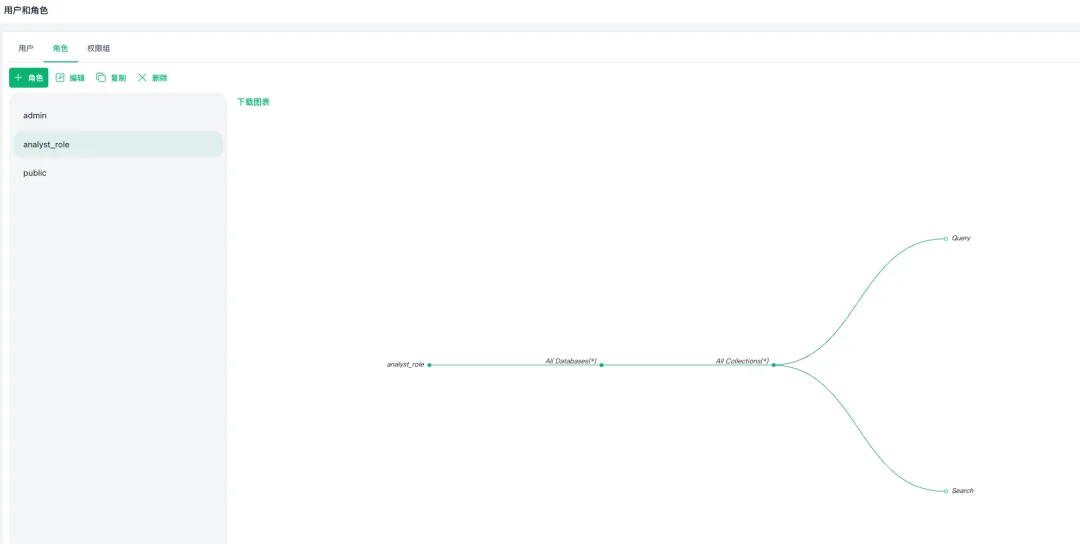
第一步:创建角色
在角色标签页点击+ 角色按钮,创建自定义角色
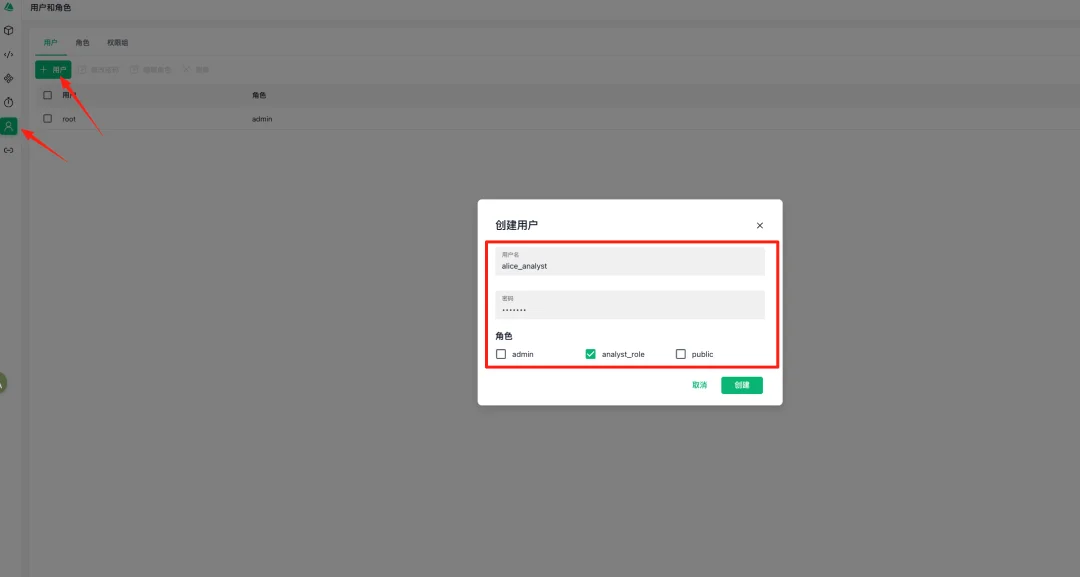
角色名:analyst_role(分析师角色)
授予权限:Query、Search(只读权限)
Collection 模块:用于细粒度控制特定 Collection 的操作权限
数据库模块:用于控制整个数据库级别的权限
集群模块:用于控制集群级别的全局权限

第二步:创建用户并绑定刚才的角色
在用户标签页点击+ 用户按钮,创建用户:
Attu可以解决大部分的日常管理场景,它能让你从写脚本操作解放出来,把时间花在更有价值的事情上——比如优化RAG的召回策略,设计agent架构。
最重要的是,时间可以用在技术开发上,再也不用每天8小时工作时间,还要专门抽一小时帮业务干数据查看、管理、写脚本这样的无意义活动,这真的很重要!!!

Zilliz黄金写手:尹珉
文章来自于微信公众号 “Zilliz”,作者 “尹珉”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
