# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。
在 Daily-Omni 等多个基准测试中,其准确率超越 Gemini 2.5-Flash 和 Qwen3-Omni 等开闭源模型。


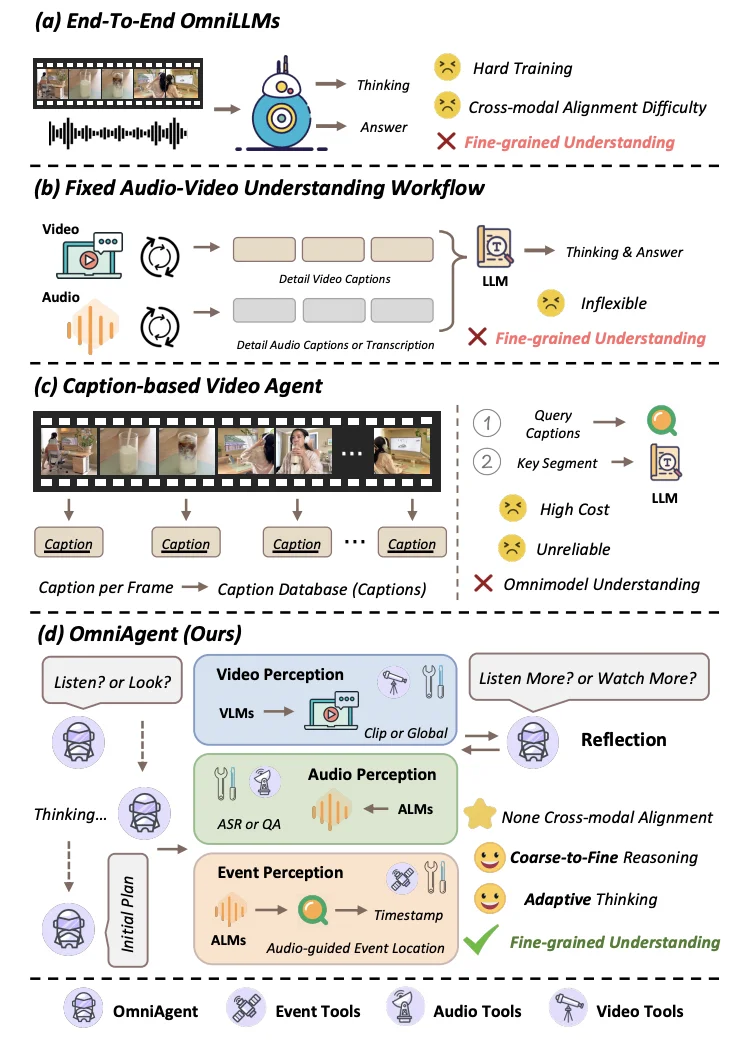
相比之下,OmniAgent 引入了一种全新的主动感知推理范式。通过在迭代反思循环中策略性地调度视频与音频理解能力,该方法有效攻克了跨模态对齐的难题,从而实现了对视听内容的细粒度理解。
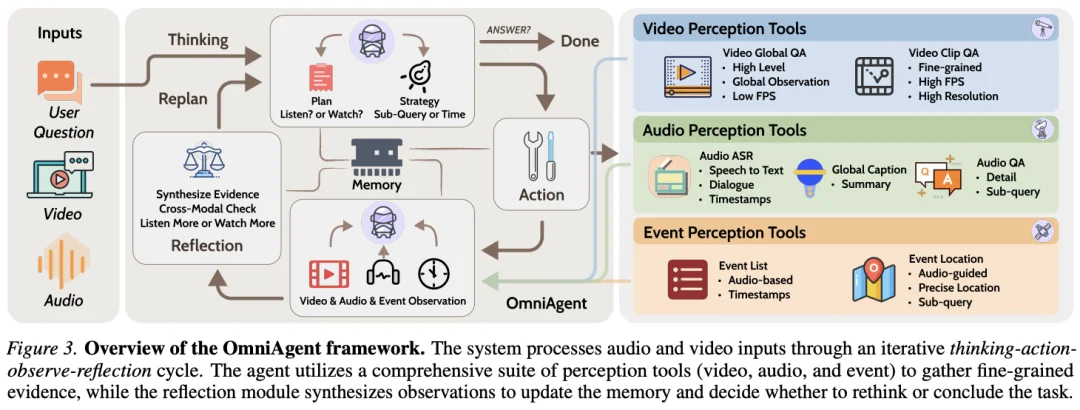
OmniAgent 摒弃了固定的工作流,采用了「思考 - 行动 - 观察 - 反思」 闭环机制 。
1.思考:OmniAgent 会根据问题进行分析,自主决定「听」还是「看」。
2.行动:根据计划,OmniAgent 会从构建的多模态工具中选取合适的工具进行调用:
3.观察与反思机制:智能体接受工具结果,评估目前已有的证据能否正确的回答问题,并且结合之前在多步推理中进行跨模态一致性检查,确保视听证据互证,解决幻觉与对齐问题。
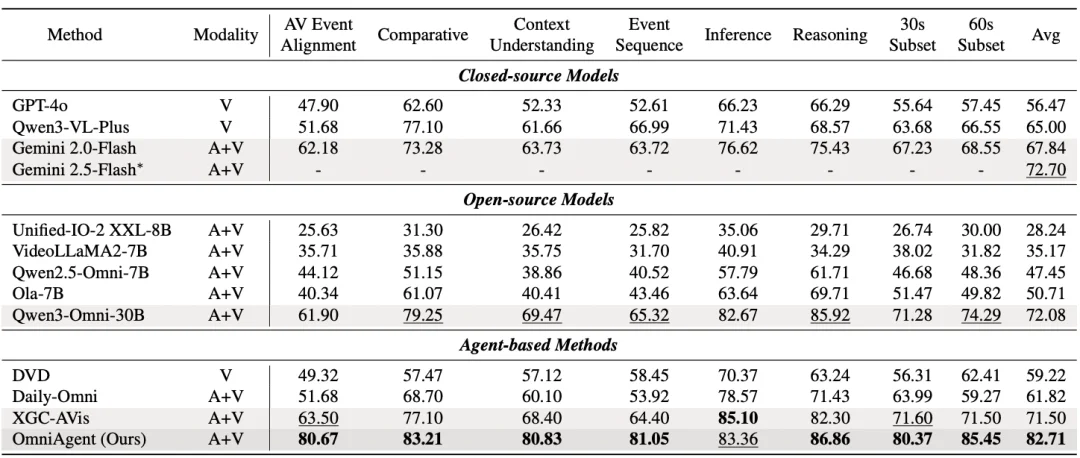
OmniAgent 在三个主流视听理解基准测试中均取得了 SOTA 成绩,显著优于现有的开源及闭源模型:
1.Daily-Omni Benchmark:准确率达到 82.71%,超越 Gemini 2.5-Flash (72.7%) 和 Qwen3-Omni-30B (72.08%),提升幅度超 10% 。
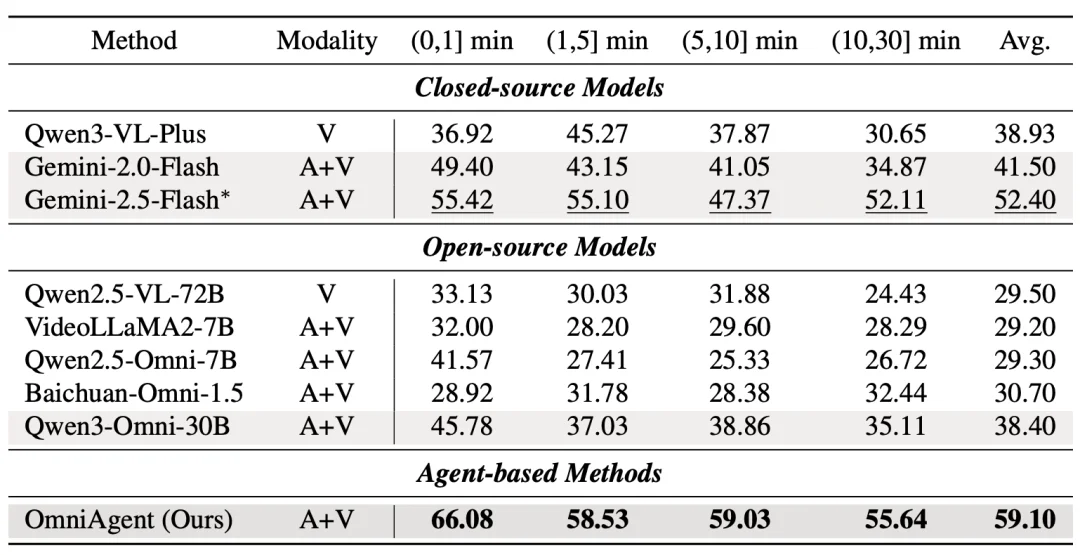
2.OmniVideoBench:在长视频理解任务中,准确率达 59.1%,大幅领先 Qwen3-Omni-30B (38.4%) 。
3.WorldSense: OmniAgent 也保持了领先的准确度。
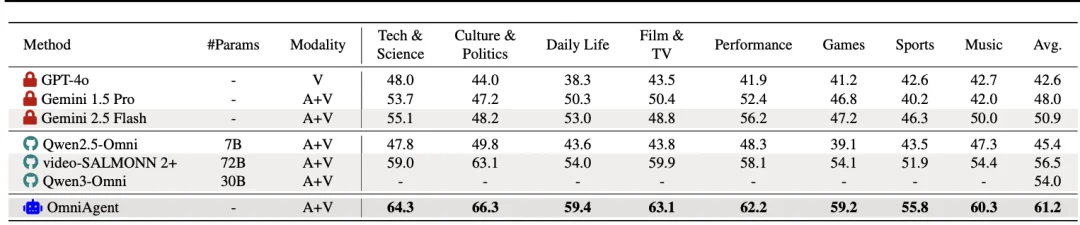
总的来看,OmniAgent 证明了在全模态理解任务中,音频引导的的主动感知策略是解决跨模态对齐困难、提升细粒度推理能力的有效路径。该工作为未来的全模态 Agent 算法设计提供了新的范式参考。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】Whisper是由openai出品的语音转录大模型,它可以应用在会议记录,视频字幕生成,采访内容整理,语音笔记转文字等各种需要将声音转出文字等场景中。
项目地址:https://github.com/openai/whisper
在线使用:https://huggingface.co/spaces/sanchit-gandhi/whisper-jax
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
