# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在长期以来的 AI 研究版图中,具身智能虽然在机器人操作、自动化系统与现实应用中至关重要,却常被视为「系统工程驱动」的研究方向,鲜少被认为能够在 AI 核心建模范式上产生决定性影响。
而 ReconVLA 获得 AAAI Outstanding Paper Awards,释放了一个清晰而重要的信号:让智能体在真实世界中「看、想、做」的能力,已经成为人工智能研究的核心问题之一。
这是具身智能(Embodied Intelligence / Vision-Language-Action)方向历史上,首次获得 AI 顶级会议 Best Paper 的研究工作。这是一次真正意义上的 community-level 认可:不仅是对某一个模型、某一项指标的认可,更是对具身智能作为通用智能核心范式之一的肯定。


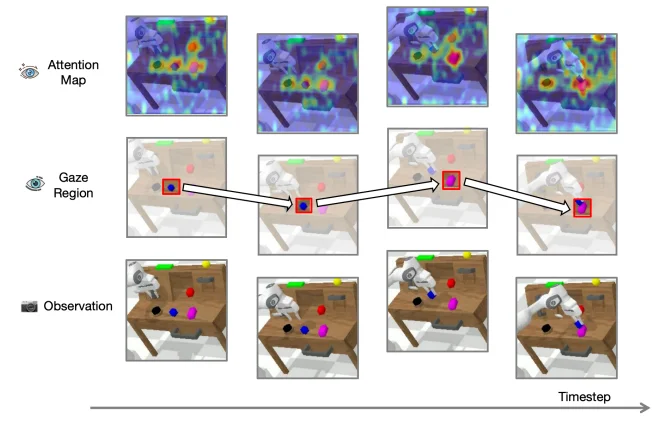
近年来,Vision-Language-Action(VLA)模型在多任务学习与长时序操作中取得了显著进展。然而,我们在大量实验中发现,一个基础但被长期忽视的问题严重制约了其性能上限:视觉注意力难以稳定、精准地聚焦于任务相关目标。
以指令「将蓝色积木放到粉色积木上」为例,模型需要在复杂背景中持续锁定「蓝色积木」和「粉色积木」。但现实中,许多 VLA 模型的视觉注意力呈现为近似均匀分布,不同于人类行为专注于目标物体,VLA 模型容易被无关物体或背景干扰,从而导致抓取或放置失败。
已有工作主要通过以下方式尝试缓解这一问题:
然而,这些方法并未从根本上改变模型自身的视觉表征与注意力分配机制,提升效果有限。
为解决上述瓶颈,我们提出 ReconVLA,一种重建式(Reconstructive)Vision-Language-Action 模型。其核心思想是:
不要求模型显式输出「看哪里」,而是通过「能否重建目标区域」,来约束模型必须学会精准关注关键物体。
在 ReconVLA 中,动作预测不再是唯一目标。在生成动作表征的同时,模型还需要完成一项辅助任务:
重建当前时刻所「凝视」的目标区域 ----- 我们称之为 Gaze Region。
这一重建过程由轻量级扩散变换器(Diffusion Transformer)完成,并在潜在空间中进行高保真复原。由于要最小化重建误差,模型被迫在其内部视觉表示中编码关于目标物体的精细语义与结构信息,从而在注意力层面实现隐式而稳定的对齐。
这一机制更接近人类的视觉凝视行为,而非依赖外部检测器或符号化坐标监督。
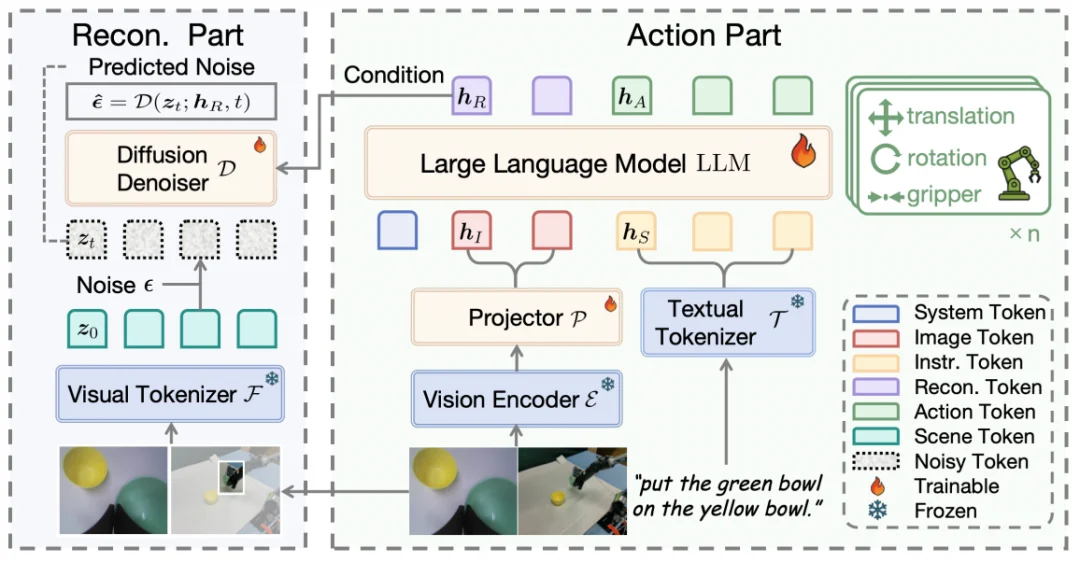
ReconVLA 的整体框架由两个协同分支组成:
1. 动作预测分支: 模型以多视角图像、自然语言指令与机器人本体状态为输入,生成动作 token,直接驱动机器人执行操作。
2. 视觉重建分支: 利用冻结的视觉 tokenizer,将指令关注的目标区域(Gaze region)编码为高保真潜在 token。主干网络额外输出同维度的重建 token,并以此作为条件,引导扩散去噪过程逐步复原目标区域的视觉表示。
重建损失在像素与潜在空间层面为模型提供了隐式监督,使视觉表征与动作决策在训练过程中紧密耦合。
为赋予 ReconVLA 稳定的视觉重建与泛化能力,我们构建了一个大规模机器人预训练数据集:
该预训练过程不依赖动作标签,却显著提升了模型在视觉重建、隐式 Grounding 以及跨场景泛化方面的能力,并为未来扩展至互联网级视频数据奠定了一定基础。
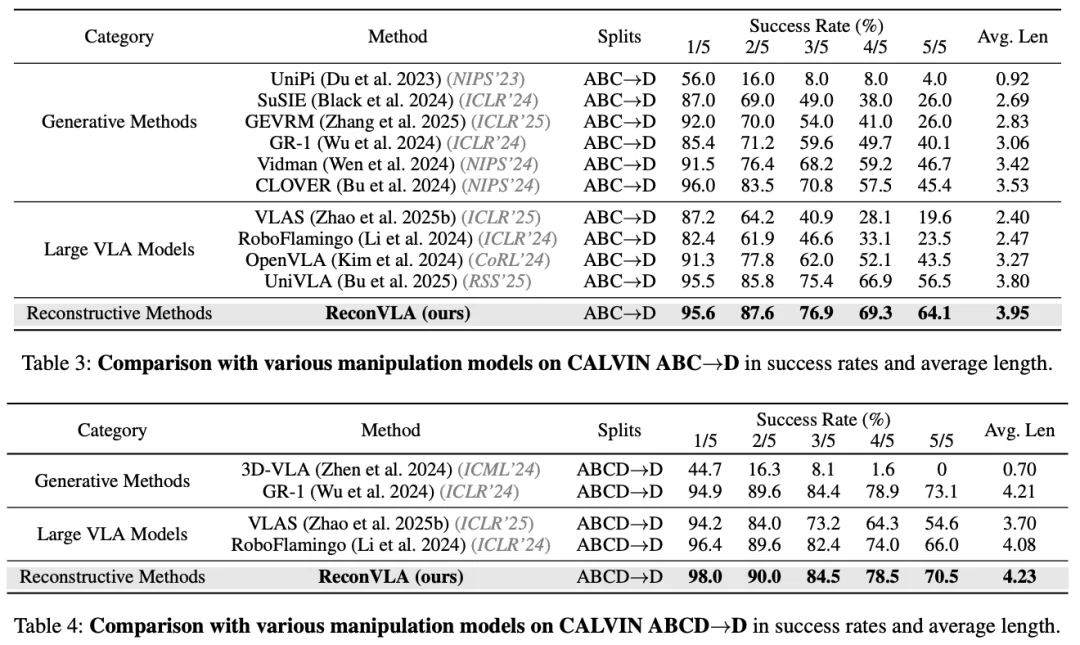
在 CALVIN 仿真基准上,ReconVLA 在长时序任务中显著优于现有方法:
值得一提的是,在 CALVIN 极具挑战的长程任务「stack block」上我们的方法成功率达到 79.5%,远高于 Baseline 的 59.3%,这说明我们的局部重建作为隐式监督的方法可以在复杂长程任务中实现更灵活的运动规划。
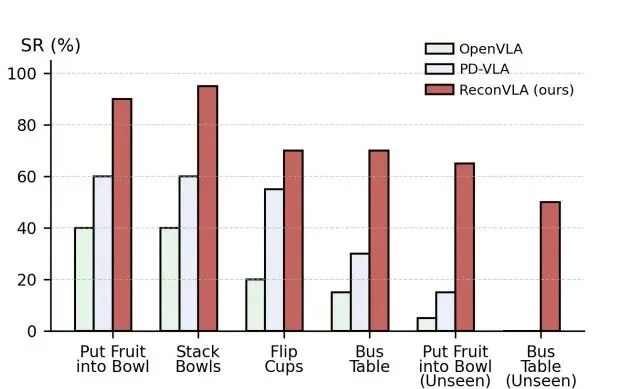
在真实机器人实验中,我们基于 AgileX PiPer 六自由度机械臂,测试了叠碗、放水果、翻杯与清理餐桌等任务。ReconVLA 在所有任务上均显著优于 OpenVLA 与 PD-VLA,并在未见物体条件下仍保持 40% 以上的成功率,展现出强大的视觉泛化能力。
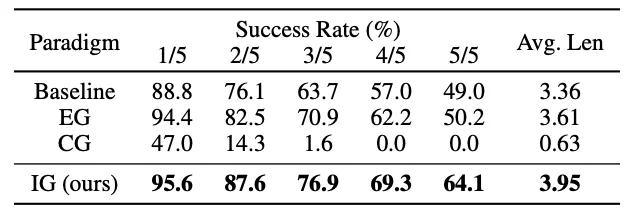
对比于 Explicit Grounding 和 COT Grounding,ReconVLA 在 CALVIN 上获得了远高于前两者的成功率,由此可分析出:
仅用精细化的目标区域作为模型隐式监督可以实现更加精确的注意力,更高的任务成功率以及更简单的模型夹构。
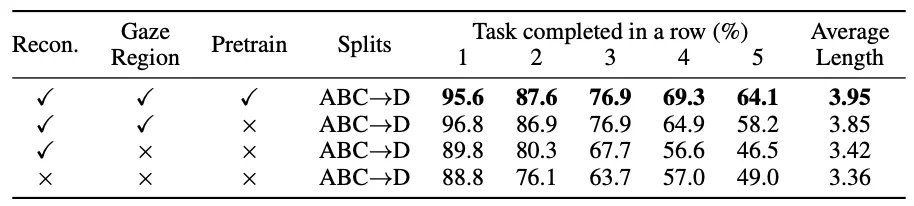
而消融实验表明:
1. 全图重建仍然由于仅有动作监督的基线,因为全图重建提升了模型的全局感知和理解能力。但由于视觉冗余使得在未知环境下难以展现更好的效果。
2. 重建目标区域(Gaze region)具有显著效果,这个机制使得模型专注于目标物体,避免被无关背景干扰。
3. 大规模预训练显著提升了模型在视觉重建,隐式 Grounding 及跨场景泛化的能力。
ReconVLA 的核心贡献并非引入更复杂的结构,而是重新审视了一个基础问题:机器人是否真正理解了它正在注视的世界。
通过重建式隐式监督,我们为 VLA 模型提供了一种更自然、更高效的视觉对齐机制,使机器人在复杂环境中做到「看得准、动得稳」。
我们期待这一工作能够推动具身智能从经验驱动的系统设计,迈向更加扎实、可扩展的通用智能研究范式。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
