# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,在GitHub上发现一个宝藏项目Project_Golem 。
一直以来,RAG 是解决知识时效性、事实性问题的核心方案,但RAG 调试的黑盒却一直是个问题:我们只能看到相似度分数,却无从知晓文档在向量空间的实际分布,更搞不懂为什么是这些文档被召回、为什么核心文档会漏召 / 误召,调优全凭经验瞎猜。
那么,到底是embedding模型选错了?chunking大小不合理?还是检索过程的索引算法选的有问题?
Project_Golem 的出现,提供了一些新的解决思路 :通过 UMAP 降维 + Three.js 渲染,我们可以将高维向量空间映射为 3D 可视化界面,让不同语义分块的空间分布、 RAG 的检索轨迹变得清晰可见,从而高效找到问题所在。
但原版 Project_Golem仅适用于小规模演示,无法满足生产级需求。
因此,在本文中,我们将结合Project_Golem以及 Milvus 2.6.8 的改造升级,解决了原架构的技术瓶颈,并让这套可视化方案具备了实时性、可扩展性和工程化能力。
想要理解 Project_Golem 的价值,我们要先搞懂 RAG 调试黑盒的本质问题:向量空间的高维性导致人类无法直观感知。
我们将文本转化为 768/1536 维的向量后,这些向量会在高维空间中形成聚类 —— 语义相似的文本向量会聚集在一起,语义无关的则会远离。但高维空间无法被人类直接观察,开发者能获取的只有两个信息:一是查询向量与文档向量的余弦相似度分数,二是最终被召回的文档列表。
这就导致了三个典型的调优问题:
我们看不到过程,也就没办法找到问题根源。而 Project_Golem 的核心,就是把这个看不见的高维向量空间,通过 UMAP 算法将 768/1536 维的高维向量降维至 3 维,再利用 Three.js 完成 3D 空间渲染,让所有文档向量以节点形式呈现在 3D 界面中,语义相似的节点会自然聚集形成簇;在线阶段,当用户发起查询时,先在高维空间计算余弦相似度完成检索,再根据返回的文档索引,在 3D 界面中 点亮对应的节点,检索结果的空间位置自然就能一目了然。
但原版的Project_Golem设计更偏向技术验证和演示,当文档量达到 10 万、100 万级时,其架构缺陷就会暴露,主要集中在静态数据、内存性能、工程能力三个方面。
静态数据:无法支持在线业务的增量更新
原版架构中,新增文档后需要重新生成完整的 npy 向量文件,并重跑全量 UMAP 降维,再更新 JSON 坐标文件。仅仅是10 万条文档的 UMAP 单核计算,就需要 5-10 分钟,若是百万级文档,耗时会呈指数级增长。
这就意味着,这套方案无法对接实时更新的业务数据,比如资讯、产品手册、用户对话等,只能用于静态文档的可视化演示。
内存与性能瓶颈:暴力搜索效率低
以 768 维 float32 向量为例,10 万条向量会占用 305MB 内存,100 万条直接达到 3GB,而原版架构采用NumPy 暴力搜索,时间复杂度为 O (n),单次查询在百万条数据下的延迟会超过 1 秒,远达不到在线服务的毫秒级响应要求。
工程能力需进一步优化
原版架构没有集成 HNSW、IVF 等主流的 ANN 近邻索引算法,也不支持标量过滤、多租户隔离、混合检索等生产环境必需的特性。
比如实际业务中,我们需要按照文档类别、发布时间、权限等级等标量条件过滤检索结果,而原版架构完全无法实现,只能做纯向量检索,与实际生产需求有些脱节。
原版 Project_Golem 的根本问题,在于数据流的断裂:新增文档→重生成 npy→重跑 UMAP→更新 JSON,整个链路串行且耗时,没有实现检索与可视化的解耦,也没有生产级的向量数据库做底层支撑。
而 Milvus 作为国内主流的云原生向量数据库,尤其是 2.6.8 版本引入的Streaming Node特性,恰好精准解决了原版架构的痛点,同时为可视化方案提供了工程化、规模化的底层能力。
针对实时性问题,Milvus 2.6.8 的 Streaming Node 无需依赖 Kafka/Pulsar 等外部消息队列,就能实现实时数据注入、增量索引更新—— 新增文档后,写入即可查询,检索索引会自动实时更新,彻底摆脱了全量重跑的困境。
同时,Milvus 实现了可视化层与检索层的完全解耦:检索层由 Milvus 负责高维向量的实时检索、索引优化,可视化层仅需根据 Milvus 返回的索引,在 3D 界面中完成节点点亮,两层互不干扰,各自迭代优化。
改造后,我们依然保留了原版的双路核心逻辑,同时将检索层全面替换为 Milvus,让整个方案具备生产级能力,两条路径的具体设计如下:
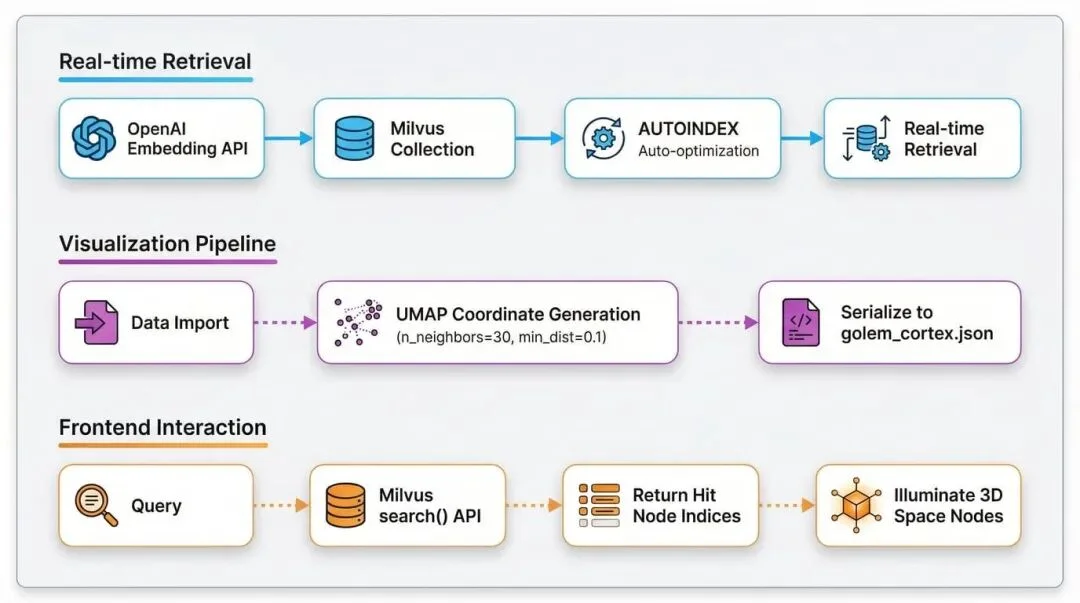
1.检索路径(毫秒级实时响应)
OpenAI embedding 生成查询向量 → 写入 Milvus Collection → Milvus AUTOINDEX 自动优化索引 → 实时余弦相似度检索并返回文档索引
2.可视化路径(当前实现,适配小规模演示)
数据导入时生成 UMAP 3D 坐标(n_neighbors=30, min_dist=0.1)→ 固化到 golem_cortex.json → 前端根据 Milvus 返回的索引点亮对应 3D 节点
而在规模化扩展方面,当前的混合架构已适配 1 万条以内的演示场景,若要支持百万级文档的动态更新,还能通过三个步骤实现增量可视化,让方案真正落地生产:
触发机制:监听 Milvus Collection 的插入事件,当累计新增文档超过 1000 条时,触发 UMAP 增量更新,避免频繁计算;
增量降维:使用 UMAP 的 transform () 方法,将新向量直接映射到已有 3D 空间,不去重跑全量 fit,大幅降低计算耗时;
前端同步:通过 WebSocket 向前端推送更新后的 JSON 坐标片段,前端动态添加新节点,无需刷新整个 3D 界面。
此外,Milvus 2.6.8 的混合检索能力(向量 + 全文 + 标量过滤)还为可视化方案预留了丰富的扩展空间 —— 后续可在 3D 界面中叠加关键词高亮、类别过滤、时间筛选等交互功能,让 RAG 调试的维度更丰富。
改造后的 Project_Golem 已开源至 GitHub,我们以Milvus 官方文档为数据集,一步步实现 RAG 检索的 3D 可视化,整个过程基于 Docker+Python,零基础也能快速上手。
完整项目仓库地址:https://github.com/yinmin2020/Project_Golem_Milvus
准备条件:
Docker >= 20.10 + Docker Compose >= 2.0
Python >= 3.11
OpenAI API Key
数据集(Milvus 官方文档 markdown 文件)
1.部署 milvus
下载docker-compose.yml
wget https://github.com/milvus-io/milvus/releases/download/v2.6.8/milvus-standalone-docker-compose.yml -O docker-compose.yml
启动Milvus(检查端口映射:19530:19530)
docker-compose up -d
验证服务启动
docker ps | grep milvus
应该看到3个容器:milvus-standalone, milvus-etcd, milvus-minio
2.核心实现
2.1 适配 Milvus 部分(ingest.py)
说明:支持最多 8 个类别,超出部分会循环使用颜色
from pymilvus import MilvusClient
from pymilvus.milvus_client.index import IndexParams
from openai import OpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
import umap
from sklearn.neighbors import NearestNeighbors
import json
import numpy as np
import os
import glob
--- CONFIG ---
MILVUS_URI = "http://localhost:19530"
COLLECTION_NAME = "golem_memories"
JSON_OUTPUT_PATH = "./golem_cortex.json"
数据文件夹(用户把 md 文件放在这里)
DATA_DIR = "./data"
OpenAI Embedding Config
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_BASE_URL = "https://api.openai.com/v1" #
OPENAI_EMBEDDING_MODEL = "text-embedding-3-small"
1536 dimensions
EMBEDDING_DIM = 1536
颜色映射(自动轮转分配颜色)
COLORS = [
[0.29, 0.87, 0.50],
Green
[0.22, 0.74, 0.97],
Blue
[0.60, 0.20, 0.80],
Purple
[0.94, 0.94, 0.20],
Gold
[0.98, 0.55, 0.00],
Orange
[0.90, 0.30, 0.40],
Red
[0.40, 0.90, 0.90],
Cyan
[0.95, 0.50, 0.90],
Magenta
]
def get_embeddings(texts):
"""Batch embedding using OpenAI API"""
client = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_BASE_URL)
embeddings = []
batch_size = 100
OpenAI allows multiple texts per request
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
response = client.embeddings.create(
model=OPENAI_EMBEDDING_MODEL,
input=batch
)
embeddings.extend([item.embedding for item in response.data])
print(f" ↳ Embedded {min(i + batch_size, len(texts))}/{len(texts)}...")
return np.array(embeddings)
def load_markdown_files(data_dir):
"""Load all markdown files from the data directory"""
md_files = glob.glob(os.path.join(data_dir, "**/*.md"), recursive=True)
if not md_files:
print(f" ❌ ERROR: No .md files found in '{data_dir}'")
print(f" 👉 Create a '{data_dir}' folder and put your markdown files there.")
print(f" 👉 Example: {data_dir}/doc1.md, {data_dir}/docs/doc2.md")
return None
docs = []
print(f"\n📚 FOUND {len(md_files)} MARKDOWN FILES:")
for i, file_path in enumerate(md_files):
filename = os.path.basename(file_path)
相对于 data_dir 的路径作为类别
rel_path = os.path.relpath(file_path, data_dir)
category = os.path.dirname(rel_path) if os.path.dirname(rel_path) else "default"
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
docs.append({
"title": filename,
"text": content,
"cat": category,
"path": file_path
})
print(f" {i+1}. [{category}] {filename}")
return docs
def ingest_dense():
print(f"🧠 PROJECT GOLEM - NEURAL MEMORY BUILDER")
print(f"=" * 50)
if not OPENAI_API_KEY:
print(" ❌ ERROR: OPENAI_API_KEY environment variable not set!")
print(" 👉 Run: export OPENAI_API_KEY='your-key-here'")
return
print(f" ↳ Using OpenAI Embedding: {OPENAI_EMBEDDING_MODEL}")
print(f" ↳ Embedding Dimension: {EMBEDDING_DIM}")
print(f" ↳ Data Directory: {DATA_DIR}")
1. Load local markdown files
docs = load_markdown_files(DATA_DIR)
if docs is None:
return
2. Split documents into chunks
print(f"\n📦 PROCESSING DOCUMENTS...")
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=50)
chunks = []
raw_texts = []
colors = []
chunk_titles = []
categories = []
for doc in docs:
doc_chunks = splitter.create_documents([doc['text']])
cat_index = hash(doc['cat']) % len(COLORS)
for i, chunk in enumerate(doc_chunks):
chunks.append({
"text": chunk.page_content,
"title": doc['title'],
"cat": doc['cat']
})
raw_texts.append(chunk.page_content)
colors.append(COLORS[cat_index])
chunk_titles.append(f"{doc['title']} (chunk {i+1})")
categories.append(doc['cat'])
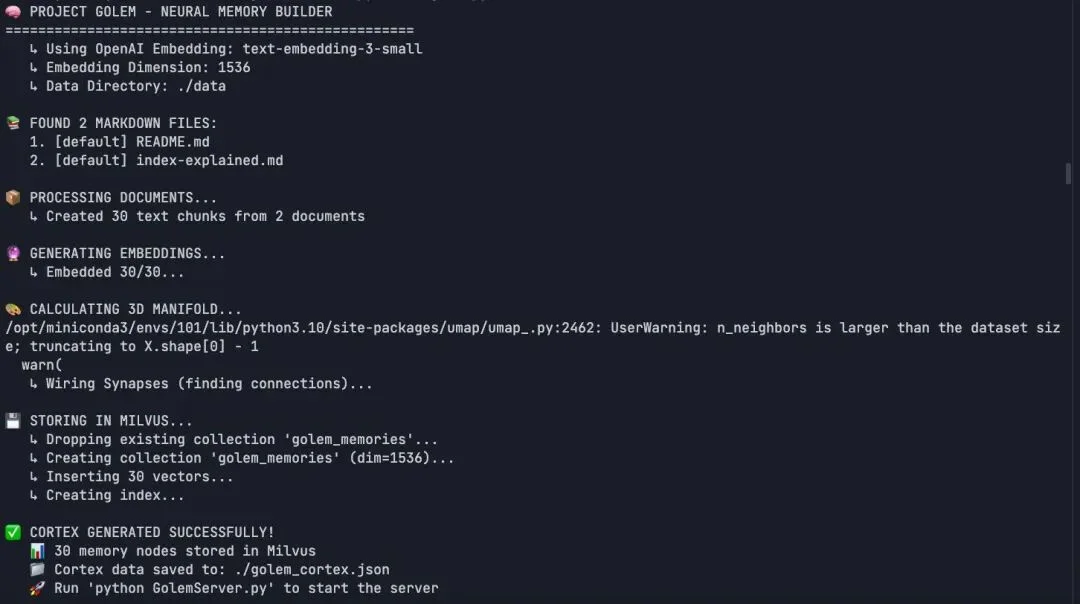
print(f" ↳ Created {len(chunks)} text chunks from {len(docs)} documents")
3. Generate embeddings
print(f"\n🔮 GENERATING EMBEDDINGS...")
vectors = get_embeddings(raw_texts)
4. 3D Projection (UMAP)
print("\n🎨 CALCULATING 3D MANIFOLD...")
reducer = umap.UMAP(n_components=3, n_neighbors=30, min_dist=0.1, metric='cosine')
embeddings_3d = reducer.fit_transform(vectors)
5. Wiring (KNN)
print(" ↳ Wiring Synapses (finding connections)...")
nbrs = NearestNeighbors(n_neighbors=8, metric='cosine').fit(vectors)
distances, indices = nbrs.kneighbors(vectors)
6. Prepare output data
cortex_data = []
milvus_data = []
for i in range(len(chunks)):
cortex_data.append({
"id": i,
"title": chunk_titles[i],
"cat": categories[i],
"pos": embeddings_3d[i].tolist(),
"col": colors[i],
"nbs": indices[i][1:].tolist()
})
milvus_data.append({
"id": i,
"text": chunks[i]['text'],
"title": chunk_titles[i],
"category": categories[i],
"vector": vectors[i].tolist()
})
with open(JSON_OUTPUT_PATH, 'w') as f:
json.dump(cortex_data, f)
7. Store vectors in Milvus
print("\n💾 STORING IN MILVUS...")
client = MilvusClient(uri=MILVUS_URI)
Drop existing collection if it exists
if client.has_collection(COLLECTION_NAME):
print(f" ↳ Dropping existing collection '{COLLECTION_NAME}'...")
client.drop_collection(COLLECTION_NAME)
Create new collection
print(f" ↳ Creating collection '{COLLECTION_NAME}' (dim={EMBEDDING_DIM})...")
client.create_collection(
collection_name=COLLECTION_NAME,
dimension=EMBEDDING_DIM
)
Insert data
print(f" ↳ Inserting {len(milvus_data)} vectors...")
client.insert(
collection_name=COLLECTION_NAME,
data=milvus_data
)
Create index for faster search
print(" ↳ Creating index...")
index_params = IndexParams()
index_params.add_index(
field_name="vector",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.create_index(
collection_name=COLLECTION_NAME,
index_params=index_params
)
print(f"\n✅ CORTEX GENERATED SUCCESSFULLY!")
print(f" 📊 {len(chunks)} memory nodes stored in Milvus")
print(f" 📁 Cortex data saved to: {JSON_OUTPUT_PATH}")
print(f" 🚀 Run 'python GolemServer.py' to start the server")
if __name__ == "__main__":
ingest_dense()
2.2 前端可视化部分(GolemServer.py)
from flask import Flask, request, jsonify, send_from_directory
from openai import OpenAI
from pymilvus import MilvusClient
import json
import os
import sys
--- CONFIG ---
Explicitly set the folder to where this script is located
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
OpenAI Embedding Config
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
OPENAI_BASE_URL = "https://api.openai.com/v1"
OPENAI_EMBEDDING_MODEL = "text-embedding-3-small"
Milvus Config
MILVUS_URI = "http://localhost:19530"
COLLECTION_NAME = "golem_memories"
These match the files generated by ingest.py
JSON_FILE = "golem_cortex.json"
UPDATED: Matches your new repo filename
HTML_FILE = "index.html"
app = Flask(__name__, static_folder=BASE_DIR)
print(f"\n🧠 PROJECT GOLEM SERVER")
print(f" 📂 Serving from: {BASE_DIR}")
--- DIAGNOSTICS ---
Check if files exist before starting
missing_files = []
if not os.path.exists(os.path.join(BASE_DIR, JSON_FILE)):
missing_files.append(JSON_FILE)
if not os.path.exists(os.path.join(BASE_DIR, HTML_FILE)):
missing_files.append(HTML_FILE)
if missing_files:
print(f" ❌ CRITICAL ERROR: Missing files in this folder:")
for f in missing_files:
print(f" - {f}")
print(" 👉 Did you run 'python ingest.py' successfully?")
sys.exit(1)
else:
print(f" ✅ Files Verified: Cortex Map found.")
Check API Key
if not OPENAI_API_KEY:
print(f" ❌ CRITICAL ERROR: OPENAI_API_KEY environment variable not set!")
print(" 👉 Run: export OPENAI_API_KEY='your-key-here'")
sys.exit(1)
print(f" ↳ Using OpenAI Embedding: {OPENAI_EMBEDDING_MODEL}")
print(" ↳ Connecting to Milvus...")
milvus_client = MilvusClient(uri=MILVUS_URI)
Verify collection exists
if not milvus_client.has_collection(COLLECTION_NAME):
print(f" ❌ CRITICAL ERROR: Collection '{COLLECTION_NAME}' not found in Milvus.")
print(" 👉 Did you run 'python ingest.py' successfully?")
sys.exit(1)
Initialize OpenAI client
openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_BASE_URL)
--- ROUTES ---
@app.route('/')
def root():
Force serve the specific HTML file
return send_from_directory(BASE_DIR, HTML_FILE)
@app.route('/')
def serve_static(filename):
return send_from_directory(BASE_DIR, filename)
@app.route('/query', methods=['POST'])
def query_brain():
data = request.json
text = data.get('query', '')
if not text: return jsonify({"indices": []})
print(f"🔎 Query: {text}")
Get query embedding from OpenAI
response = openai_client.embeddings.create(
model=OPENAI_EMBEDDING_MODEL,
input=text
)
query_vec = response.data[0].embedding
Search in Milvus
results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[query_vec],
limit=50,
output_fields=["id"]
)
Extract indices and scores
indices = [r['id'] for r in results[0]]
scores = [r['distance'] for r in results[0]]
return jsonify({
"indices": indices,
"scores": scores
})
if __name__ == '__main__':
print(" ✅ SYSTEM ONLINE: http://localhost:8000")
app.run(port=8000)
3.下载数据集存放指定目录
https://github.com/milvus-io/milvus-docs/tree/v2.6.x/site/en
4. 启动项目
4.1 文本向量化映射到 3D 空间
python ingest.py
4.2 启动前端服务
python GolemServer.py
5.可视化交互
前端接收检索结果后,根据相似度分数映射节点亮度,保持原颜色不变以维持类别簇的视觉连续性。同时绘制从查询点到命中节点的半透明连线,摄像机平滑聚焦到激活簇所在区域。
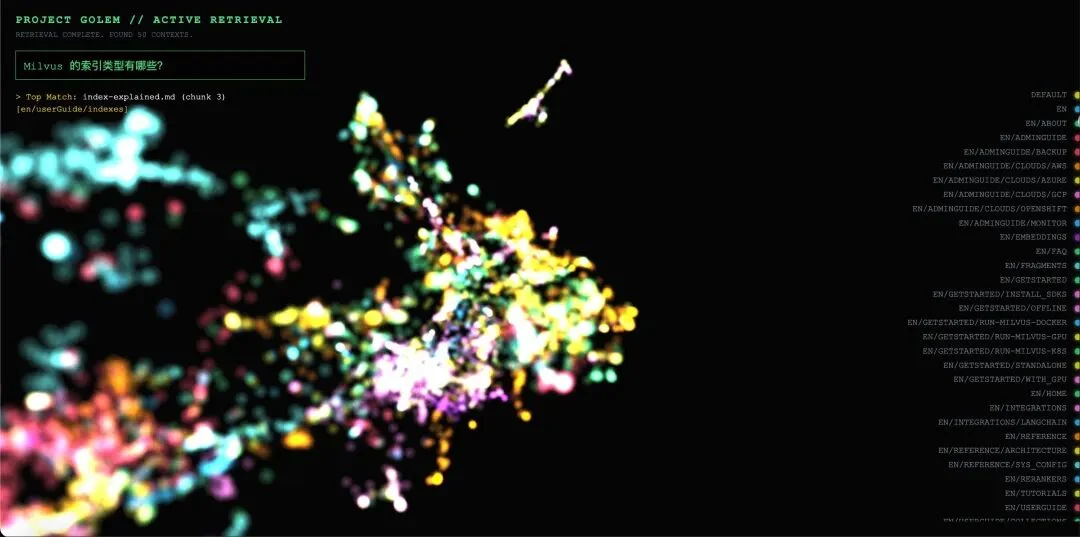
5.1 案例 1:领域内匹配
查询:“Milvus 支持哪些索引类型?”
可视化反馈:
5.2 案例 2:领域外查询的拒绝表现
查询:“KFC 优惠套餐多少钱?”
可视化反馈:
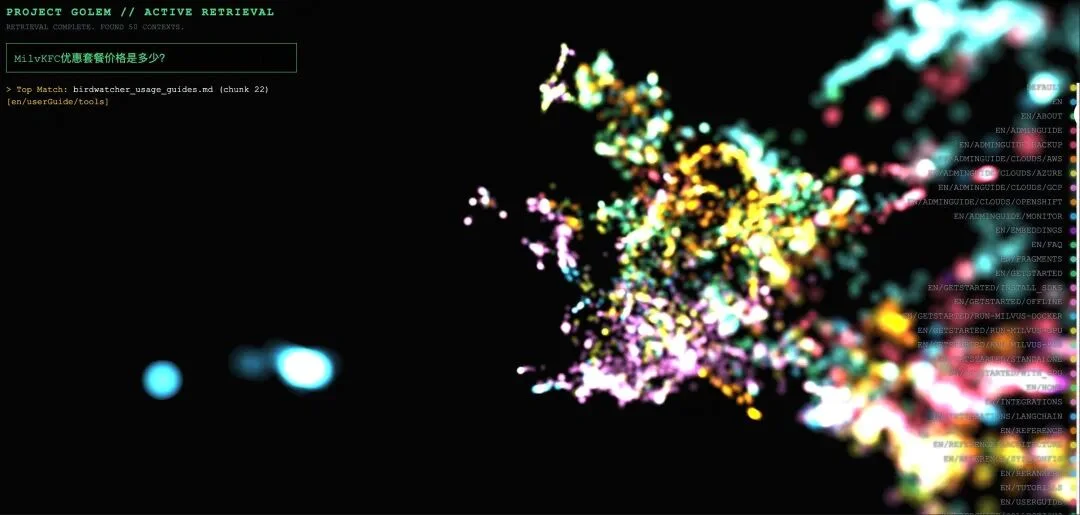
Project_Golem 结合 Milvus 的改造升级,本质上是一个实验性但极具参考意义的项目,它的核心价值并非只是实现了 RAG 检索的 3D 可视化,更是为行业解决RAG 可解释性问题提供了全新的技术思路。
在这套方案之前,RAG 调优是 “凭经验、看结果、瞎调参”;而在这套方案之后,开发者能通过可视化界面完成三个核心调优动作:
观察语义空间结构:判断 embedding 模型的向量化效果,看语义相似的文档是否形成合理聚类;
定位检索策略问题:分析漏召 / 误召的原因,是索引参数设置不合理,还是文本分块导致的语义碎片化;
验证调优效果:调优后能直观看到向量空间的变化、检索轨迹的优化,让调优有了可量化、可可视化的依据。
相信随着向量数据库的不断发展,以及可解释性技术的持续迭代,RAG 调试的黑盒问题会被彻底解决,让大模型应用的落地更高效、更稳定。
文章来自于“Zilliz”,作者 “尹珉”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
