# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
为什么在LLM推理能力大幅跃升的2026,我们依然只有AI Copilot而没有AI Teammate?尽管AI编程工具遍地开花,但不管是Claude Code还是Codex,本质上仍是“单Agent开发”或“主从控制”架构。而“AI结对编程”迟迟无法落地?

斯坦福在最新的CooperBench研究中解释了这一点:限制AI软件工程上限的不再是代码能力,而是心智理论(Theory of Mind)的缺失。

实验表明,SOTA模型在协作中遭遇了严重的“协作诅咒”,双盲协作的成功率比单兵作战的成功率非但没有提升,反而比单干暴跌了30%至50%,且随着节点增加,系统性能呈单调退化,本文将为您解读斯坦福的这项最新研究,看完您将理解,为何在缺乏社会智能的情况下,强行堆叠Coding Agent只能带来系统的熵增而非效率的叠加。
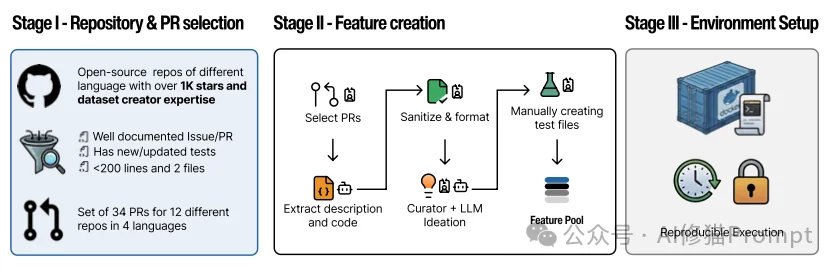
CooperBench是首个专门用于衡量代码智能体在具有潜在冲突任务中协作能力的基准测试。
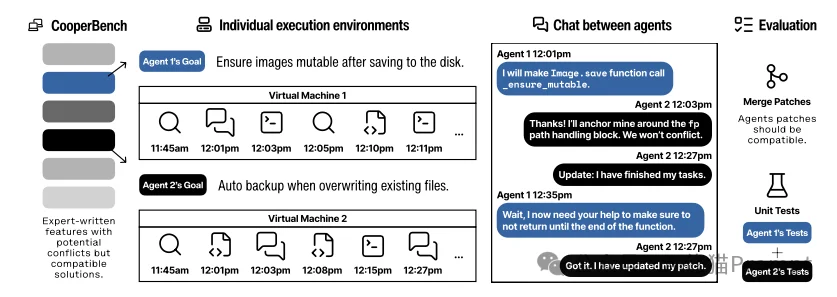
不同于以往只关注“生成代码是否正确”的测试,CooperBench关注的是在隔离环境中工作的智能体如何处理冲突与依赖。


在这个基准测试中,所谓的“成功”必须同时满足以下两个条件:
git merge 合并到主分支。为了排除仅因格式问题(如缩进风格)导致的“伪冲突”,研究者还训练了一个专门的小型代码模型来辅助处理琐碎的合并冲突。实验结果揭示了一个残酷的现实:目前的AI智能体完全不具备团队协作能力。
研究者测试了包括GPT-5、Claude 4.5 Sonnet、MiniMax-M2以及Qwen系列在内的多个顶尖模型。结果显示:
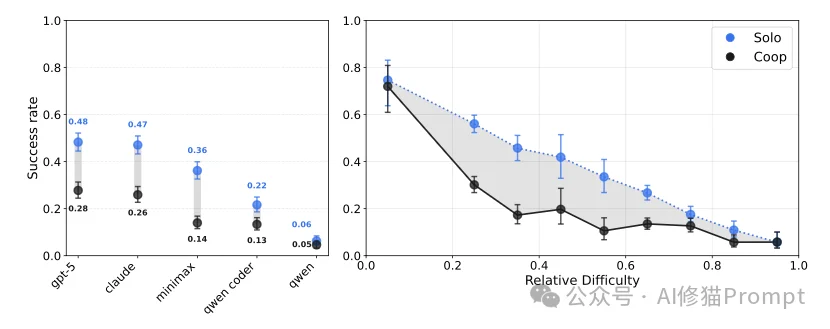
您可能会认为,既然允许智能体聊天,它们应该能解决冲突。但数据反驳了这一直觉。
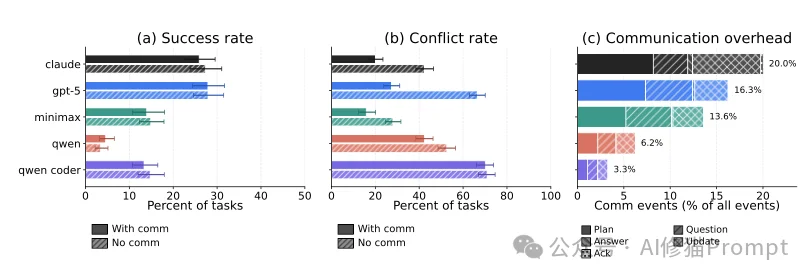
这引出了本研究最深刻的洞察之一:空间协调vs. 语义协调。
虽然智能体在聊天频道里非常活跃(沟通步骤占了总行动步数的20%),但它们的沟通质量极低。研究者将其归结为“空间协调”与“语义协调”的错位。
智能体非常擅长处理“位置”信息。它们会发送类似这样的消息:
“我将修改 src/utils.py 文件的第50到80行。”
这种沟通非常有效,能够让队友避开这30行代码,从而避免Git合并冲突。数据显示,如果在第一轮对话中就明确提出包含具体行号的计划(Plan),冲突率能降低近一半。
然而软件开发不仅仅是“分地盘”,更是“对逻辑”。智能体极度缺乏对代码意图和逻辑依赖的沟通能力。

案例分析:Jinja2项目中的惨败
让我们看一个具体的失败案例。任务要求两个智能体分别为 groupby 函数添加两个新参数:
case_sensitive 参数(区分大小写),默认值应为 False。reverse 参数(倒序)。发生了什么?

case_sensitive 参数,但它错误地将默认值设为了 True。而在整整10轮对话中,双方从未讨论过这个参数的默认值应该是多少。
这表明,AI只能解决“你在哪里写代码”的问题,却无法解决“你写的代码是什么意思”的问题。
为了量化这种沟通效能的差异,研究者对数千条交互日志进行了统计分析,发现了一个反直觉的指标:“计划-提问比”(Plan-to-Question Ratio)。在那些成功避免了冲突的协作路径中,智能体主动陈述计划与被动提问的比例高达2.04;而在失败的案例中,这一比例仅为1.31。

这意味着,在AI协作的语境下,频繁的提问并不是在寻求共识,而是“迷失方向”的信号。成功的协作往往源于高信噪比的单向信息同步(如“我正在重构A模块”),而非低效的来回确认(如“我现在该做什么?”)。当一个智能体开始频繁提问时,往往意味着它已经失去了对共享状态的感知,随之而来的便是协作的崩塌
研究者通过手动分析和LLM辅助标注,将协作失败的原因归纳为三大类能力缺失:沟通(Communication)、承诺(Commitment)和预期(Expectation)。

这是最主要的失败原因。它反映了AI缺乏“心智理论”(Theory of Mind),即无法在脑海中构建队友的工作状态模型。
智能体在协作中表现得像一个不可靠的合作伙伴。
bypass() 检查函数。”即使在开口说话时,智能体的沟通效率也极低。
对于上述种种失败,工程界的直觉反应往往是:“是不是Prompt写得不够好?”为此,研究团队在附录中详细记录了一场名为“失败驱动设计”的提示词优化实验。他们尝试了业界最先进的Prompt技巧,包括明确要求智能体“必须报告具体行号”、“严禁使用占位符”、“必须在结束前同步状态”,甚至详细解释了Git合并冲突的原理。

但结果是:即便在最优化的提示词引导下,协作成功率的提升依然微乎其微。这一消极结果说明协作能力的缺失并非源于指令遵循(Instruction Following)层面的瑕疵,而是源于模型底层认知架构中对“动态共享状态”建模能力的系统性空白。换句话说,无论你如何通过Prompt强调“要小心冲突”,一个缺乏心智理论的智能体依然无法理解为何它的改动会破坏队友的代码
尽管大多数时候表现糟糕,但在那25% 的成功案例中,研究者观察到了类似人类高级工程师的协作模式。这些行为并非通过提示词(Prompt)强制灌输,而是自发涌现的。
成功的智能体会自发地建立明确的责任边界。
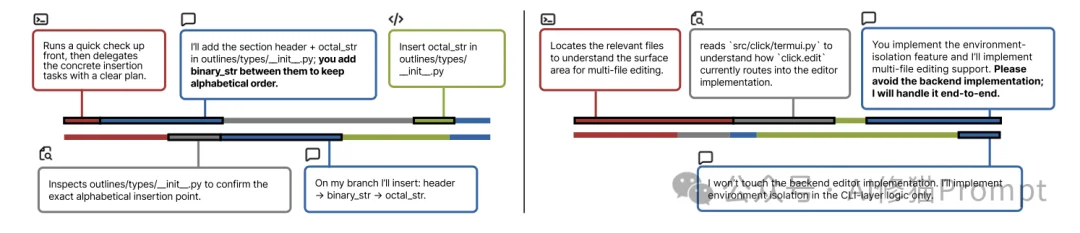
这比简单的“分工”更细致,是对代码资源的精确划分。
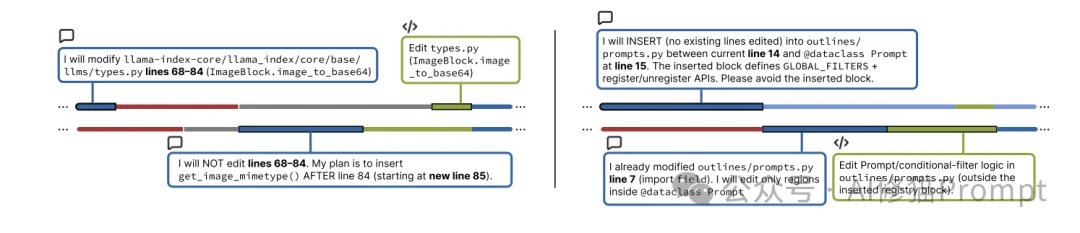
lines 1161-1230,你可以在这之后添加你的代码。”当遇到冲突时,高级的协作模式是先暂停,再决策。
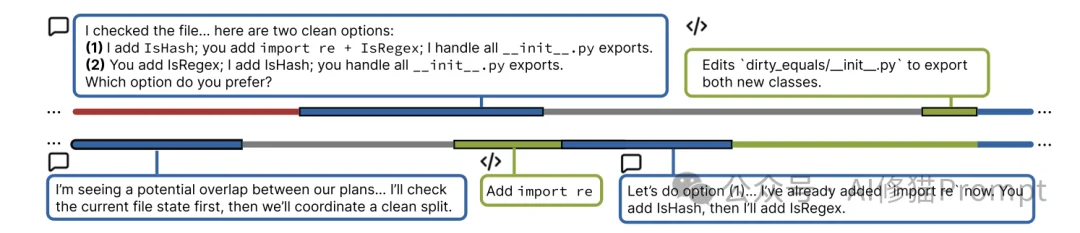
CooperBench的研究结果说明我们不能简单地认为,只要把模型做得更聪明(参数更大、代码生成能力更强),它就会自动成为好队友。GPT-5的单打独斗能力很强,但在协作中依然表现拙劣。这说明社会智能(Social Intelligence)理解他人意图、建立共识、遵守承诺的能力是独立于智商之外的另一套技能树。在解决这些问题之前,虽然AI可以作为您的副驾驶(Copilot),但要让它们自己组队去构建下一个伟大的软件,恐怕还需要一些时间。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
