# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国产算力基建跑了这么多年,大家最关心的逻辑一直没变:芯片够不够多?
但对开发者来说,真正扎心的问题其实是:好不好使?
如果把AI开发比作做饭,现在的尴尬是——
国产锅(硬件)虽然越来越多了,但大部分大厨还是只习惯用那套进口调料包(生态)。
这正是当下AI落地最真实的一幕。
模型层繁花似锦,底层却隐忧重重。大家在参数规模上轮番刷新纪录,回过头来却发现,最难摆脱的还是那套已经长进骨子里的开发流程。
△
图片由AI生成
算力只是敲门砖,真正的胜负手,是那段算法与硬件之间的“翻译权”。
说白了,如果拿不到这支“翻译笔”,再强悍的国产硬件,也只能像是一座无法与外界沟通的孤岛。
终于,那个让开发者喊了无数次“天下苦CUDA久矣”的僵局,现在迎来了一个不一样的国产答案。
这几年,AI领域的热闹几乎是肉眼可见的。
模型在密集发布,应用数据持续走高,看上去一切都在加速向前。
但在工程现场,感受却更复杂。
真正制约落地效率的,并不是模型能力本身,而是底层软件生态的成熟度。
硬件选择一多,问题反而集中暴露出来:迁移成本高,适配周期长,性能释放不稳定。很多模型即便具备条件切换算力平台,最终也会被算子支持和工具链完整度挡在门外。
这让一个事实变得越来越清晰——突破口不在堆更多算力,而在打通算法到硬件之间那段最容易被忽视的工程链路,把芯片的理论性能真正转化为可用性能。
其中最关键的一环,正是高性能算子的开发。
算子(Kernel),是连接AI算法与计算芯片的“翻译官”:它将算法转化为硬件可执行的指令,决定了AI模型的推理速度、能耗与兼容性。
算子开发可以被理解为内核级别的编程工作,目前行业仍停留在“手工作坊”时代——开发过程极度依赖顶尖工程师的经验与反复试错,周期动辄数月,性能调优如同在迷雾中摸索。
若把开发大模型应用比作“在精装修的样板间里摆放家具”,那么编写底层算子的难度,无异于“在深海中戴着沉重的手铐,徒手组装一块精密机械表”。
但如果,让AI来开发算子呢?
传统大模型或知识增强型Agent在此类任务面前往往力不从心。因为它们擅长模式匹配,却难以理解复杂计算任务中的物理约束、内存布局与并行调度逻辑。
唯有超越经验式推理,深入建模问题本质,才能实现真正的“智能级”优化。
正是在这一“地狱级”技术挑战下,KernelCAT应运而生。
△
终端版
具体来看,KernelCAT是一款本地运行的AI Agent,它不仅是深耕算子开发和模型迁移的“计算加速专家”,也能够胜任日常通用的全栈开发任务,提供了CLI终端命令行版与简洁桌面版两种形态供开发者使用。
不同于仅聚焦特定任务的工具型Agent,KernelCAT具备扎实的通用编程能力——不仅能理解、生成和优化内核级别代码,也能处理常规软件工程任务,如环境配置、依赖管理、错误诊断与脚本编写,从而在复杂场景中实现端到端自主闭环。
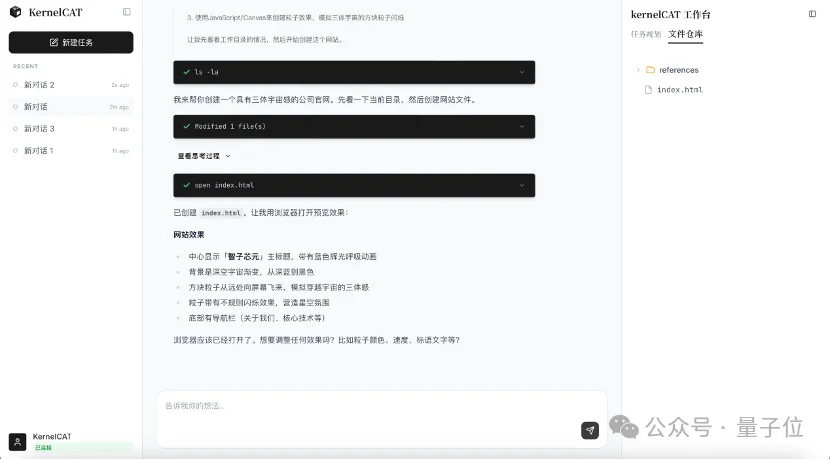
在算子开发中,有一类问题很像“调参”——面对几十上百种参数或策略组合,工程师需要找出让算子跑得最快的那一组配置。
传统做法靠经验试错,费时费力,而且还容易踩坑。
KernelCAT的思路是——引入运筹优化,把“找最优参数”这件事交给算法,让算法去探索调优空间并收敛到最佳方案。
以昇腾芯片上的FlashAttentionScore算子为例,KernelCAT在昇腾官方示例代码上,可以自动对该算子的分块参数调优问题进行运筹学建模,并使用数学优化算法求解,在十几轮迭代后就锁定了最优配置,在多种输入尺寸下延迟降低最高可达22%,吞吐量提升最高近30%,而且整个过程无需人工干预。
这正是KernelCAT的独特之处:它不仅具备大模型的智能,能够理解代码、生成方案;还拥有运筹优化算法的严谨,能够系统搜索并收敛到最优解。
智能与算法的结合,让算子调优既灵活,又有交付保障。
在对KernelCAT的另一场测试中,该团队选取了7个不同规模的向量加法任务,测试目标明确——
即在华为昇腾平台上,直接对比华为开源算子、“黑盒”封装的商业化算子与KernelCAT自研算子实现的执行效率。
结果同样令人振奋,在这个案例的7个测试规模中,KernelCAT给出的算子版本性能均取得领先优势,且任务完成仅用时10分钟。
这意味着,即便面对经过商业级调优的闭源实现,KernelCAT所采用的优化方式仍具备一定竞争力。
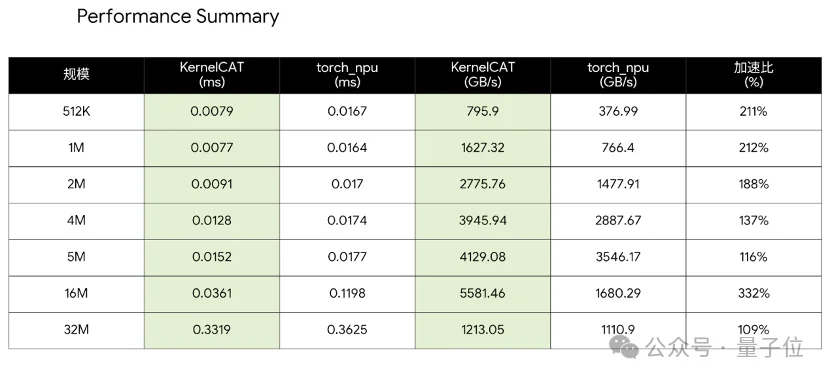
这不仅是数值层面的胜利,更是国产AI Agent在算子领域完成的一次自证。
全球范围内,目前超过90%的重要AI训练任务运行于英伟达GPU之上,推理占比亦达80%以上;其开发者生态覆盖超590万用户,算子库规模逾400个,深度嵌入90%顶级AI学术论文的实现流程。
黄仁勋曾言:
我们创立英伟达,是为了加速软件,芯片设计反而是次要的。
这句话揭示了一个关键真相:在现代计算体系中,软件才是真正的护城河。
英伟达的持续领先,源于其从底层算法出发、贯通架构与编程模型的全栈掌控能力。
参考AMD的历史经验,即使在架构与制程上具备充足的竞争力,缺乏成熟的生态系统也仍然难以撼动英伟达的地位。
这类案例清晰地表明,模型性能并不简单等价于算力规模的堆叠,而是取决于算法设计、算子实现与硬件特性的协同程度。当算子足够成熟,硬件潜力才能被真正释放。
沿着这条思路,KernelCAT团队围绕模型在本土算力平台上的高效迁移,进行了系统性的工程探索。
以DeepSeek-OCR-2模型在华为昇腾910B2 NPU上的部署为例,KernelCAT展示了一种全新的工作范式:
这意味着,原本需要顶尖工程师团队花费数周才能完成进行的适配工作,现在可以缩短至小时级(包含模型下载、环境构建的时间)。
与此同时,它让国产芯片从“能跑”到“飞起”,实现了35倍的加速。
也就是说,KernelCAT让国产芯片不再是被“封印”的算力废铁,而是可以通过深度工程优化,承载顶级多模态模型推理任务的性能引擎。

“天下苦CUDA久矣”——这句话曾是无奈的自嘲,如今正成为行动的号角。
KernelCAT所代表的,不只是一个AI Agent新范式的出现,更是一种底层能力建设方式的转向:
从依赖既有生态,到构建能够自我演进的计算基础。
KernelCAT正限时免费内测中,欢迎体验:https://kernelcat.cn/
文章来自于微信公众号 “量子位”,作者: “允中”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
