# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
国产开源具身世界模型,直接秒了Pi-0.5,而且还是几位清华硕、博士研究生领衔推出的。

这就是由生数科技联合清华大学,正式开源的大一统世界模型——Motus。
项目主要负责人,是来自清华大学计算机系朱军教授TSAIL实验室的二年级硕士生毕弘喆和三年级博士生谭恒楷。
之所以说是大一统,是因为Motus在架构上,直接把VLA(视觉-语言-动作)、世界模型、视频生成、逆动力学、视频-动作联合预测这五种具身智能范式,首次实现了“看-想-动”的完美闭环。
而且在50项通用任务的测试中,Motus的绝对成功率比国际顶尖的Pi-0.5提升了35%以上,最高提升幅度甚至达到了40%!
在Motus的加持之下,现在的机器人已经具备了预测未来的能力。
瞧,Cloudflare人机验证任务,机器人可以轻松拿捏:
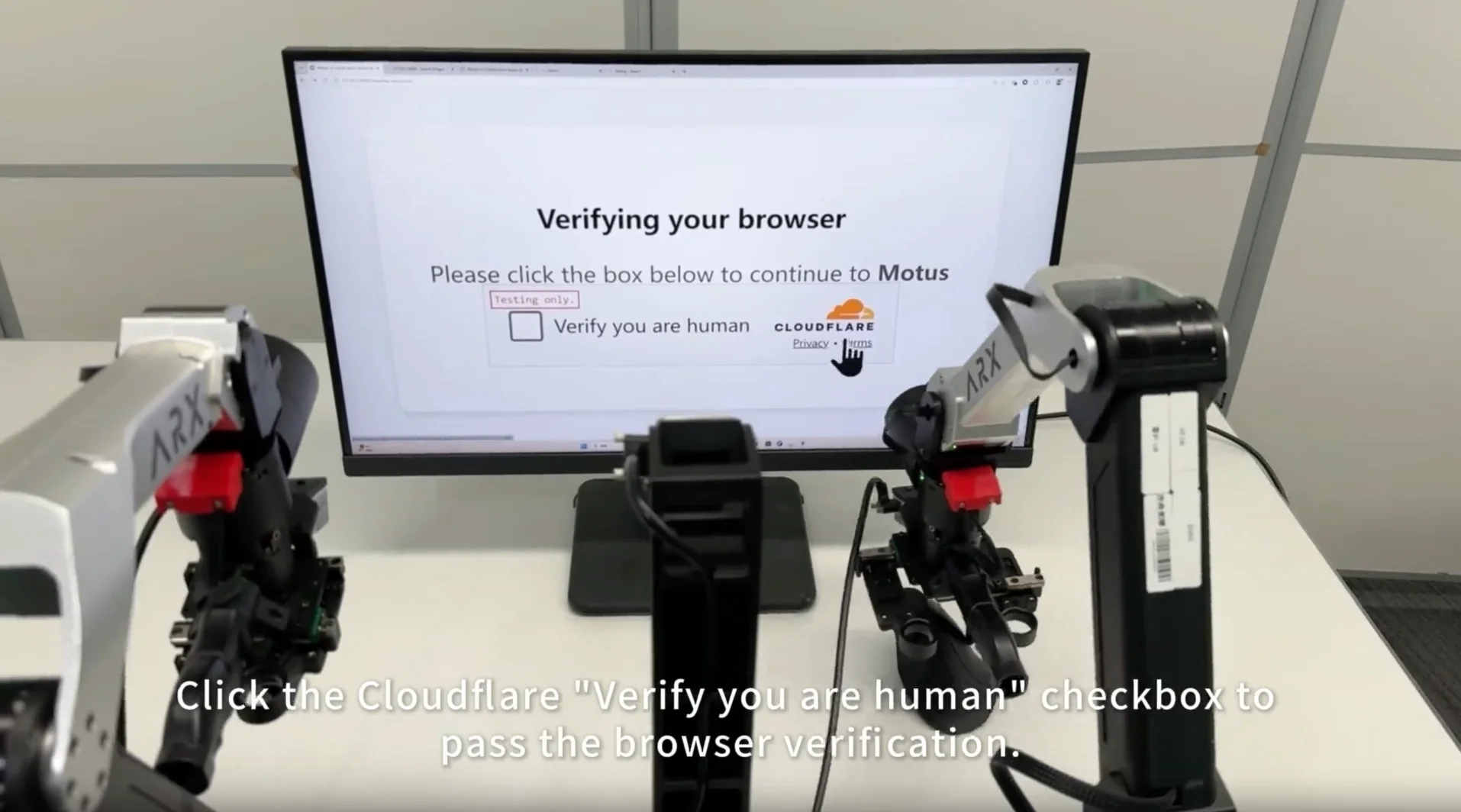
从视频中不难看出,面对形状不规则的曲面鼠标,Motus控制的机械臂不仅能精准识别,还能根据鼠标与屏幕点击框的距离,平稳连续地移动,最后极度精准地完成点击。
再如长程多步推理的孔明棋任务,Motus同样展现出了严密的逻辑闭环,一步步解开棋局:

再来看一个堪称是机器人噩梦的任务——叠衣服:

衣服这种柔性物体的形变是过程中持续不断发生的,但在Motus手下,整个过程丝滑顺畅,就像有了人类的触觉和预判一样。
可以说,Motus的出现,率先在具身智能领域发现了Scaling Law,直接复刻了当年GPT-2被定义为“无监督多任务学习者”的奇迹。
很多CTO、创始人们看完之后直呼“妙哉”:
这是互联网视频学习与现实世界机器人之间的巧妙桥梁。
Motus的Latent Action范式太妙了。统一的VLA架构消除了机器人学中的模型碎片化,这才是真正的突破。
将感知、预测和行动统一在智能体内部确实是实质性的进展。
包括此前大火的英伟达Cosmos policy、DreamZero这些工作,被认为是颠覆了VLA的范式,转向WA(World Action Models)或VA(Vision Action)范式;但其核心思想与Motus相近,大同小异。
目前,Motus的代码、模型权重已全部开源(链接在文末)。
那么接下来,我们就来扒一扒这个大一统世界模型是如何实现的。
在过去,具身智能领域可以说是散装的。
因为像VLA、世界模型、视频生成、逆动力学、视频-动作联合预测等模型,很难有机地凑成一个整体。
而Motus最大的亮点,在一个框架内把这五种范式全包圆了。
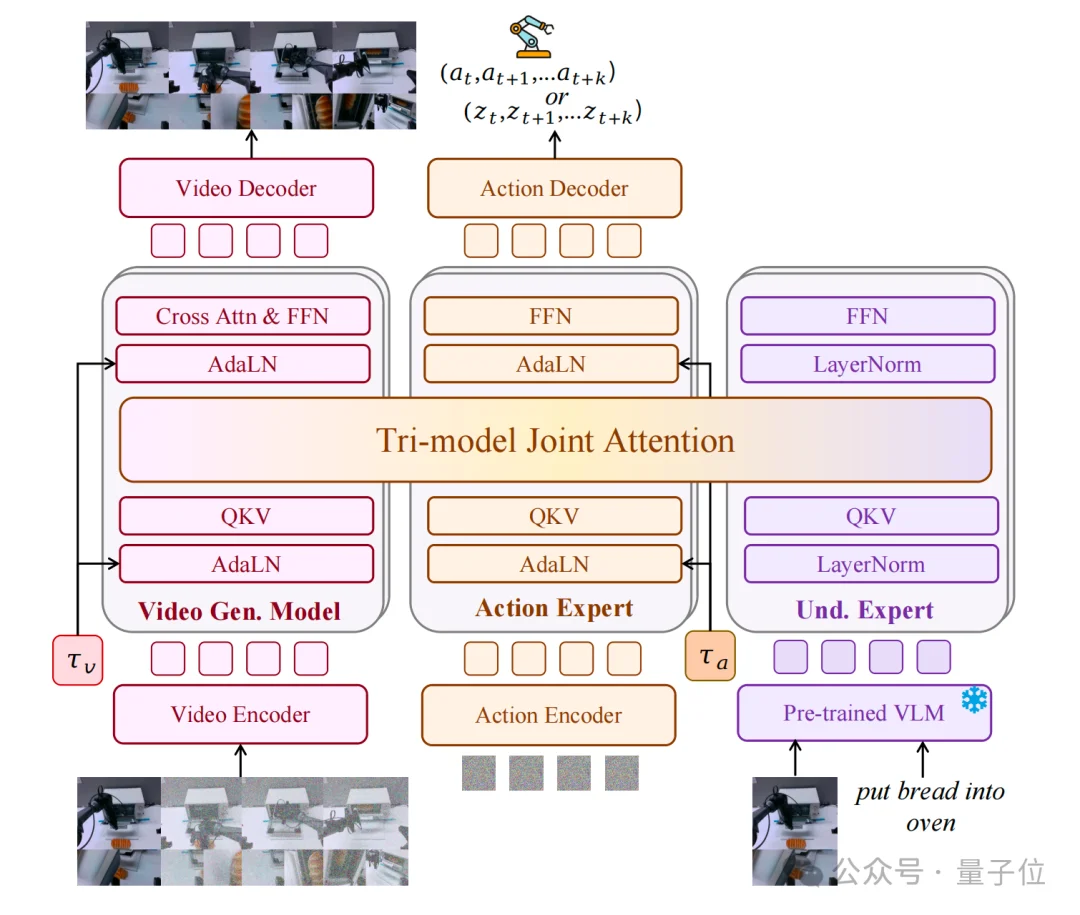
大一统背后的技术,便是Mixture-of-Transformer(MoT)架构,配合Tri-model Joint Attention(三模态联合注意力)机制。
简单来说,通过这种方式,Motus相当于把三个专家攒到了一起:
通过Tri-model Joint Attention,这三位专家可以在同一个注意力层里实时交换信息。
这就赋予了机器人一种很像人类的能力:不仅能看见(感知),还能在脑海里想象动作发生后的未来画面(预测),从而反过来倒推现在该做什么动作(决策)。
这正是我们刚才提到的“看—想—动”闭环。
但要训练这样一个全能模型,光在模型框架层面下功夫还是不够的——数据,也是一个老大难的问题。
因为机器人真机数据太贵、太少,而互联网上虽然有海量的视频,却只有画面,没有动作标签(Action Label)。
为了解决这个问题,Motus采取的策略便是潜动作(Latent Action)。
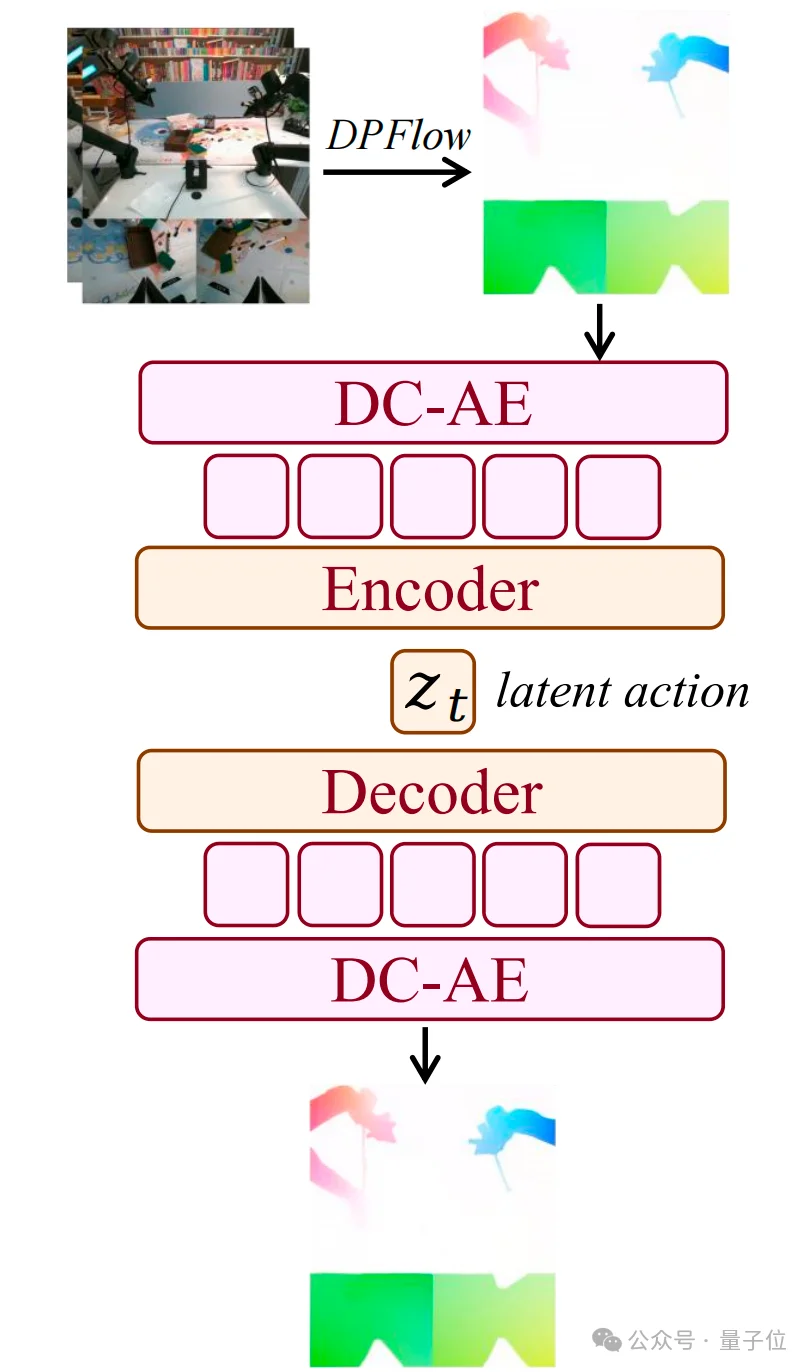
研究团队利用光流技术(Optical Flow),捕捉视频里像素级的运动轨迹,然后提出了一种Delta Action机制,将这些像素的变化翻译成机器人的动作趋势。
这个思路可以说是比较巧妙,就像是让机器人看武侠片学功夫。
虽然没有人手把手教(没有真机数据标签),但机器人通过观察视频里高手的动作轨迹(光流),看多了自然就懂了招式和发力方向(潜动作)。
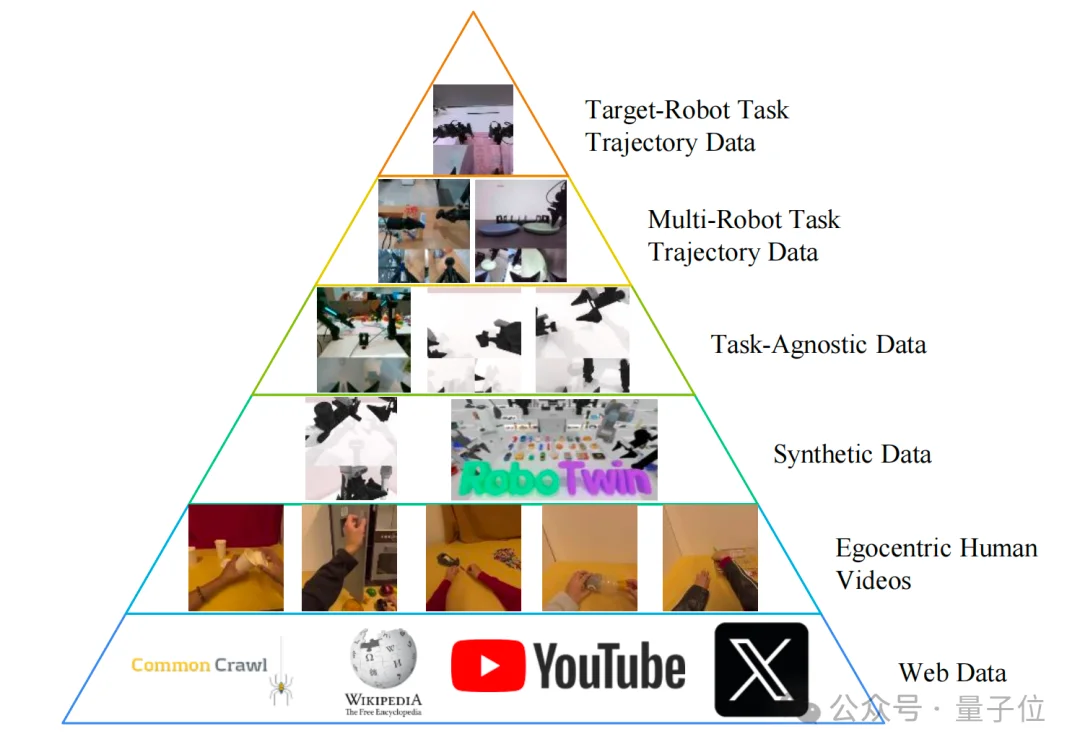
由此,上至昂贵的真机数据,下至浩如烟海的互联网视频、人类第一视角视频(Egocentric Video),Motus全都能吃进去,从中提取通用的物理交互先验。
除此之外,基于数据金字塔和潜动作,Motus还构建了一套三阶段训练流程,逐步将通用的物理动力学常识“蒸馏”为精确的机器人控制能力:
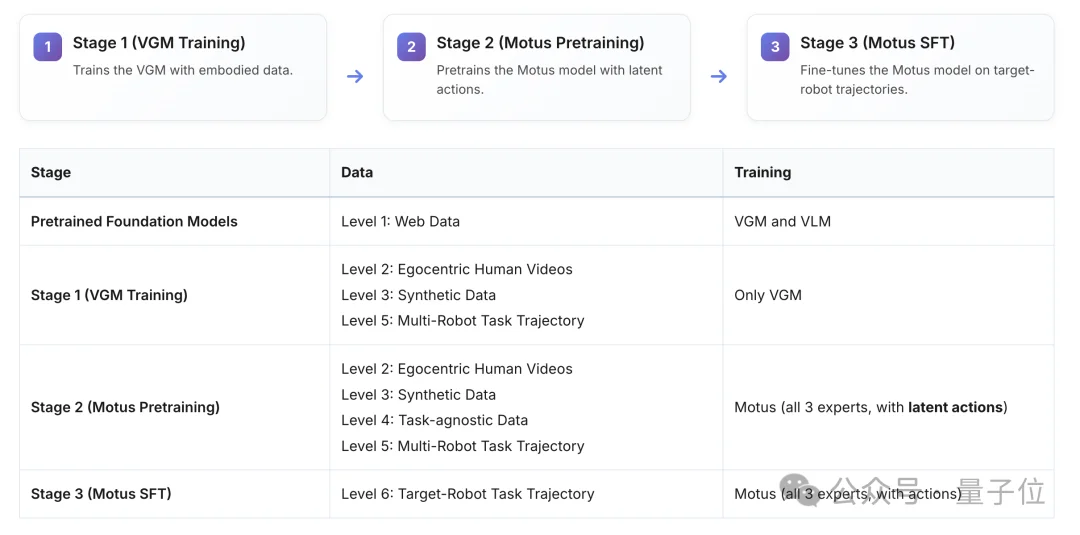
研究的实验结果表明:Scaling Law在物理世界里,真的跑通了。
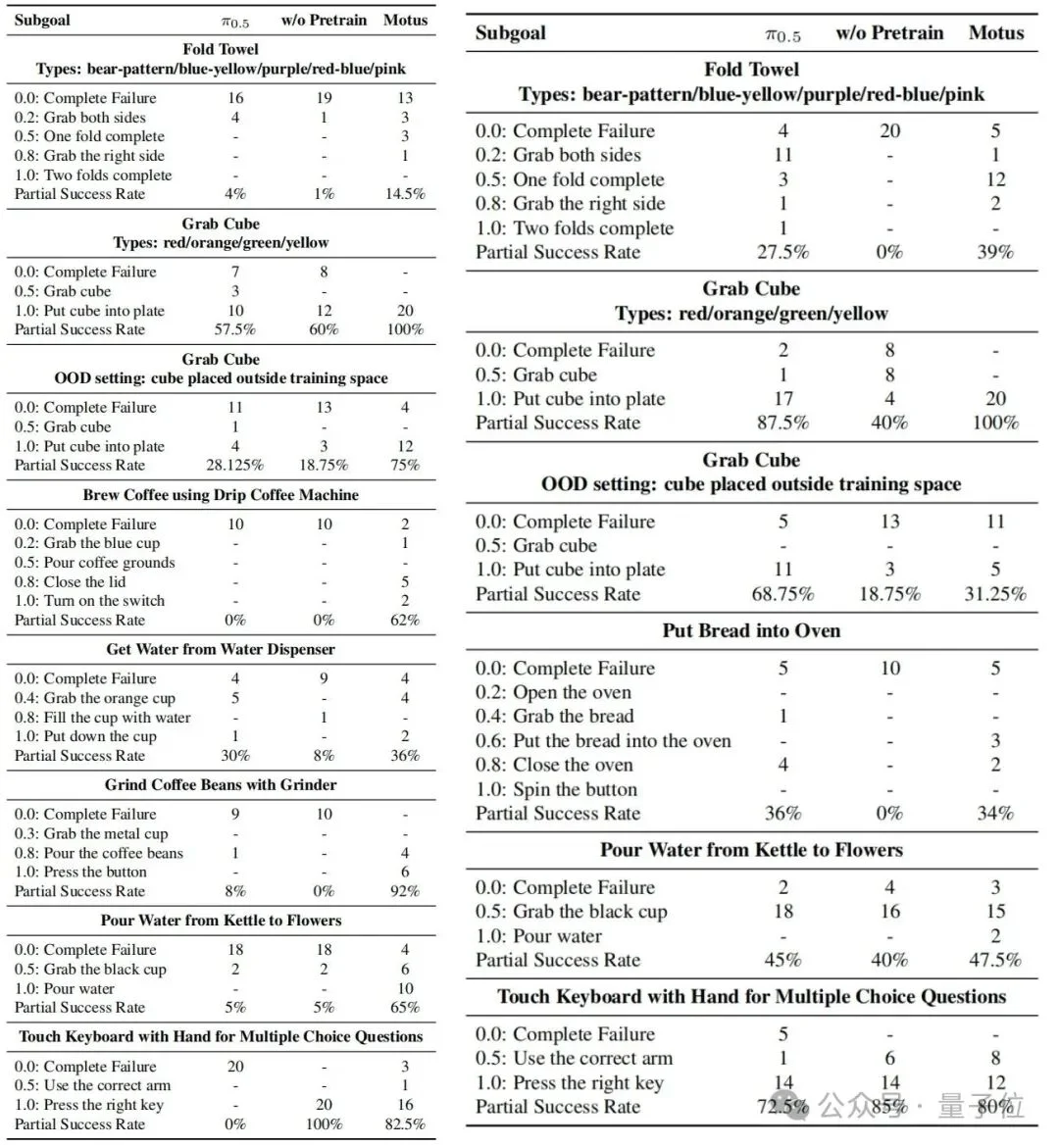
在仿真榜单RoboTwin 2.0上,在50个通用任务中,Motus的平均成功率达到了88%:
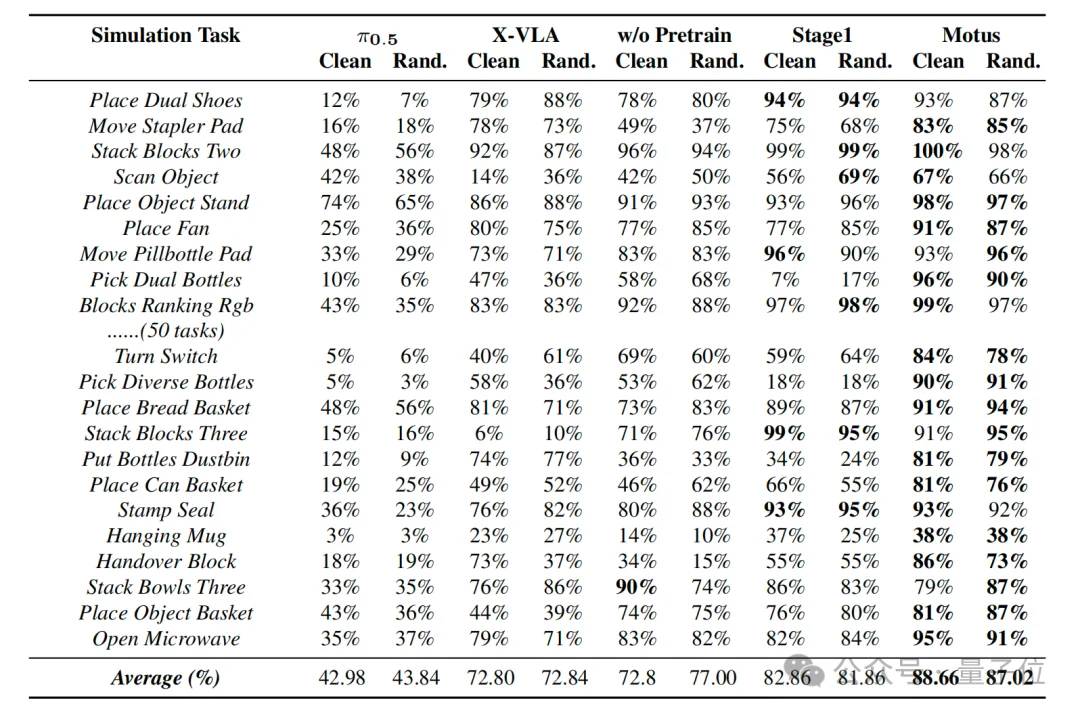
特别是在高难度的Stack Bowls Three(叠三个碗) 任务中,稍微一点误差就会导致碗塔倒塌。此前的基线模型在这个任务上的成功率不到16%,可以说是“帕金森级手抖”。
而Motus的成功率直接飙升至95%!
但比单点成绩更让人惊艳的,是下面这张Scaling Curves(扩展曲线)。
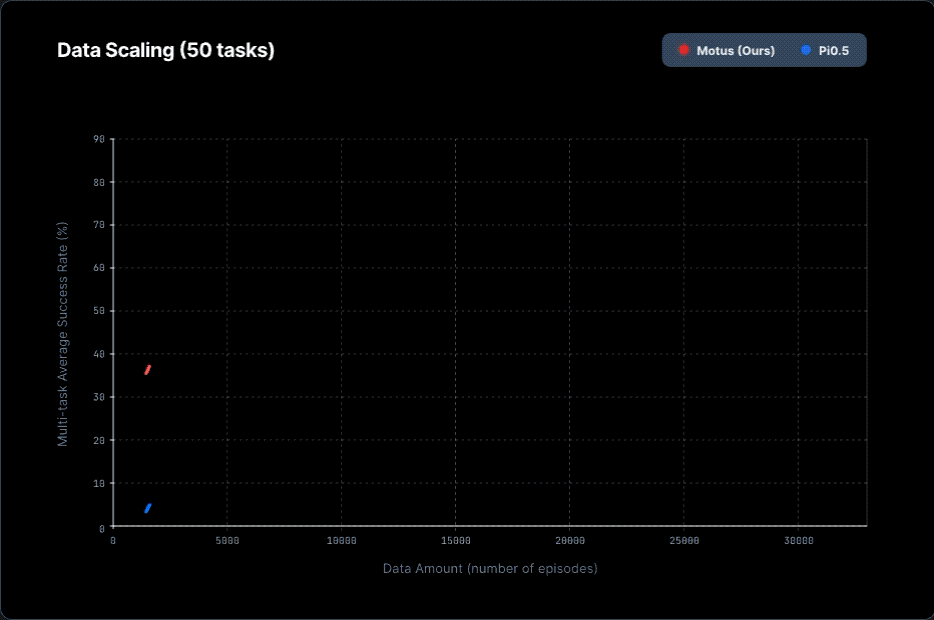
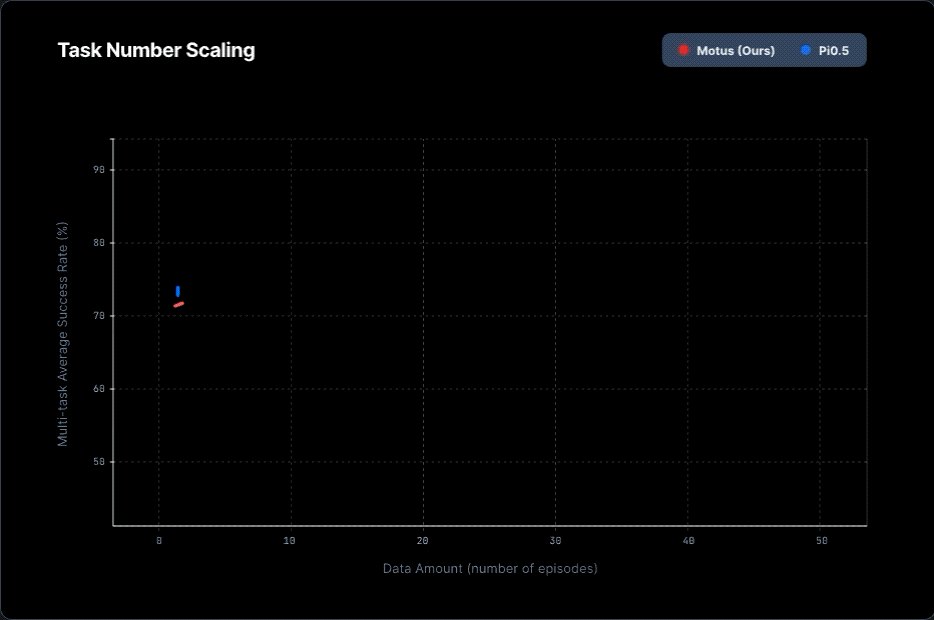
△上图为数据量Scaling,下图为任务数量Scaling。红色为Motus,蓝色为Pi-0.5
随着训练任务数量的增加(横轴),蓝色的线(Pi-0.5)呈现下降趋势。这意味着传统的模型架构在面对多任务时,容易发生过拟合,学了新的忘了旧的。
而红色的线(Motus)则是一路持续上升。
这证明了:只要模型架构足够统一、数据来源足够杂,具身智能完全可以像LLM一样,涌现出跨任务的通用泛化能力。
这也正是GPT-2当年带给NLP领域的震撼——Language Models are Unsupervised Multitask Learners。现在,Motus在具身智能领域复刻了这一奇迹。
在真机测试中,无论是AC-One还是Agilex-Aloha-2机械臂,Motus都表现出了较好的适应性。
△左:AC-One;右:Agilex-Aloha-2
数据显示,Motus的数据效率比对手提升了13.55倍。也就是说,达到同样的水平,Motus只需要别人十几分之一的数据量。
最后,让我们把目光投向这个大一统世界模型背后的团队。
Motus由生数科技联合清华大学发布,而共同领衔的一作,是两位非常年轻的清华学生:
此外,团队成员还包括谢盛昊、王泽远、黄舒翮、刘海天等,均来自清华TSAIL实验室(朱军教授课题组)。
而作为联合发布方的生数科技,这次开源Motus,也暴露了其在世界模型上的布局。
熟悉生数科技的朋友都知道,他们刚完成新一轮融资,而且一直坚持视频大模型是通往AGI的核心路径。
在生数看来,视频天然承载了真实世界的物理时空、因果逻辑与动态演变。Motus的出现,正是这一战略的重要拼图。
它标志着机器人从“机械执行”向“端到端智能”的跨越,也推动了整个行业从单点突破走向统一基座。
产学研协作在这里发挥了巨大的化学反应:生数在多模态大模型上的深厚积累,加上清华团队的顶尖算法能力,才催生出了Motus这个大一统的世界模型。
Motus于25年12月就全部开源并发布论文,早于行业2个月,而最近火热的基于视频模型的具身智能路线,生数科技与清华大学在2025年7月份就已经发表Vidar具身视频模型,领先于行业半年之久。
目前,Motus已经全量开源。
感兴趣的小伙伴可以围观一下啦~
论文地址:https://arxiv.org/abs/2512.13030
项目地址:https://motus-robotics.github.io/motus
开源仓库:https://github.com/thu-ml/Motus
模型权重:https://huggingface.co/motus-robotics
文章来自于微信公众号 “量子位”,作者: “金磊”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
