# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一直以来,神经网络的激活函数就像是 AI 引擎中的火花塞。从早期的 Sigmoid、Tanh,到后来统治业界的 ReLU,再到近年来的 GELU 和 Swish,每一次激活函数的演进都伴随着模型性能的提升。但长期以来,寻找最佳激活函数往往依赖于人类直觉或有限的搜索空间。
现在,谷歌 DeepMind 正在改变这一规则。
在一篇刚刚发布的重磅论文《Finding Generalizable Activation Functions》中,DeepMind 团队展示了他们如何利用 AlphaEvolve 在无限的 Python 函数空间中「挖掘(mining)」出了全新的激活函数。

这是一次架构搜索(NAS)的胜利,更是一次方法论的革新。DeepMind 并没有在庞大的 ImageNet 上直接搜索,而是构建了一个「微型实验室」,利用合成数据专门针对分布外泛化(OOD Generalization)能力进行优化。
结果令人震惊:机器不仅重新发现了 GELU,还挖掘出了一系列带有周期性扰动项的奇异函数,例如 GELUSine 和 GELU-Sinc-Perturbation。这些函数在算法推理任务(如 CLRS-30)上展现出了超越 ReLU 和 GELU 的卓越泛化能力,同时在标准视觉任务上保持了强大的竞争力。
下面来具体看看。
传统的神经架构搜索(NAS)往往受限于预定义的搜索空间,例如只能在「加、减、乘、除、一元函数」的组合中寻找。这种方法虽然曾发现了 Swish,但它限制了探索的边界。
DeepMind 此次的核心武器是 AlphaEvolve。这是一个由 LLM 驱动的进化编码系统。它的工作流程并非简单的参数调整,而是直接编写和修改代码。
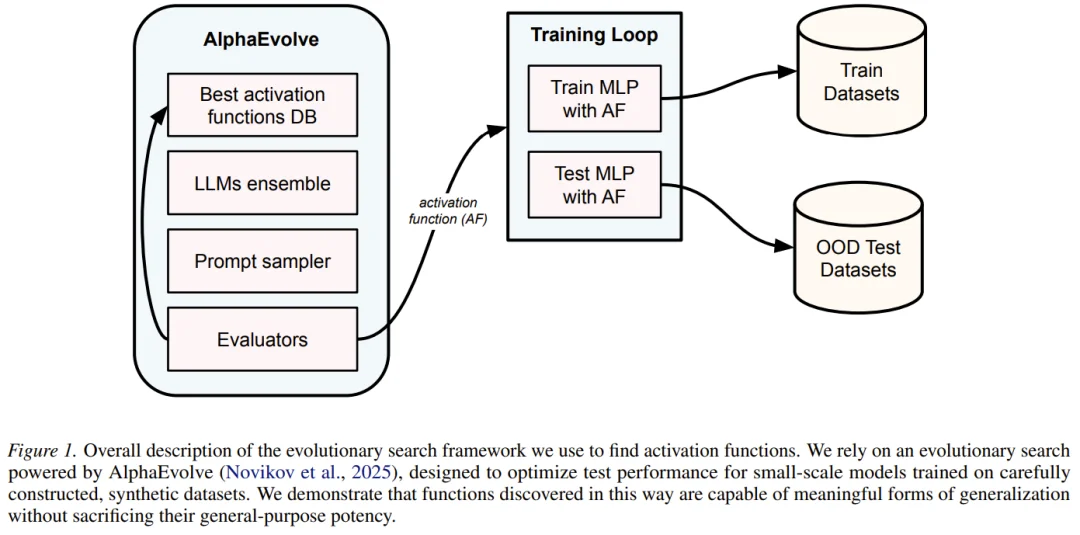
AlphaEvolve 利用 Gemini 等前沿 LLM 作为「变异算子」。这意味着搜索空间不再是离散的数学符号组合,而是所有可能的 Python 函数。只要能在一定的计算预算(FLOPs)内运行,且输入输出张量形状一致,任何 Python 代码都是潜在的激活函数。
整个系统的运作流程如下 :
1.初始化: 从标准的 ReLU 函数开始。
2.LLM 提案: LLM 根据当前最好的函数代码,编写新的函数变体。值得注意的是,LLM 还会像人类程序员一样,在代码注释中写下它设计该函数的「理论依据」。
3.微型评估: 新函数被植入到一个小型的多层感知机(MLP)中,在特定的合成数据集上进行训练。
4.适应度计算: 这里的关键在于,模型不仅要在训练集上表现好,更由于适应度函数是 分布外(OOD)测试数据 的验证损失,模型必须学会举一反三。
5.迭代: 表现最好的函数被保留到数据库中,作为下一轮进化的种子。
这种方法让 AlphaEvolve 能够利用 LLM 中蕴含的编程知识和数学直觉,倾向于生成有意义的函数,从而极大地提高了搜索效率。
微型实验室
用合成数据攻克泛化难题
为了避免在大型数据集(如 ImageNet)上进行昂贵的搜索,DeepMind 采用了一种「微型实验室」(Small-Scale Lab)策略。
他们设计了一系列简单的合成回归任务,这些任务专门用来测试模型捕捉数据结构的能力,而非死记硬背。数据集包括 :
关键的设定在于训练集和测试集的分布偏移。 例如,模型可能在 (0, 0.5) 的区间内训练,但必须在 (0.5,1) 的区间内进行测试。
研究人员发现,如果一个激活函数能在这个残酷的「微型实验室」中生存下来,它往往能捕捉到更本质的归纳偏置(Inductive Bias),从而在真实世界的复杂任务中也表现出色。
经过 AlphaEvolve 的多轮迭代,系统「挖掘」出了多个具有独特特性的激活函数。有些是对现有函数的改良,有些则不仅奇异,甚至带有某种「物理直觉」。
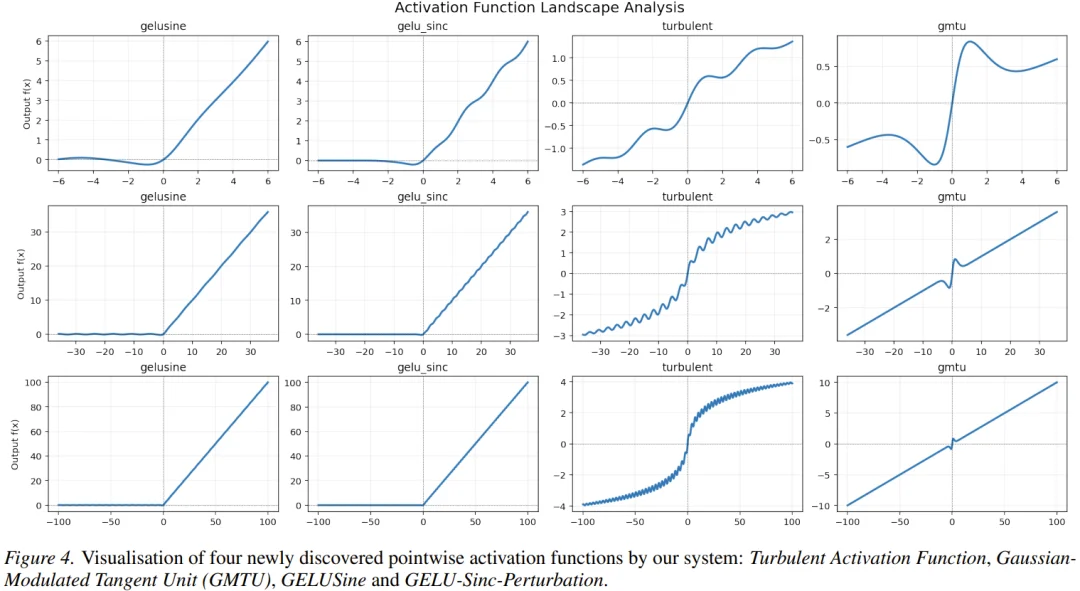
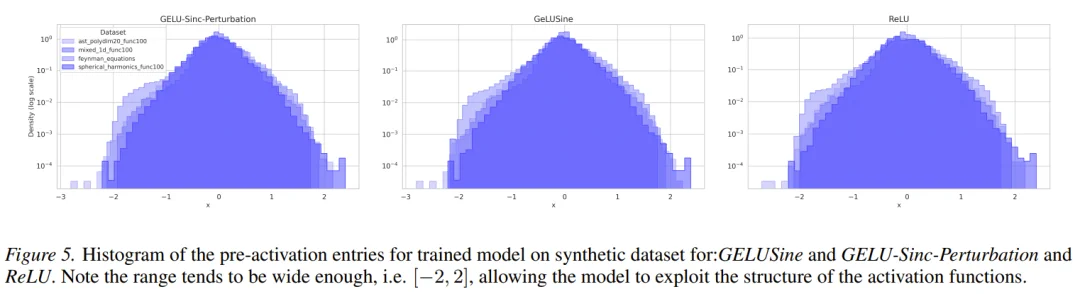
最令人兴奋的发现是,表现最好的函数往往遵循一个通用的公式:
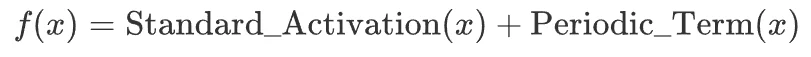
即一个标准的激活函数(如 GELU)加上一个周期性的扰动项。
• GELUSine :
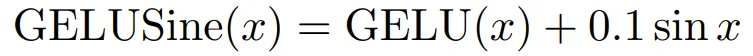
,
LLM 在生成的代码注释中解释道,这个正弦项引入了周期性的「摆动」,有助于优化过程探索损失景观,逃离局部极小值。
• GELU-Sinc-Perturbation :
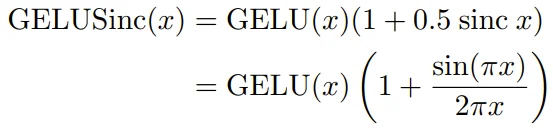
这个函数不仅保留了 GELU 的渐近行为,还通过 Sinc 函数在原点附近引入了受控的非线性复杂性。
AlphaEvolve 还发现了一种名为 GMTU (Gaussian-Modulated Tangent Unit) 的函数。它结合了 Tanh、高斯衰减和线性泄漏项,形状看起来像是一个经过调制的信号波。虽然它在合成数据上表现不错,但公式较为复杂,计算成本相对较高。
在搜索过程中,AlphaEvolve 一度发现了一种性能极高的函数,称为 Turbulent Activation。
这个函数非常「聪明」,它利用了输入张量的 Batch 统计信息(如均值和方差)来动态调整激活形状。在微型实验室的合成数据中,它的表现碾压了所有对手,测试损失极低。
然而,这种聪明被证明是一种过拟合。当迁移到 ImageNet 或 CIFAR-10 等真实任务时,Turbulent 函数的表现一落千丈。因为它过度依赖于特定数据集的 Batch 统计特征,失去了逐点激活函数的通用性。这是一个经典的「实验室高分低能」案例,也反向证明了逐点激活函数的鲁棒性。
真实世界的大考
OOD 泛化的胜利
为了验证这些在「微型实验室」里挖掘出来的函数是否真的有用,DeepMind 将它们植入到标准的 ResNet-50、VGG 和图神经网络(GCN)中,在 CIFAR-10、ImageNet、CLRS-30 和 ogbg-molhiv 数据集上进行了测试。
测试结果揭示了几个关键事实 :
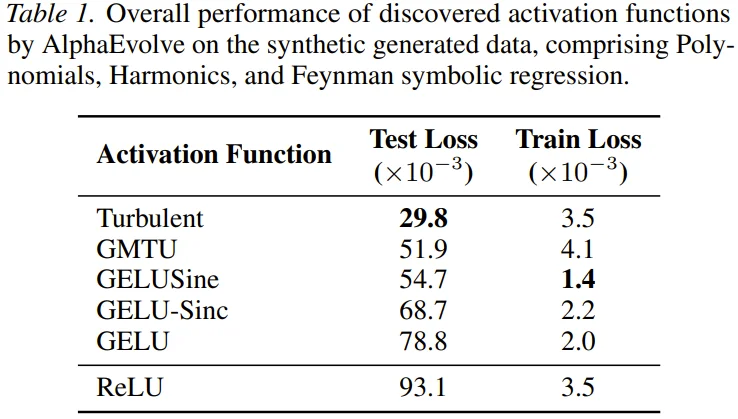
1.OOD 任务的王者: 在 CLRS-30(算法推理基准,强调用小规模数据训练并泛化到更大规模的问题)上,新发现的 GELU-Sinc-Perturbation 取得了 0.887 的高分,显著优于 ReLU (0.862) 和 GELU (0.874)。这验证了 DeepMind 的核心假设:在合成 OOD 数据上优化的函数,确实能迁移到需要强泛化能力的算法任务上。
2.视觉任务不掉队: 在 ImageNet 上,尽管这些新函数是针对小规模数据优化的,但 GELUSine 和 GELU-Sinc-Perturbation 依然达到了与 GELU 持平甚至略优的准确率(Top-1 Accuracy 约 74.5%),远超 ReLU (73.5%)。
3.周期性的魔力: 为什么在激活函数中加入 sin (x) 或 sinc (x) 这种周期项会有效?DeepMind 的研究人员认为,标准的激活函数(如 ReLU)在训练域之外往往是线性的,很难捕捉数据的复杂结构。而周期性函数允许模型在训练域内「存储」某种频率信息,并在外推时通过周期性结构「检索」这些信息。正如 LLM 在代码注释中所说,这是一种「隐式的频率分析」。
下表总结了关键函数在不同任务上的表现:
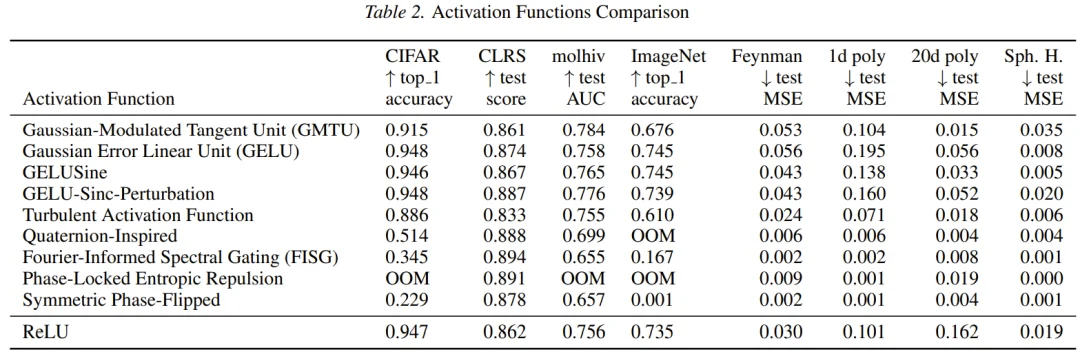
DeepMind 的这项研究不仅贡献了几个好用的激活函数,更引发了对 AI 辅助科研的深层思考。
AlphaEvolve 证明了,让 LLM 直接编写 Python 代码作为搜索空间,比预定义数学算子更加灵活和强大。LLM 自带的编程规范和逻辑能力,使得它生成的函数大多具有可读性和可执行性,甚至还能提供「设计思路」的解释。
长久以来,激活函数的设计大多为了优化梯度的流动(如 ReLU 解决梯度消失)。但这项研究表明,激活函数的形状直接影响模型的归纳偏置。通过引入周期性结构,我们实际上是在告诉神经网络:「这个世界很多规律是循环往复的,不仅仅是线性的。」
在一个追求万亿参数和由 PB 级数据训练的大模型时代,DeepMind 反其道而行之,通过仅有几百个样本的合成数据「微型实验室」,挖掘出了通用的架构组件。这表明,如果我们能精确定义「泛化」的本质(如通过 OOD 拆分),小数据依然能撬动大智慧。
不得不说,这篇论文的成果还是相当惊人的。
DeepMind 的这项工作告诉我们,在神经网络最基础的组件层面,依然存在着广阔的未至之境。
未来的 AI 模型,其每一行代码、每一个算子,或许都将由 AI 自己来书写。而对于我们要做的,可能就是像 AlphaEvolve 这样,为它们搭建一个合适的「进化实验室」。
如果你正在训练处理复杂图结构或需要强逻辑推理的模型,不妨试着将你的 nn.ReLU 替换为 nn.GELU (x) (1 + 0.5 sinc (x)),或许会有意想不到的惊喜。
文章来自于微信公众号 “机器之心”,作者: “机器之心”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
