# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
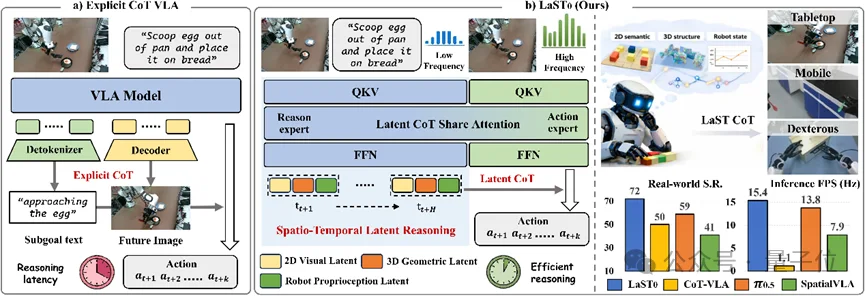
近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混合专家架构的快慢系统中,实现了隐空间时空思维链(Latent Spatio-Temporal CoT)过程,实现了对物理世界的高效推理,并且保持了高频的动作预测能力。
LaST₀提供了一种在具身大模型中引入高效隐空间推理的全新范式,在双臂、移动操纵、人形灵巧手上均实现SOTA水平,超越Pi0.5。


论文链接:
https://arxiv.org/abs/2601.05248
项目主页:
https://vla-last0.github.io/
视觉-语言-动作(VLA)模型近期展现出了强大的泛化潜力,部分前沿方法尝试在执行前显式生成语言推理链或预测未来状态。然而,这种显式推理往往会引入不可忽视的推理延迟,从而限制了机器人操控所需的控制频率;更重要的是,此类推理受限于语言空间,难以精准刻画那些“不可言说”的物理属性(物理规律、环境动态、几何关系等),形成了表示瓶颈。
为了解决这些挑战,团队提出了LaST₀框架。该框架通过隐空间时空思维链(Latent Spatio-Temporal CoT)实现了高效的“先思考后行动”,能够捕捉难以用文字表达的精细物理与动力学特征。
具体而言,其引入了一个Token高效的隐式空间来建模未来视觉动态、3D结构信息及机器人本体感知状态,并将其在时间维度上扩展,以构建时序一致的隐空间推理轨迹。
在架构设计上,LaST₀采用了基于Mixture-of-Transformers(MoT)的双系统设计,由推理专家负责低频隐空间推理,动作专家则在机器人导向的隐式表征指导下生成高频动作。
通过异构操作频率的训练,模型在部署时能够实现自适应切换。在涵盖桌面操纵、移动操纵及灵巧手操纵的10项真实任务中,LaST₀相比现有最先进的VLA方法,在成功率上分别实现了13%、14%和14%的显著提升。
通过继承视觉语言模型(VLM)的语义理解和常识推理能力,视觉-语言-动作(VLA)模型将丰富的预训练知识与机器人策略的底层控制能力相结合。这种整合为机器人智能体提供了一个统一的框架,使其能够在动态环境中理解人类指令并执行相应的动作。
近期的VLA模型进展并非简单地将观测映射为动作,而是受到了通用VLM中思维链(CoT)推理范式的启发。在这类研究中,一些方法通过显式生成语言推理轨迹或可操作性表示来增强操作的稳定性和可解释性。与此同时,其他研究试图通过融合多模态生成能力预测未来状态(如未来视觉信息、3D结构等)来捕捉环境动态。
尽管这些显式CoT VLA方法展现出了性能优势,但在机器人操作中仍面临两个根本性挑战。
一方面,显式推理通常会带来不可忽视的推理延迟。自回归生成范式引入了必然的计算开销,限制了VLA模型实现实时响应的能力。这种延迟进一步限制了VLA模型在时间维度上进行有效推理,从而损害了闭环操作所需的时序一致性。
另一方面,显式推理往往局限于语言空间,形成了难以忠实捕捉“不可言说”物理属性的表示瓶颈。相比之下,机器人智能体必须对物理世界进行推理并与之交互,这对于在动态环境中实现稳健操作至关重要。
如图1所示,与以往基于显式CoT的VLA方法不同,LaST₀在紧凑的隐式空间中进行推理,从而能够捕捉难以言传的精细物理与机器人动力学,同时支持时序连贯的建模。
具体而言,团队引入了一个Token高效的隐式CoT空间,自回归地预测二维图像、三维点云和本体感知状态的未来隐式Token。因此,该VLA模型可以隐式地建模物理动态的语义和几何结构,同时形成机器人状态的内部表示,从而捕捉机器人与其交互环境之间的关系。同时,隐式CoT空间被扩展到未来的关键帧,实现了时序一致的因果推理,从而提高了闭环机器人操作中的动作连贯性。
尽管所提出的隐式CoT非常紧凑且编码了更丰富的物理信息,但将其融入动作生成过程仍会引入额外的推理开销。因此,利用时间扩展的隐式条件,团队进一步提出了通过Mixture-of-Transformers(MoT)设计实现的双系统架构。
具体来说,两个专家被集成在单个VLA模型中:一个是慢速推理专家,负责进行低频隐空间推理以捕捉时空依赖性;另一个是快速动作专家,负责在动作空间中根据高频观测和定期更新的隐式表示生成动作。通过共享自注意力机制,LaST₀实现了隐式CoT空间与动作空间之间的长上下文交互,从而有效地协调了深思熟虑的推理与快速响应的控制。
在训练过程中,隐空间推理专家和执行专家均初始化自同一个理解-生成合一的基座模型Janus-Pro。随后,团队在多样化的机器人操作数据集上对LaST₀进行大规模预训练,确保两个专家在统一的模型中无缝交互。在下游训练期间,团队对两个专家进行联合优化,其中执行专家在异构的快慢操作比率下进行训练,使模型在部署时能够自适应地选择合适的执行频率。
在评估方面,团队系统地在10项仿真任务和10项复杂的真实世界任务(涵盖桌面单/双臂、移动以及灵巧手操作)上评估了LaST₀。结果显示,其在仿真中超过了之前的SOTA VLA方法8%,在三个真实场景中分别超过了13%、14%和14%,同时比之前的显式CoT VLA方法实现了约14倍的加速。此外,团队还在长程真实世界任务中验证了LaST₀的操作能力,例如在适应动态环境变化的同时,反复从锅中舀起鸡蛋。
研究的贡献总结如下:
1.提出了LaST₀,一个统一的VLA模型,通过隐空间时空CoT实现高效的“先思考后行动”行为,在紧凑的隐式空间中进行推理,以捕捉难以言传的精细物理与机器人动力学。
2.设计了一个时空隐式CoT空间,自回归地建模未来的语义、几何和本体感知信息,使LaST₀能够以时序连贯的方式推理物理动态。
3.引入了MoT方案协调低频隐空间推理与高频动作生成,实现了实时机器人操作。
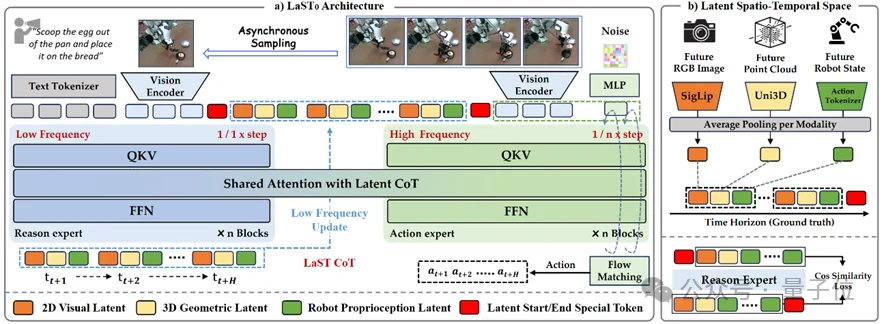
为了捕捉难以用语言表达的精细物理与机器人动力学特征,并实现针对操作任务的高效时序建模,构建了隐空间时空思维链(Latent Spatio-Temporal Chain-of-Thought, LaST CoT)。
隐式嵌入构建。为了建模环境的时空动态,团队的隐式表示编码了未来时域H内的多模态状态。如图2b)所示,对于每一个未来时间步k∈{1,…,H},团队从三个互补的模态中提取特征,以形成完整的物理表示。
未来RGB帧Iₜ₊ₖ使用冻结的SigLIP-Large编码器编码为视觉隐式表示zₖᵛ;同时,未来点云Pₜ₊ₖ由Uni3D编码器处理,生成捕捉3D空间占据情况的几何隐式表示zₖᵖ;而未来机器人状态sₜ₊ₖ则通过动作分词器转换为本体感知隐式表示zₖˢ。
这些表示共同使VLA模型能够隐式建模物理动态的语义和几何结构,同时维持对机器人状态的内部估计,从而捕捉机器人与其环境之间的交互。为了确保高推理效率,团队通过平均池化将每个模态的特征图压缩为单个代表性Token。这为每一步生成了一组紧凑的嵌入{zₖᵛ,zₖᵖ,zₖˢ}。随后,团队将这些Token按时间顺序交错排列,以保留因果物理依赖关系:
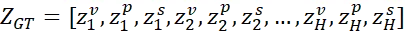
这种交错的多模态结构进一步鼓励模型学习不同模态之间随时间变化的耦合动力学。值得注意的是,时间粒度可以灵活调整:使用者可以根据任务需求,采用关键帧提取或密集采样帧。
此外,通过将高维感知输入压缩为长度为3×H的隐式序列,团队避免了解码像素级图像或长文本序列带来的高昂成本。在第3.4节中,笔者将介绍两个专家的异步频率设计,这将进一步加速动作生成。
序列结构。为了更好地组织LaSTCoT推理与动作生成,团队引入了三个特殊Token:、以及占位符Token。推理段在结构上被定义为由起始和结束Token包围的序列,中间位置预留给隐式嵌入。
在训练期间,团队使用真值隐式序列ZGT替换中间的Token。这使得模型能够通过标准的TeacherForcing学习转换动力学。而在推理期间,模型以后接一系列Token进行初始化。
随后,慢速推理专家自回归地生成隐式嵌入,按顺序填充占位符的位置,直到填满预定义的预测时域。预测时域的长度可以自适应调整,其影响将在消融实验中进一步分析。
隐式监督策略。虽然推理是以自回归方式进行的,但团队使用连续隐式回归而非离散Token似然来训练慢速推理专家。具体而言,慢速专家被训练为在给定先前观测和上下文的条件下,以“下一步预测”的方式预测一系列隐空间推理状态Ẑ。
与基于离散Token预测的传统CoT监督不同,团队的隐式目标由编码未来物理世界状态的连续高维嵌入组成。为了使预测的隐式表示与真值表示对齐,团队采用余弦相似度作为监督目标。损失函数定义为:
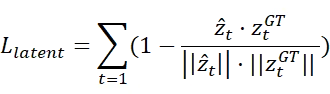
通过最大化隐式空间中的方向对齐,该目标鼓励模型以结构化且紧凑的方式预判未来的物理动态。
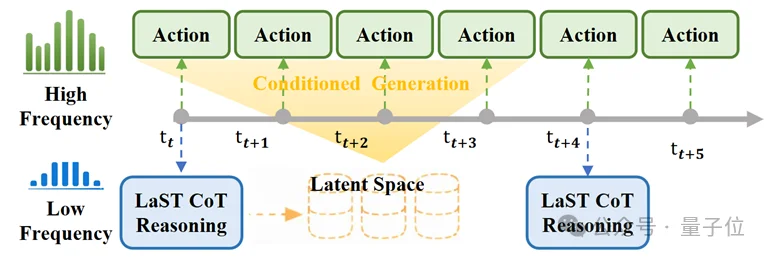
异步频率协同。为了协调LaST CoT推理与高频机器人控制,团队在慢速推理专家与快速执行专家之间引入了一种异步频率机制。
如图3所示,团队使用一组更新比率κ(例如κ∈{2,4,8})来解耦它们的运行频率。慢速专家仅在稀疏的关键帧(t mod κ=0)被激活,并执行自回归隐式CoT推理。相比之下,快速专家以原生控制频率运行,并在每个时间步保持活跃。
在连续的关键帧之间(t modκ≠0),慢速推理专家保持休眠,而快速专家则以最近一次的隐空间推理输出为条件生成动作。一个有趣的经验发现是,增加隐式表示的时间跨度(例如通过预测多个未来关键帧)可以提高动作预测的性能。
在两个专家的输入方面,慢速推理专家接收自然语言指令l和低频观测Islow,以此构建封装了未来物理动态的隐式CoT;相反,快速执行专家针对快速闭环反馈进行了优化,仅接收高频观测Ifast。关键在于,由于团队的MoT架构维护了一个统一的Token序列,快速专家可以通过共享注意力机制高效地关注语言目标和隐式CoTToken。
在表1中,LaST₀-3.3B在10项RLBench操作任务中实现了82%的平均成功率。LaST₀在混合快慢操作频率下进行训练,并在1:4的比例下进行评估。特别地,LaST₀分别以8%、17%和21%的优势超越了现有最强的方法HybridVLA-7B(74%)、π0.5-3B(65%)和CogACT-7B(61%)。
除整体平均值外,LaST₀在10项任务中的7项上均获得了最高成功率,表明其在多种操作技能上具有一致的性能提升。这些提升主要源于推理专家生成的隐空间推理表示:它通过编码未来视觉动态、3D空间结构和机器人本体感知信息的紧凑隐式状态来为执行专家提供条件,从而实现更稳定且时序连贯的动作生成。在执行效率方面(不采用动作分块方案),LaST₀的推理速度达到15.4Hz,显著快于显式CoT方法(CoT-VLA:1.1 Hz),并与π0.5(13.8 Hz)保持同等竞争力。
如图5所示,团队对比了LaST₀与无CoT变体及显式CoT方法(CoT-VLA)的注意力热图。当无CoT变体和显式CoT方法无法在被操作物体及机器人上聚合特征时,LaST₀表现出了高度集中的注意力模式,凸显了其卓越的时空理解能力。


定量与定性分析。如表2所示,LaST₀在真实世界操作任务中取得了最佳的整体性能,在Franka平台上(不包括长程任务)的平均成功率为72%(±3),大幅超越了SpatialVLA(41%,±2)、π0.5(59%,±4)和CoT-VLA(50%,±2)。
LaST₀在一系列多样化任务中持续提供强劲的性能提升,特别是那些需要精确空间推理和时序连贯控制的任务。团队进一步在长程操作任务上评估了LaST₀,该任务要求在单次滚动测试中连续完成一、二、三次成功的执行。如表2所示,与π0.5(0.47→0.20→0.07)相比,LaST₀在所有阶段均保持了显著更高的成功率(0.66→0.47→0.33),且随着步数增加,性能差距不断扩大。
这一趋势表明,LaST₀能够更好地在长时域内保持对任务进度和环境状态的一致隐式表示。除了桌面操作外,LaST₀在移动操作任务中也表现出了精确的导航和协调的双臂控制,证明了其隐空间时空推理可以泛化到桌面设置之外更大的动作空间。
对于具有更高自由度和灵巧手的类人机器人,LaST₀成功处理了复杂的关节物体操作,表明其推理和动作生成能力不受机器人形态复杂性的限制。由于深度估计效果较差,团队省略了与SpatialVLA在此类任务上的对比。

文章来自于微信公众号 “量子位”,作者: “量子位”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
