# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。
然而,随着对模型能力要求的日益严苛,DPO 的缺陷逐渐浮出水面。
究竟该如何让 DPO 学会「去伪存真」,精准识别出那些真正决定胜负的 Critical Tokens?
针对这一问题,来自中国科学院自动化研究所、字节跳动、微软亚洲研究院和北京科技大学的研究者们在被选为 ICLR 2026 Oral 的新工作中联合提出了一种全新的 TI-DPO 框架。

主流方法正面临两个核心难题,这使得模型难以实现真正精细化的语义控制:
TI-DPO 的核心思想是:既然 Token 生而不同,那就给它们「加权」。 通过引入混合加权机制和三元组损失,TI-DPO 能够精准识别并放大「关键 Token」的信号,同时抑制噪声,从而实现比传统 DPO 更准、更稳的对齐效果。它主要包含两大核心机制:
1. 混合加权机制 (Hybrid Weighting)
为了找出谁才是决定回复质量的「胜负手」,TI-DPO 设计了一套数据驱动与先验结构相结合的权重计算法:
最终的 Token 权重 ,是这两者的凸组合:
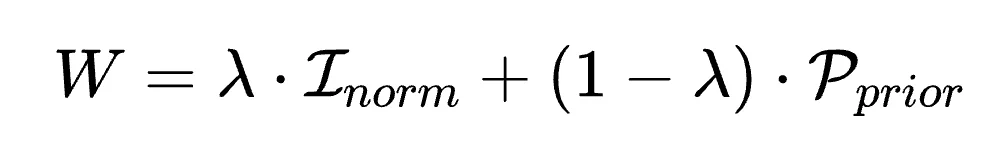
新的 Token 级 DPO 加权损失函数如下:
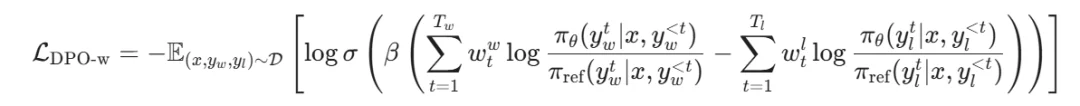
2. 三元组损失 (Triplet Loss)
TI-DPO 不再满足于非黑即白的二元对比,而是引入了度量学习中的神器 Triplet Loss。它在训练过程中构建了三个角色:


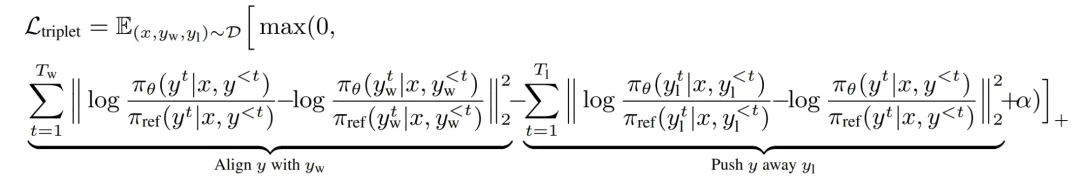
TI-DPO 损失函数:TI-DPO 的最终优化目标便是两者的加权和:
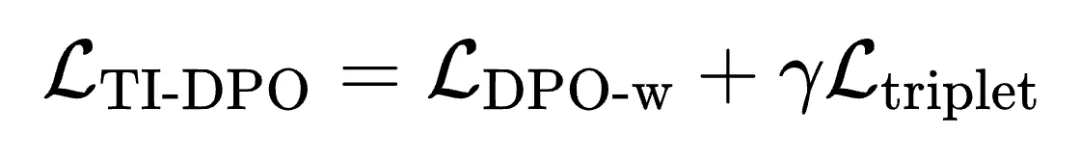
为了验证 TI-DPO 的实际战力,研究团队在 Llama-3 (8B/3B) 和 Mistral-7B 等多个主流基座模型上进行了测试,对比了包括 DPO、SimPO 以及最近大火的 GRPO 等 10+ 种对齐算法。
1. 综合能力评估
如图 1,在 Llama-3.1-8B-Instruct 基座上,TI-DPO 的综合平均分达到 62.3,超过 GRPO (62.1) 和 DPO (60.8) 。
2. 细分领域表现优秀
在 IFEval(指令遵循)、TruthfulQA(真实性)和 HumanEval(代码生成) 这三大最考验细节把握的任务上,TI-DPO 的表现大幅超越了 DPO、SimPO 以及 GRPO。
3. 消融实验:核心组件缺一不可
Table 2 的消融实验结果表明,TI-DPO 的所有核心组件(包括混合加权机制、高斯先验和三元组损失)对于模型性能都至关重要,移除任意模块均会导致在通用能力、数学推理及代码生成等各项指标上的显著下降。
4. 案例展示:一眼看懂「关键 Token」
为了验证 TI-DPO 是否真的学会了「抓重点」,作者展示了一个医疗咨询案例(「头痛该怎么办?」)的权重可视化热力图。

这种有力地证明 TI-DPO 不是在死记硬背,而是真的读懂了人类价值观。
TI-DPO 的提出,为大模型对齐从粗放的序列级优化向更精细的 Token 级控制转变提供了一个有力的尝试。它不再满足于笼统地判断回答的「好坏」,而是试图厘清每一个 Token 在价值对齐中的真实贡献。
实验结果表明,TI-DPO 在指令遵循、真实性与代码生成等任务上,相比 GRPO 等基线取得了稳定的性能提升,验证了提升数据利用的「颗粒度」是增强模型能力的有效路径。
TI-DPO 以其在去噪和细节控制上的特性,为后续的 RLHF 研究提供了一个值得关注的新方向。我们期待看到更多围绕「细粒度价值对齐」的探索,推动大模型向着更精准、更可控的方向进化。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
