# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天上午,有幸受邀参加了一场具身顶流华山论剑活动。
成立一周年的原力灵机举办了首次技术开放日,在不到三个小时的时间里,这家创立刚刚一年的公司,连续发布了多个炸弹级的成果,我觉得是 2026 开年最硬核的具身产品发布会。

之前做机器人,大家的做法是拿 GPT-4、Gemini 这些见过全世界的大模型,在后面接一个机械臂的控制模块,让它学会抓东西、放东西。这叫向互联网借智。
GPT、Gemini 是学习了全互联网上的数据才涌现了认知智能,所以 VLM 视觉语言大模型是互联网数据驱动的,只看到了互联网上面的数据和场景。
但是,实际上的现实世界是一个物理世界,机器人除了要具备知识,还要了解空间、了解距离、了解“拿”和“放”的区别,这些仅靠互联网解决不了。
所以,原力灵机的做法是从物理世界中求真理,并且提出一个新的概念—具身原生。

区别于互联网原生,具身原生是从第一行代码就为机器人而写,从一开始就教模型理解物理世界,而非改造现有大模型。
什么意思?
他们从第一行代码开始,就让模型在真实环境里摸爬滚打:什么叫摩擦力、碰撞会有多大反作用力、怎么拿稳一个杯子不会摔——这些“身体记忆”从训练第一天就刻进模型里。
今天 Open Day 上,他们便发布了第一个代表具身原生的重磅成果—DM0 模型。

这是一个只有 2.4B 参数的具身原生大模型,在 RoboChallenge 真机评测平台上,拿下了单任务、多任务双料第一,超越了所有 7B、13B 参数的竞争对手。
在大模型领域,参数越大能力越强几乎是行业共识,但 DM0 用不到 1/3 的参数,在真机测试中反而跑赢了。
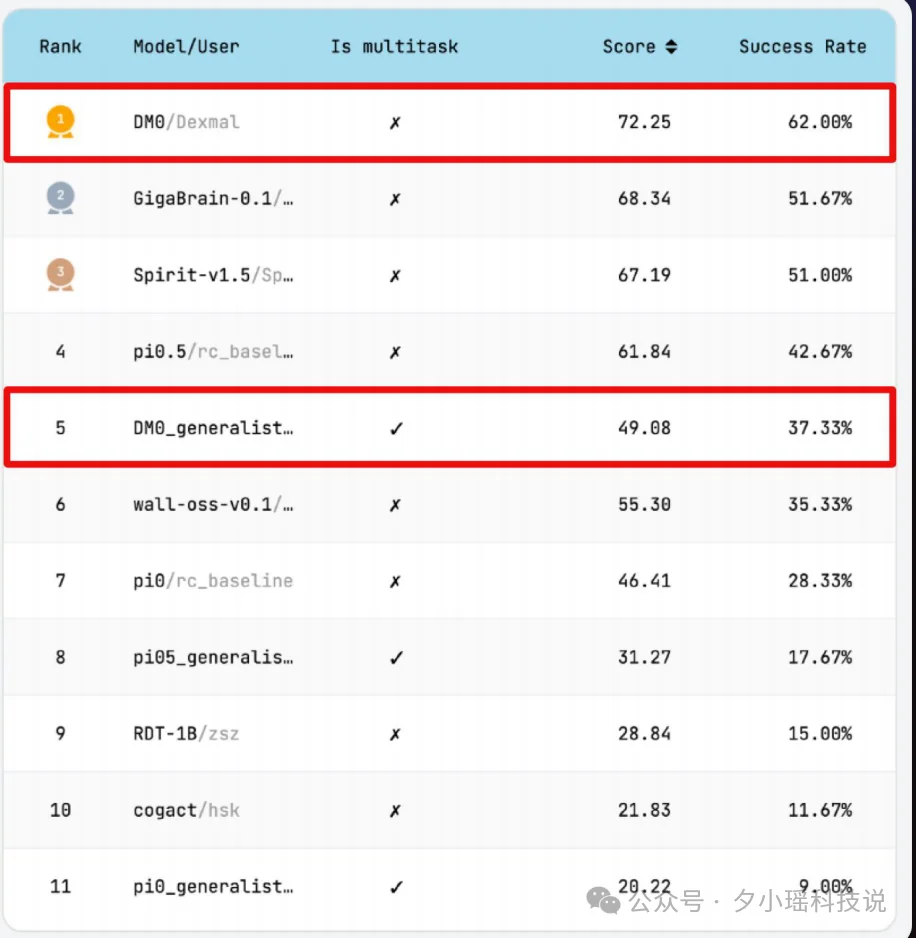
不是下载个现成的 VLM 微调一下的路线,DM0 是从零开始设计、训练。
为什么 2.4B 能吊打 7B?
首先,具身智能的训练本身一定要通过多源数据混合训练这样的模式来进行学习。
DM0 把数据范围扩展到人类生活全场景,包括三类数据:

打个比方,你从家里做完家务,出门开车来到公司,来到公司之后浏览网页、工作、刷手机,这些都是具身原生训练的数据。
其次,DM0 没有限定在单一硬件和特定场景里,实现多任务跨机型预训练。
在预训练阶段系统混合了抓取、导航、全身控制三类核心任务,并覆盖 UR、Franka、ARX、UMI、Aloha、R1-Lite、Realman、DOS-W1 等 8 种差异显著的机型。
目标是让模型学习操作的通用逻辑和物理规律,而不是记住某个特定机器人的电机参数。
再者,DM0 加入了空间推理思维链。
思维链对于大模型的意义无需多言,对于具身智能,叫做空间思维链。
比如,我们发起一个模糊的指令,对桌面商品扫码计价,DM0 会先进行子任务预测与规划,再完成物体识别与精确定位,随后生成 2D 轨迹并映射为可执行的 3D 动作。这条空间推理思维链,把任务理解、运动规划与动作执行串成高精度操作的闭环。
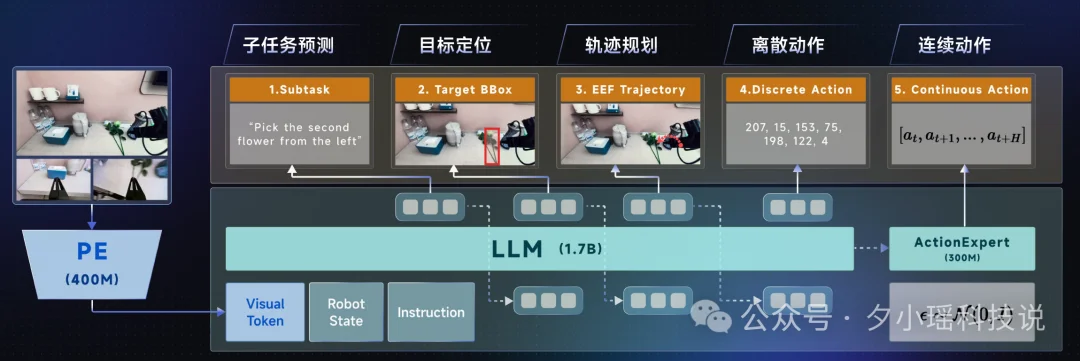
不仅是 Planning,还有真机强化学习。仅靠 Planning 还不足以应对现实世界中的摩擦、打滑与突发情况。
DM0 大模型与强化学习结合后,模型可以在真机中不断试错,在失败中学习成功。通过真实操作反馈,模型逐步学会如何稳健应对各种扰动。
此外,还有几个关键的设计。
它原生支持 728×728 高分辨率输入,并能同时处理三个视角的摄像头画面,实现毫米级的精细动作感知—而目前业内普遍只做到 224~384。
更高的分辨率意味着机器人能看得更清晰。比如拧螺丝这类精细操作,1~2 个像素的偏差就可能导致抓取失败,高分辨率直接解决了这个问题。
即便分辨率大幅提升,DM0 依然能保持约 60ms 的低延迟推理,并可在消费级显卡(如 RTX 5090)上完成训练与部署。
结果就是,DM0 成了一个超高智能密度的模型。
智能密度是指模型在真实任务上的表现 / 模型参数量。同样的任务完成能力,参数越少越牛。
技术报告给大家准备好了,感兴趣的家人们可以看下:
技术报告:https://dexmal.com/DM0_Tech_Report.pdf
光有模型还不够,原力灵机还发布了 Dexbotic 2.0 开发框架。这是一个让所有开发者都能快速使用的开源具身原生框架。
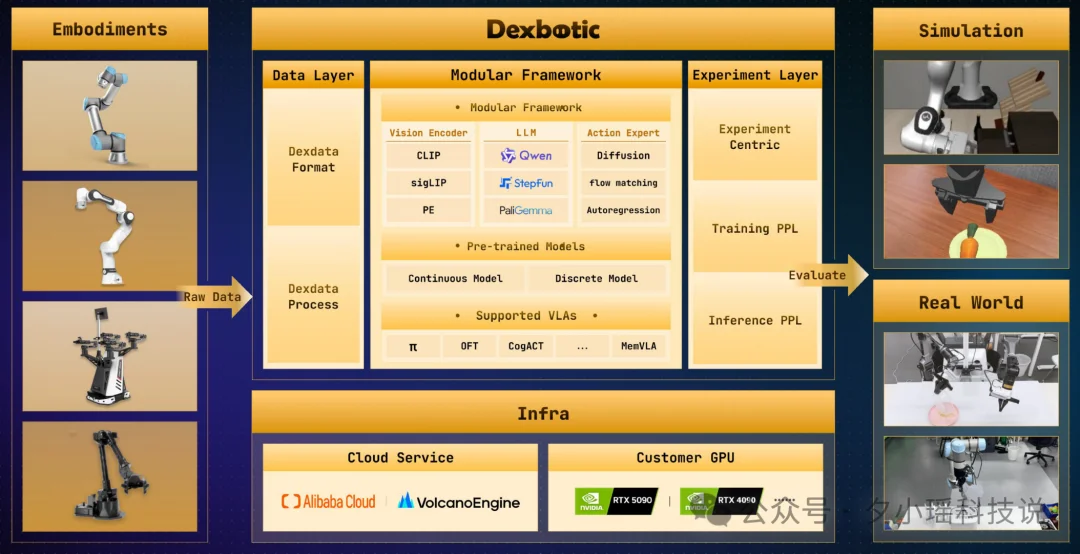
这个框架最大的特点是模块化解耦:Vision Encoder、LLM、Action Expert 三大模块可以像乐高一样自由组合。
传送门:https://huggingface.co/collections/Dexmal/dexbotic
比如,你今天用的是 SigLIP 做视觉,明天 OpenAI 出了个更好的视觉模型,直接换上去,不用重写整套代码。
每个模块都可以独立升级、替换,方便开发者快速试验新模型,搭建自己的具身应用。
总结一下 Dexbotic 2.0 的其他几大特点:
Dexbotic 2.0 全面适配 Pi0.5、OpenVLA-OFT 等先进 VLA 算法框架,并原生支持 DMO 系列创新模型,提供业界最丰富的算法生态。
打造了"数据—训练—评测—硬件"的高效闭环,规范化、流程化算法迭代
这是非常关键的一点。Dexbotic 负责 VLA 预训练与 SFT,清华、无问芯穹 RLinf 负责大规模 RL 后训练。加起来就是具身智能版的 SFT+RLHF。
发布仅 3 个月,Dexbotic 已经服务了数十家机构,包括清华、北大、普林斯顿、帝国理工、腾讯、北京具身智能机器人创新中心等,超过千位研发者在使用。
有了模型、有了框架,最后一步是落地。
具身智能的“死亡之谷”不是技术问题,是工程问题、是成本问题、是规模化复制的问题。
这句话不只适用于具身智能,还适用于任何行业领域。
原力灵机提出了一套 DFOL(Distributed Field Online Learning,具身原生应用量产工作流)。目的是给客户交付一套能自己学习、自己进化、越用越聪明的系统。

传统的具身机器人自动化是一次性交付,装好什么样,遇到新情况(比如零件位置偏了一点),就只能停机等工程师来调参、改程序。
DFOL 的关键创新在于数据回流机制:现场产生的训练片段(episode)与负样本块(negative chunk)实时上传云端,构建起一个"云端训练 → 现场执行 → 数据回流 → 模型优化"的完整数据飞轮,使人类经验与算法能力不断交织、相互赋能。
飞轮一旦转起来,系统就不会“装上即封存”,而是越用越聪明、越用越顺手。不是卖一个固定能力的机器人,而是卖一套越用越聪明的系统。
整场活动下来,硬核的内容非常多,2026 年 2 月 10 日,对中国具身智能行业来说,或许会成为一个值得记录的日期。
一家中国具身智能的公司,成立一周年,完整地展示了从理念(具身原生)、到模型(DM0)、到框架(Dexbotic 2.0)、到落地方案(DFOL)。
更重要的是,愿意把核心技术开源出来让整个行业一起验证。
在发布会上,原力灵机还宣布—已与清华大学、无问芯穹达成战略合作,三方将共建更加开放、完整的开发生态,致力于打造具身智能的"PyTorch"级基础设施。
原力灵机,未来可期。
文章来自于“夕小瑶科技说”,作者 “夕小瑶编辑部”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
