# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。
然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
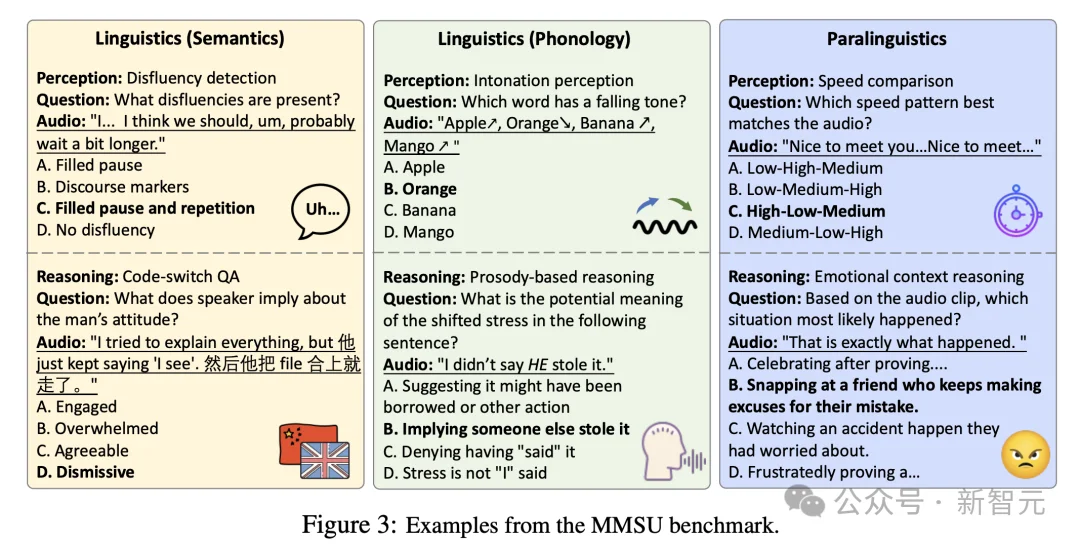
在自然口语交流中,理解并不等同于文本转写。语言意义的建构,既依赖「说了什么」(what was said),也依赖「怎么说」(how it was said),更依赖说话人在特定语境下「真正想表达什么」(what was truly meant)。语调、重音、停顿、语速变化、情绪表达与语用等现象,往往决定了说话人的真实含义。
在这一背景下,研究团队提出了MMSU(Massive Multi-task Spoken Language Understanding and Reasoning Benchmark),一个覆盖47个子任务、5,000道选择题的综合性语音理解评测基准,旨在从语言学结构出发,系统刻画SpeechLLMs在多层语言现象下的感知与推理能力,并为语音理解能力建立可分析、可诊断、可比较的统一坐标体系。

论文链接:https://arxiv.org/pdf/2506.04779
数据链接:https://huggingface.co/datasets/ddwang2000/MMSU
项目主页:https://github.com/dingdongwang/MMSU
与其问「模型准确率多少」,不如先问:我们是否测对了能力?
MMSU指出,当前语音评测存在三类关键缺口:
这些问题并非独立存在,而是共同导致评测结果与真实理解能力之间的结构性偏差。
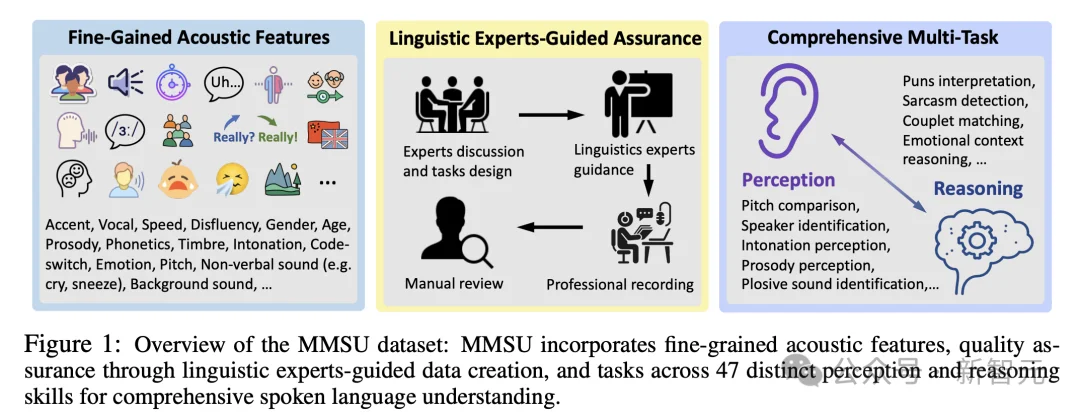
在数据构建阶段,MMSU 由语言学专家与标注人员参与设计与审核。所有题目均经过多轮严格筛选与一致性校验,确保难度设置合理、整体评测质量可靠。不同于仅通过音频收集构建数据的benchmark,MMSU 结合了专业录音,使关键语音现象(如重音转移、语调变化、停顿结构等)得到清晰呈现与可控对比,从而提升评测的可靠性。
MMSU 的核心优势体现在三个方面:
第一,在口语声学现象覆盖上,MMSU 系统纳入重音转移、语调变化、停顿结构、拉长音、不流畅表达、反讽、非语言声音等多类真实交流现象,覆盖范围在现有语音理解评测中最为全面。
第二,数据构建中采用大量真实音频样本,并结合专业录音,确保语音表达自然且具有可评估性。
第三,任务体系基于语言学理论框架进行原创性任务设计,将声学线索系统融入真实人际交流语境,形成面向真实交流场景的综合考核机制。
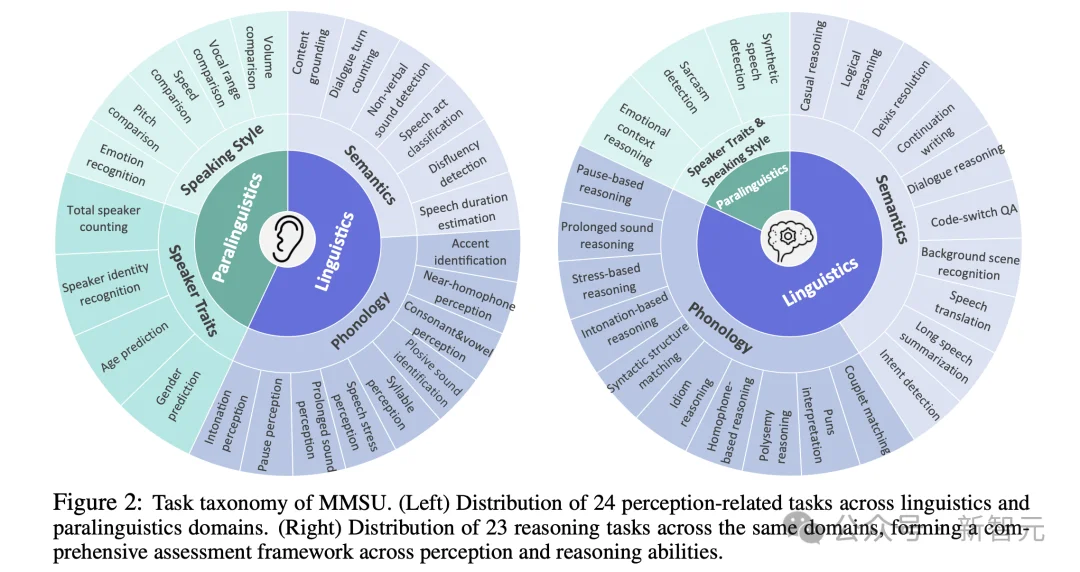
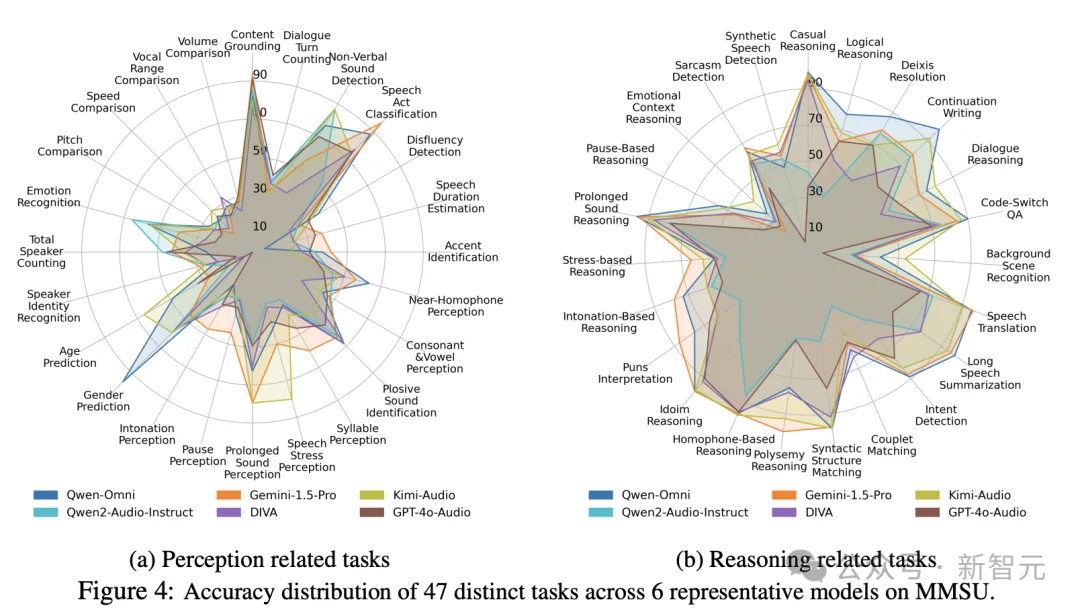
MMSU包含5000道选择题,47个子任务,其中24个感知任务,23个推理任务。任务覆盖范围从底层声学感知到高阶语用推断。
MMSU 将语音理解拆解为三个层级,形成一个结构化能力框架。
第一层:Perception vs Reasoning
感知Perception:聚焦基础声学与语音特征识别,不依赖复杂推理。
推理Reasoning:在感知基础上整合语义与语境信息,完成多步推断。
第二层:Linguistics vs Paralinguistics
语言学Linguistics:涉及语言系统本身的结构与意义,包括语义、句法、音系结构与修辞现象。这里关注的是语言单位如何组织,以及它们如何编码意义。
副语言学Paralinguistics:关注语言之外但影响理解的声学与表达特征,例如音高、音量、语速、情绪表达、停顿模式、非语言声音等。这些线索并不改变词汇内容,却往往改变话语意图与语用效果。
第三层:理论分支
在前两层划分基础上,MMSU 进一步依据语言学理论进行系统展开。在语言维度上,任务细分为语义Semantics与音系Phonology两个方向:语义关注意义理解与语境推断,音系关注语调、韵律与音位差异等声音结构。
在副语言维度上,任务区分为说话人特征Speaker Traits与表达风格Speaking Style,前者涉及音色与身份属性,后者涵盖音高、语速、情绪等动态线索。具体而言,评测涵盖双关语推理、语调推理、重音推理、辅音与元音感知、爆破音识别,讽刺检测、语速比较、音色识别,情绪语境推断等多类任务,系统覆盖真实口语交流中的关键能力。
通过这一层展开,MMSU在理论层面将语音理解拆解为语义内容、声音结构、说话人属性与表达风格四个核心分支,使「说了什么」「怎么说」以及「真正想表达什么」能够在统一框架中被精细刻画与系统评估。
实验结果
模型离「真正听懂」还有多远?
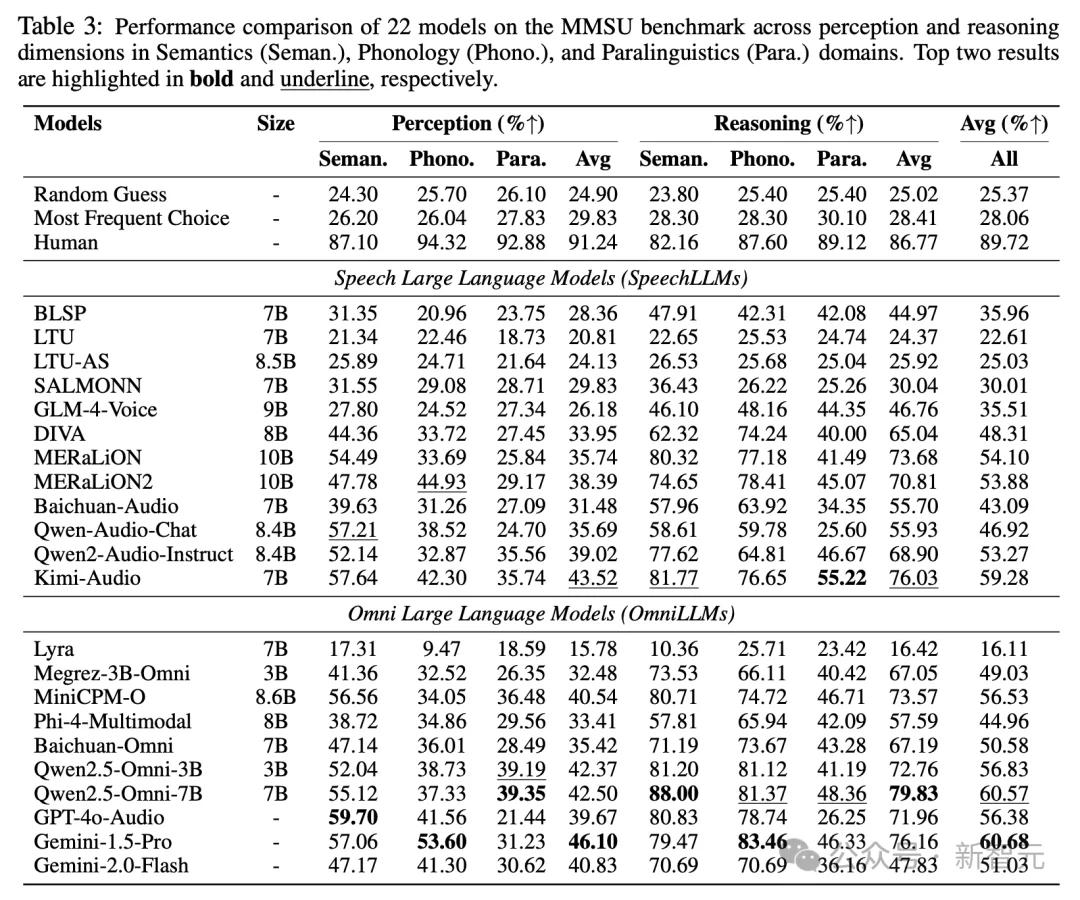
研究团队对22个先进SpeechLLMs与OmniLLMs进行了系统评测。人类参考水平为89.72%,最佳模型(Gemini-1.5-Pro)为60.68%,差距接近30个百分点。
一个值得关注的反直觉现象随之显现:在人类表现中,推理任务通常更具挑战;而在模型表现中,基础感知反而成为瓶颈,尤其是在音系相关能力上,模型存在系统性短板。
这意味着,许多所谓的「推理错误」可能并非源于模型缺乏逻辑能力,而是在输入阶段未能准确捕捉关键声学线索,换言之,模型的「思考能力」或许被高估,而「听清能力」却被低估。
结语
从「能听」到「听懂」
语音理解的难点,从来不在于识别字词,而在于理解表达结构。
意义并非仅由语义内容决定,还由声音形式与表达方式共同塑造。语调、重音、停顿、语速与情绪变化,往往决定了真实意图。忽略这些声学线索,模型就无法完成真正的语用推断。
实验结果进一步表明,推理能力的上限取决于感知能力的下限。当模型在音系与细粒度声学特征上存在系统性短板时,再强的语言建模能力也难以弥补输入层的缺失。
因此,语音理解并不是单一语义问题,而是一个多层结构问题。它要求模型同时解析语言内容、声音组织与表达风格,并在此基础上整合语境完成推断。
如果缺乏系统性的能力坐标,我们无法判断模型究竟听清了什么、理解了什么,又推理到了何种程度。MMSU 所尝试构建的,正是这样一套结构化标尺。在多模态模型走向真实交互的过程中,语音理解仍是一个尚未被充分攻克的核心问题。
参考资料:
https://arxiv.org/abs/2506.04779
文章来自于微信公众号 “新智元”,作者: “新智元”


【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
