# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
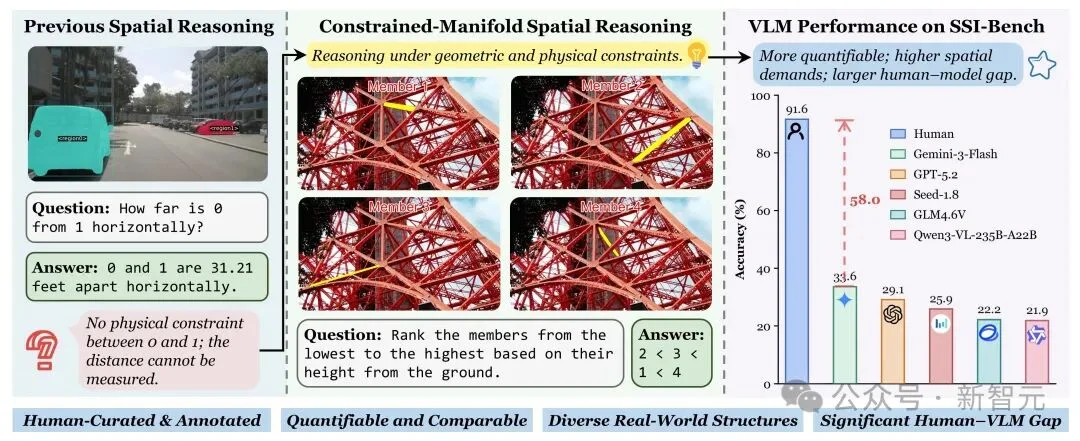
如果你把一个在空间理解榜单上刷分很高的多模态大模型,直接丢进真实世界,它很可能会在看起来很简单的问题上翻车。
不是因为它不会「看」,而是因为它从来没有被迫真正尊重三维结构的可行性——它可以靠2D相关性、外观先验、数据集套路,走捷径拿分。
而现实世界里,很多空间问题的本质恰恰相反:能怎么摆、怎么连、怎么受力,不是随意的;可行解往往只存在于一个被几何、拓扑、物理强约束「压扁」的空间里。
为此,清华大学的研究团队推出SSI-Bench,从AI与结构工程的交叉视角出发,为空间智能评估提供了一种新的场景化思路——将评测置于复杂三维结构的约束流形中,系统检验多模态大模型的空间智能表现。

项目主页:https://ssi-bench.github.io/
Arxiv论文:https://arxiv.org/abs/2602.07864
Hugging Face数据集:https://huggingface.co/datasets/cyang203912/SSI-Bench
Github代码库:https://github.com/ccyydd/SSI-Bench
论文将这种能力明确界定为Constrained-Manifold Spatial Reasoning(CMSR,约束流形空间推理):
在此类任务中,潜在三维状态并非可被任意「臆测」,而是受到显式约束的限定,仅能落在一个可行解集合内——既需要满足等式约束(如几何一致性、连接关系等),也需要满足不等式约束(如非相交条件、支撑条件与物理可行性等)。
更重要的是,强约束会显著收缩可行三维配置空间,使「高度、距离、最短路径」等空间关系在不同合理解释下更具稳定性,从而使评测结果具备更好的可量化性与可比性。
SSI-Bench正是在这一背景下提出:它不再将模型置于约束较弱、可自由组合的日常场景中,而是面向复杂真实工程结构构建评测环境,要求模型形成约束一致的三维结构假设,并在此基础上完成空间推理。
聚焦复杂三维结构
纯人工硬核打造
任务形式:用排序题「逼出」真3D
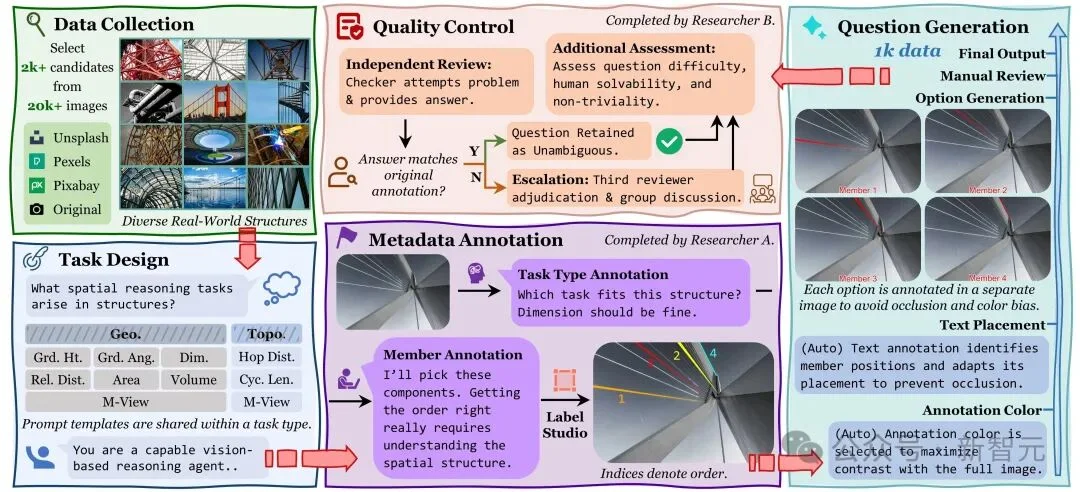
SSI-Bench不再让模型做选择题,而是统一成排序任务:每题给出3或4个候选「构件/构件组」,要求在指定几何/拓扑准则下输出正确的全排列顺序。
覆盖能力:几何+拓扑+多视角一致性
全基准共1,000道排序题,任务分两大类:
并额外引入多视角题目:以两张图配合,一张提供参考构件,一张给出待比较目标,重点考察跨视角构件对应与整体结构一致性。

构建过程:十位研究者耗费400+小时纯人工打磨
为了保证数据集的质量与多样性,同时也由于缺乏真实结构构件的标注数据,SSI-Bench的构建流程非常「硬核」——10位研究者投入超过400小时,从大量真实结构图片中进行人工筛选与题目设计:
模型仍在起跑线
人类领先近六成
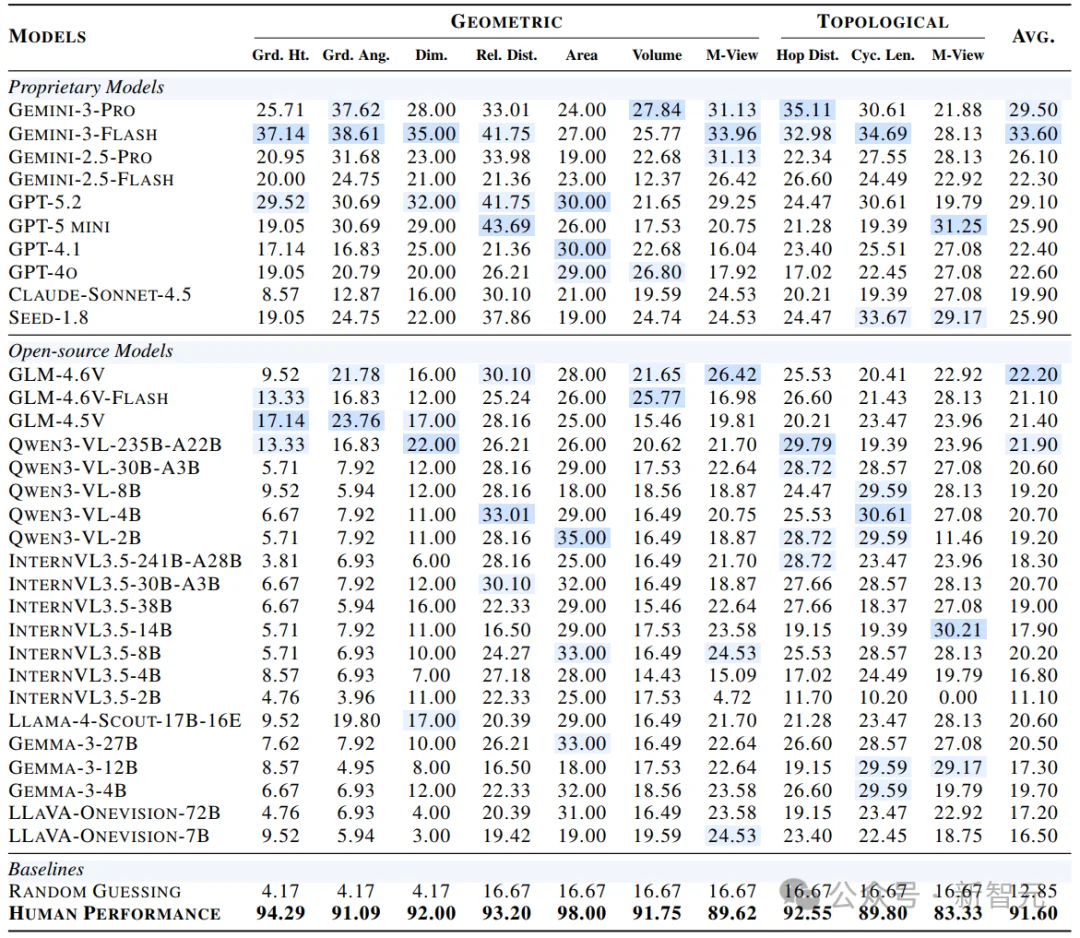
SSI-Bench系统评测了31个主流VLM,结论非常直接:人类几乎「碾压式领先」。
人类平均91.6%,最强闭源33.6%(Gemini-3-Flash),最强开源22.2%(GLM-4.6V),随机猜测基线12.85%
也就是说,哪怕拿到当下最强大模型,人类仍然领先58个百分点(91.6 − 33.6)。
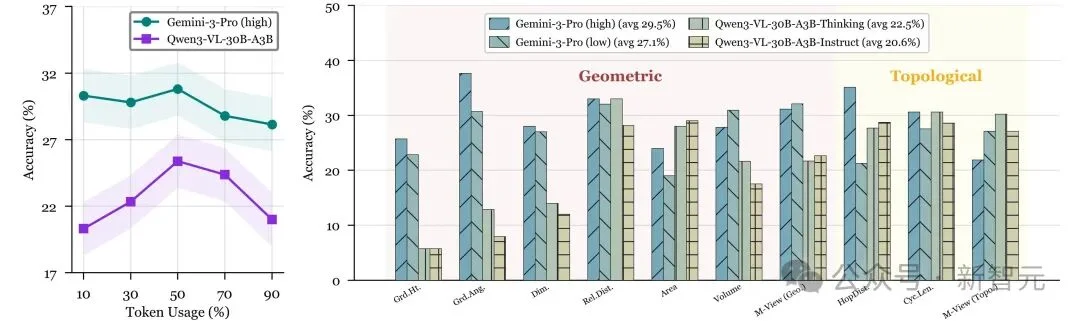
更为关键的是,即使鼓励模型生成更长的推理过程,整体提升也多停留在边际层面,难以触及问题的核心瓶颈。并且在部分高度依赖全局三维一致性的任务(如Multi-View、Volume)中,过度推理反而可能在错误的结构假设上持续累积偏差,使结果进一步偏离正确答案。
从结果到机制
关键瓶颈在哪里?
论文对代表模型做了人工复盘,归纳出四类高频错误:
这也解释了SSI-Bench的「硬核」并不在于题目刻意刁钻,而在于它迫使模型直面并补齐两项关键短板:三维结构构型识别与约束一致的空间推理。

结语
SSI-Bench的价值,并不是再造一个「更难的VQA」,而是把空间智能评估拉回一个更接近现实的坐标系:
当场景是复杂真实结构、当可行解被强约束收缩、当2D捷径不再可靠——模型是否还能稳定地构建约束一致的3D结构假设并完成推理?
从目前结果看,答案仍然很残酷:模型还在起跑线,人类已在终点线附近。
但也正因如此,SSI-Bench给出了一个非常明确的研究方向:
让空间智能体从「会看图说话」,走向「会在结构里思考」。
参考资料:
https://ssi-bench.github.io/
Yang, C. (杨晨), Lin, G., He, Y., Chen, P., Liu, G., Mo, Y., Xu, Z., Wang, L., Zhang, G., Zhang, Z., Zeng, S., Wang, C. (王琛), & Fan, J. (樊健生) (2026). Thinking in structures: Evaluating spatial intelligence through reasoning on constrained manifolds. arXiv. https://arxiv.org/abs/2602.07864.
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
