# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
 各位对Agent Skill早已轻车熟路。不可否认,在Claude code、Openclaw的加持下,这套框架效果极佳。但工业界的痛点在于:它几乎沦为了超大型闭源API的专属玩具。当您的项目面临金融风控、军工级数据隔离时,持续调取公共API的方案会在合规与预算的双重审查下被直接毙掉。面对这种死局, 修猫今天要为您介绍一篇论文。
各位对Agent Skill早已轻车熟路。不可否认,在Claude code、Openclaw的加持下,这套框架效果极佳。但工业界的痛点在于:它几乎沦为了超大型闭源API的专属玩具。当您的项目面临金融风控、军工级数据隔离时,持续调取公共API的方案会在合规与预算的双重审查下被直接毙掉。面对这种死局, 修猫今天要为您介绍一篇论文。


来自卢森堡大学、普林斯顿大学的研究者抛出了一个核心拷问:这套原本为巨型大模型设计的Agent Skills框架,能否下放给在本地跑的开源小型语言模型(SLMs),并为它们带来同等的性能跃升?为了把黑盒的“直觉”变成可量化的工程指标,研究者不仅在底层用严密的数学模型重构了Agent Skills,更直接拉来从270M到80B的全谱系开源模型,在最真实的工业数据集上进行了一场抗压极限测试。读完本文,您将清楚地知道在有限的硬件预算下,到底该选用什么规模的模型、怎么配路由,才能拼装出一套能打的Local Agent。

定义POMDP为:
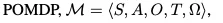

为了在真实的工业限制下测试SLMs(Small Language Models),研究者构建了严密的实验环境,避免引入外部组件(如复杂的工具调用代码)对结果造成混淆。实
、技能执行 验主要考察两个核心能力:选择合适技能的“路由(Routing)”能力,以及获取技能后的执行正确率。所有方法均使用LangChain智能体框架实现,使用vLLM作为底层的大模型推理部署引擎,为了控制变量,所有测试的上下文长度被严格固定在了10240tokens。
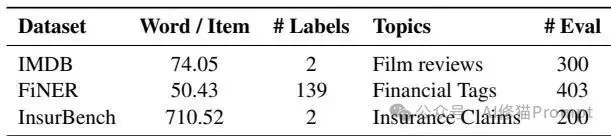
研究者选用了涵盖不同复杂度与垂直领域的三个数据集:
针对每个任务,研究者从公共技能库中抽取4-5个干扰性技能条目,与真实的(Ground-truth)技能混合,构建临时技能库。实验采用以下三种上下文工程策略:
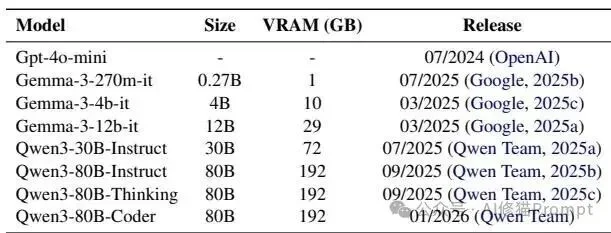
测试涵盖了从270M到80B参数量的开源模型阵列,以捕捉参数规模和训练目标的差异。主要模型包括:
除了分类准确率 (Cls ACC)、F1分数 (Cls F1) 和技能选择准确率 (Skill ACC) 外,研究者特别设计了两个面向工程部署成本的核心指标:
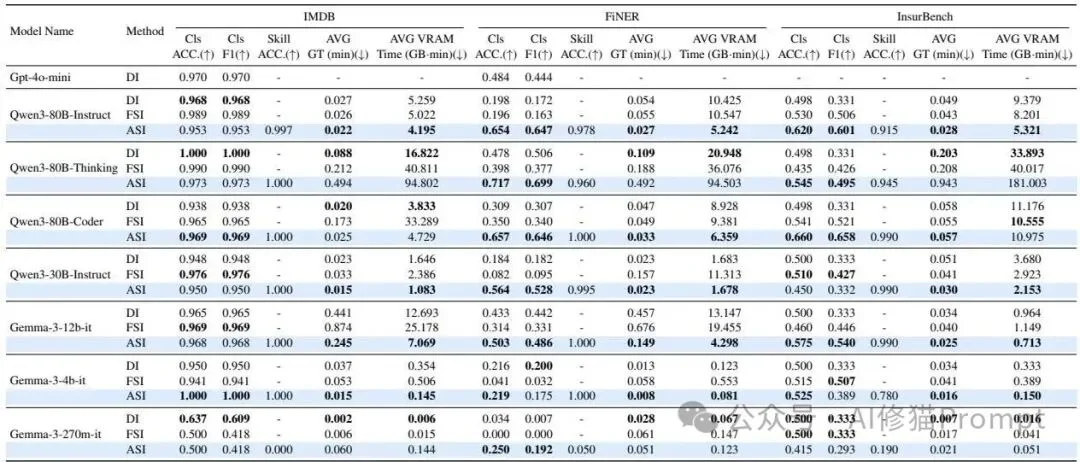
实验数据(主要集中在Table 3中展示)揭示了不同规模开源模型在工业环境中的能力阶层与应用边界。
实验配置中仅加入了4-6个干扰技能,理论上对模型而言,识别出正确技能的难度较低。然而,参数量极小的微型模型展现出了根本性的能力缺失。
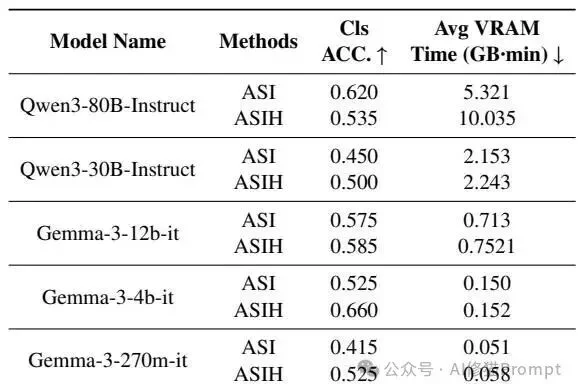
对于中等体量的模型,Agent Skill策略(ASI)相较于直接指令(DI)展现出了显著的性能提升,特别是在处理复杂专业数据时。
研究者对同为80B参数级别的Qwen3系列(Instruct指令微调版、Thinking思考版、Coder代码特化版)进行了深入对比。数据分析揭示了一个极具部署指导意义的结论:在Agent Skill框架下,代码模型是最高效且准确率极高的选择。
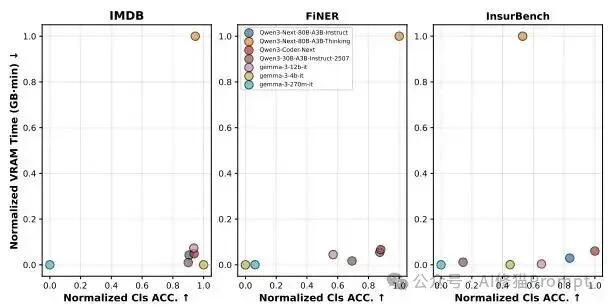
Avg VRAM Time 指标,差异极大。在FiNER上,Thinking变体的平均VRAM时间高达94.503 GB-min,而Coder变体仅为6.359 GB-min(缩减了近15倍)。在InsurBench任务中,Coder也将其控制在10.975 GB-min。 这些发现共同指出,工业级部署如果要在VRAM受限的情况下最大化吞吐量并维持准确性,将Agent Skill框架与代码特化模型结合是最优策略。这也在一定程度上解释了为何擅长代码逻辑的Claude系列模型在真实Agent社区中得到了最快速的采用。工业级自治智能体的开发场景中,项目可能需要搭载超过50种甚至上百种技能。为了探测模型的极限,研究者将备选技能数量(N))从5逐步扩展到了100,并记录了拟合衰减曲线。
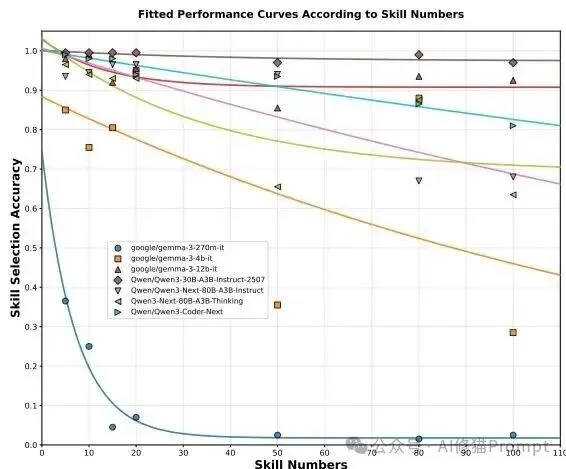
小型模型的迅速崩溃:对于Gemma-3-4b-it和270m等微型模型,当 N 超过10到20的阈值时,技能选择准确率出现断崖式下跌
SKILL.md 文件中嵌套的、分层级的技能揭示结构(即在技能描述中引用并触发另一个技能)。即便是闭源的GPT-4o-mini在准确解释这些层级关系时也偶尔会出错。在现阶段的CLI实验中,似乎只有Claude-Opus级别的超大模型能在这类层级解析中持续获得接近100% 的成功率。因此,在现阶段的SLM工程实践中,必须严格展平技能结构,避免内部的相互调用。学术界的测试往往是对已有架构的复盘,而开源社区的暴力迭代,总能在一夜之间重写机房里的选型手册。前文的硬核数据刚刚证明:用12B到30B的中等体量模型配合Agent Skill,是当前摆脱闭源API限制的最优解。但现实的工程痛点是,30B级别的模型依然会吃掉大量的服务器显存。
就在我们还在为这堵“显存墙”发愁时,现成的破局工具今天直接拍在了桌上。就在昨天Qwen团队正式开源了Qwen3.5系列基础模型。其中,定位中等体量的Qwen3.5-35B-A3B凭借极其离谱的“算力与精度交换比”,硬生生把本地Agent部署的硬件门槛干碎了。
在工业选型中,开发者部署本地模型的唯一理由就是“打平甚至超越商业API的测试数据”。Qwen3.5-35B-A3B在底层的混合架构设计上极为克制,总参数量虽达到35B,但凭借256个专家网络(8个路由专家 + 1个共享专家)的稀疏混合(MoE)设计,其每次前向传播仅激活3B参数。同时,它采用了一种独特的网络布局:10 × (3 × (Gated DeltaNet → MoE) → 1 × (Gated Attention → MoE))。这种Gated DeltaNet与稀疏MoE结合的混合架构,使其在极低的推理开销下斩获了越级的榜单成绩。
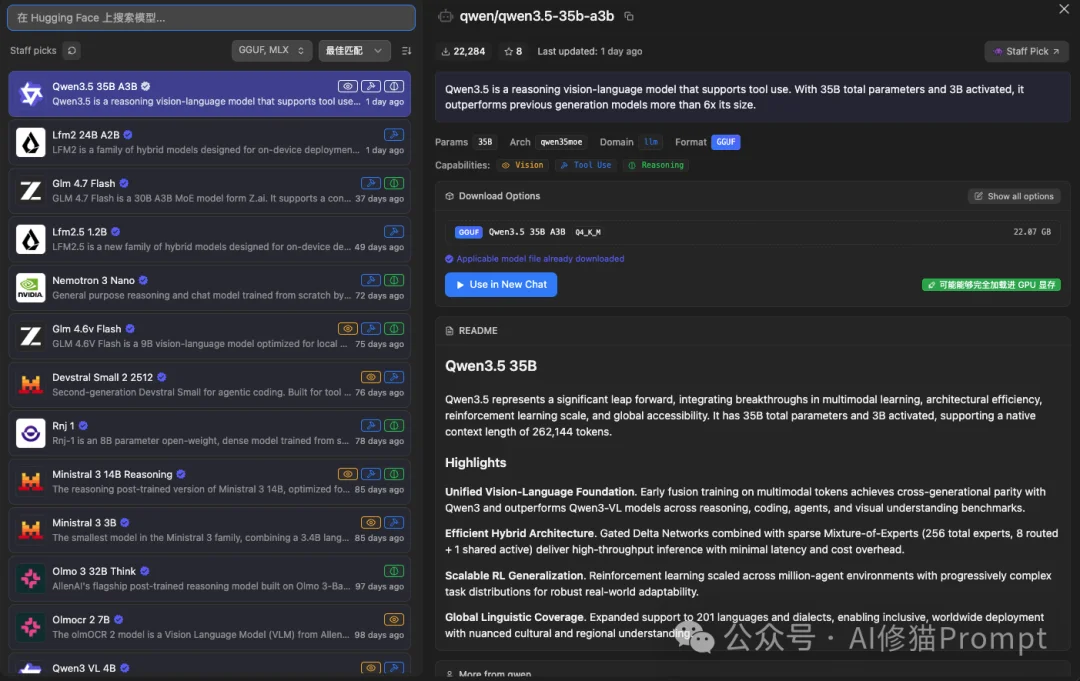
以下是Hugging Face的最新评测图表,这台仅有3B激活参数的“引擎”在多项核心指标上直接击穿了闭源基线:
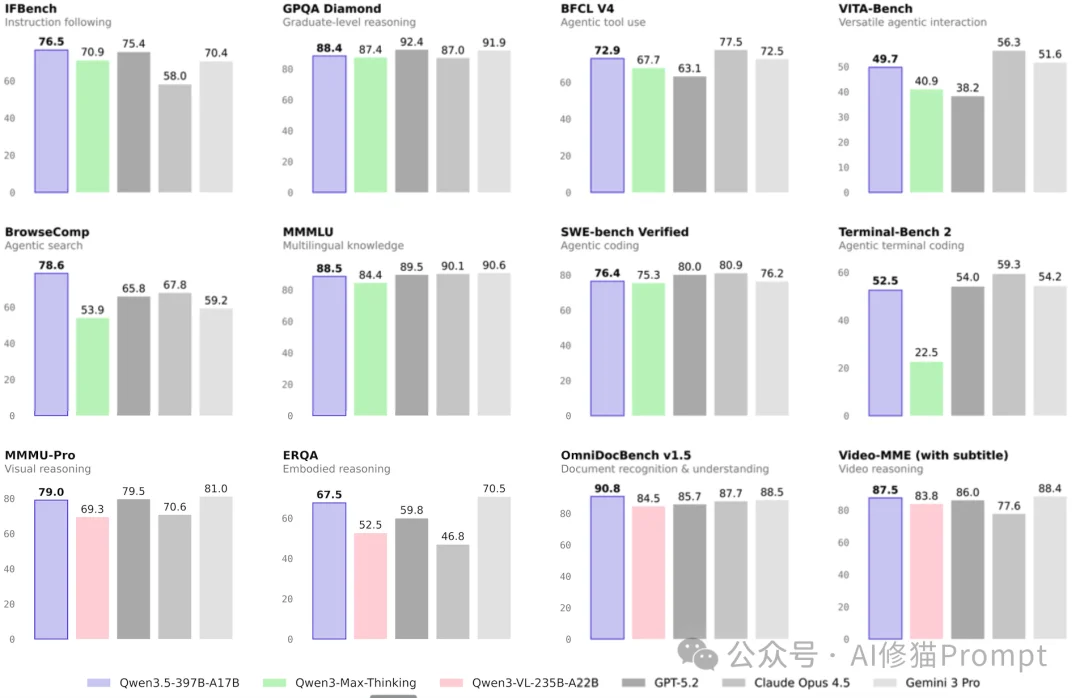
凭借原生262,144且可扩展至101万Token的超长上下文窗口,外加对201种语言的跨语种支持,这款模型在纸面数据上已经给足了作为本地Agent核心路由的理由。
35B全精度模型静态占用约70GB显存。对于配备单卡24GB显存,比如Mac mini、Mac Studio或配备RTX4090的机器,建议您采用Q4_K_M或动态4-bit量化格式。由于其激活参数仅3B,一旦加载进显存,其生成token的速度将极快。目前Qwen3.5-35B-A3B已在LM Studio、ollama中同步上线,您可以使用Ollama命令部署或者LM Studio图形界面直接部署。
ollama run qwen3.5:35
ollama launch openclaw --model qwen3.5:35b
如果是LM Studio部署的模型,在openclaw中,则可以使用openclaw config命令来加载您刚下载的模型
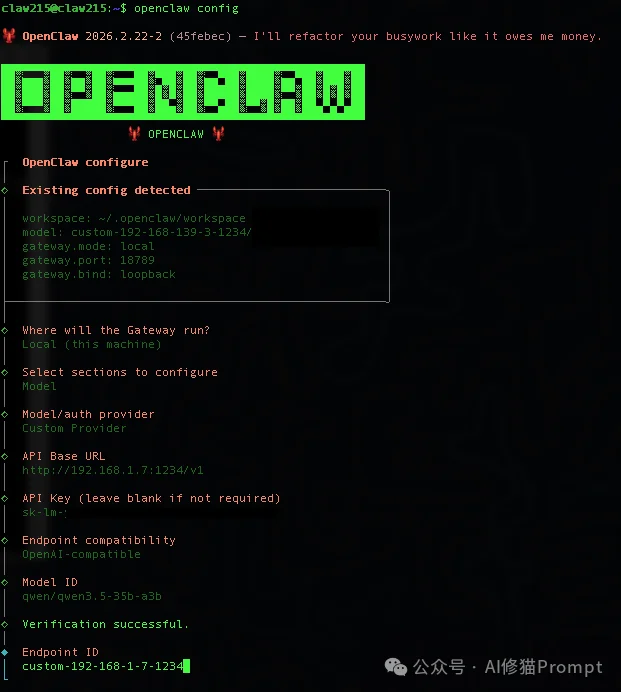
然后您就会收获一个不用外部模型API的openclaw。

在确定了模型选择范围后,研究者探讨了具体的工程实施细节。
针对InsurBench长历史对话数据,实验评估了在ASI模式下保留多轮对话历史(ASIH模式)的成本效益,通过确定性的截断策略保留系统提示词和最近的3-4轮对话。
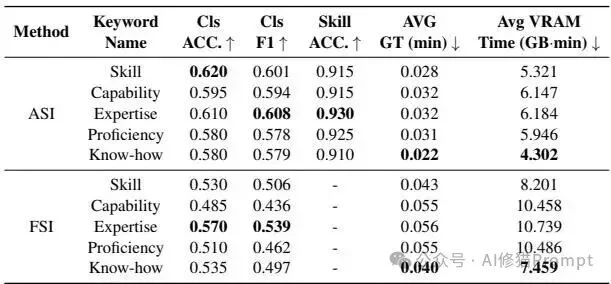
研究者进行了一项探索性实验,在提示词中将 "Skill" 替换为同义词 "Expertise" 可以在各项指标上持续取得更好的表现。 根据Table 5在InsurBench上的数据追踪:
从理论推演到机房实测,这份报告最终将复杂的 Agent Skill 落地难题简化为了三个极其具体的工程指标:4B 是死线,30B 是路由甜点,80B 代码模型是执行巅峰 。
我们不再需要盲目迷信 API,也不必在微型模型的“幻觉”中浪费时间。随着 Qwen3.5 等新一代高效能模型的加入,这套由“中等路由 + 强力执行”构成的本地化架构,已经具备了全面接管工业级任务的能力。对于每一位受困于数据隐私和 API 账单的架构师而言,这篇论文提供的不仅是数据,更是一张通往“Local-First”智能体时代的入场券。
文章来自于微信公众号 "AI修猫Prompt",作者 "AI修猫Prompt"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
