# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI智能体最大的「硬伤」,是算力不够?
并不是,奖励太少、路太长才是。
在稀疏奖励的长序列任务里,传统token-by-token探索像蒙眼走迷宫:没有路标、没有提示,只有走到终点才知道对不对。
结果就是一个尴尬现实:想让智能体做点复杂事,往往必须外挂规划器「扶着走」。
而谷歌这项研究直接换打法:在迷宫里要求智能体按顺序踏过一串彩色子目标,且只有全程无误才给奖励——用最残酷的稀疏奖励,逼出真正的层次化决策能力。
真正的突破在于:他们不再只优化输出,而是开始操控模型内部的「认知过程」。
在稀疏奖励下,
智能体如何高效探索
传统的大模型,依赖逐词生成(token-by-token)的探索方式,而这对于需要多个正确步骤才能获得奖励的复杂任务,由于奖励稀疏,导致智能体难以完成需要层次化决策的长序列任务。
这好比让一个人蒙着眼睛走迷宫,只有到达终点才能获得反馈,期间没有任何指引,不论这个人尝试多少次也找不到出口。
这导致当下的大模型智能体需要外带一个规划器,才能完成复杂的,需要多步才能完成的任务。而谷歌这项研究做的,就是让智能体在迷宫中,按特定顺序访问一系列彩色位置(子目标),且只有在完全正确的序列完成后才能获得奖励。
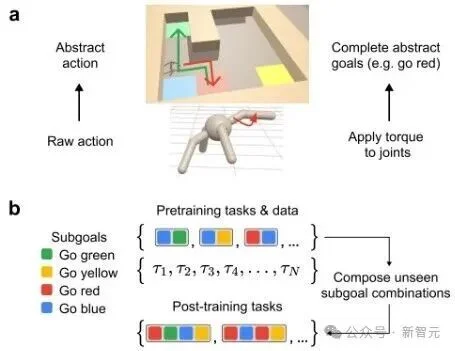
图1:智能体需要在迷宫中按顺序走过不同颜色的方块
这种「组合式任务」要求智能体必须掌握层次化解决问题的能力,不止需要低级的运动控制技能,又需要高级的时序规划能力。
这就如同人类搬运水杯的任务,相当于执行「拿起水杯→走到桌前→放下水杯」这样的连贯动作。
「大脑中的大脑」
AI自我发现抽象动作
那谷歌团队是如何解决稀疏奖励带来的问题的?
答案是元控制器(Metacontroller)。
元控制器通过接收基模型的残差流,能够生成一系列简单的内部控制器。
每个控制器对应一个时序抽象动作,每个时序抽象动作对应一个时间轴,并附带终止条件。通过按时间组合多个控制器,智能体能够在新任务上实现高效探索。
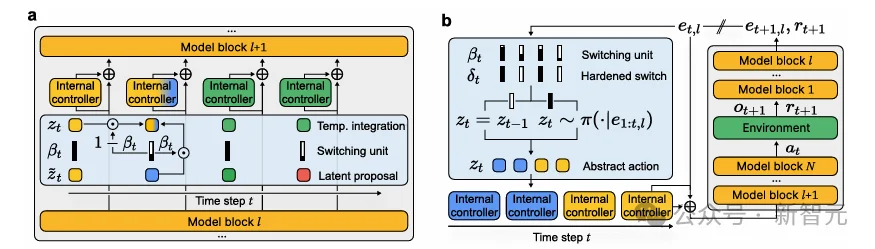
图2:元控制器引导预训练自回归模型的残差流激活。
通过自监督的下一步动作预测,元控制器发现如何生成时间上稀疏变化的简单内部控制器序列 。
在分层结构任务中,每个内部控制器对应一个时序抽象动作,引导基础自回归模型实现一个有意义的初级目标。
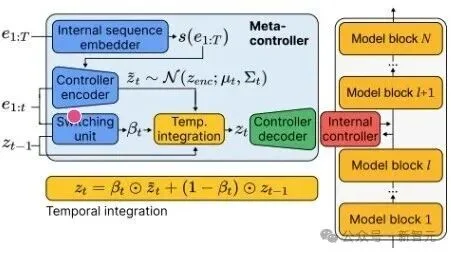
图3:元控制器的架构
经由强化学习,研究者发现元控制器能够通过变分推理自动识别有意义的行为模块,这相当于无监督发现抽象动作该怎么完成。
用上元控制器,训练机器人给人泡茶,就不必由手工编码将任务拆解成多步了。
此外,元控制器还能动态时间整合,它能通过开关单元控制抽象每一步动作的持续时间。并且能组合泛化,将学到的抽象动作重新组合解决新任务。
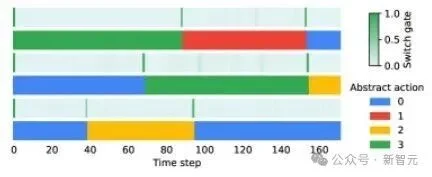
图4:自监督元控制器在预训练的自回归模型中发现时序抽象动作。
元控制器学习到的开关模式还能与真实子目标切换完美对齐,尽管模型从未接收过子目标标签。这种根据环境,切换使用那个子目标的方式是涌现产生的,表明模型内部形成了类似「选项」的分层结构。
内部强化学习
提效数个量级的新训练范式
该研究最令人惊讶的,是使用元控制器后的内部强化学习,与传统强化学习在原始动作空间进行微调不同,内部强化学习在发现的抽象动作空间中进行学习,搜索空间大幅减小。在需要组合泛化的任务中,内部强化学习的成功率显著高于所有基线方法,包括先前最先进的分层强化学习方法CompILE。
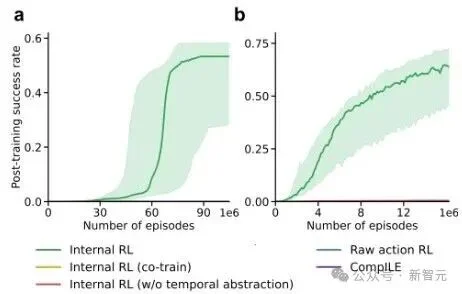
图5:不同强化学习方式的成功率
之所以智能体能够以更大的可能性,学会某一个需要多步骤才能完成的任务,是因为有了元控制器,模型隐含地学会了将长序列任务分解为可重用的子程序(如「移动到某色块」),这就让搜索空间变小,奖励也不再稀疏。
相当于通过对动作空间降维,将高维残差流空间压缩到低维抽象空间。再加上在抽象时间尺度上操作,缩短有效时间跨度。使得在抽象层面进行奖励分配更加高效。
「觉醒-睡眠」训练循环的具体实现
在2015年的论文[2]中,Jürgen Schmidhuber提出了「觉醒-睡眠」训练循环的理论框架。
其核心思想是构建一个迭代的、自我改进的循环,两个阶段交替执行,旨在构建能够形成并利用时间抽象和计划能力的自主智能系统。
睡眠阶段智能体回顾其过往的经历(观察和行动序列),通过自监督学习训练一个内部世界模型。
「觉醒」阶段智能体利用在「睡眠」阶段学到的世界模型内部表征,进行强化学习和规划,以发现新的、有价值的行为。在「觉醒」阶段获得的新经验数据,又会被加入到经验库中,用于下一轮的「睡眠」阶段,以改进世界模型。
而谷歌的这项研究,可看成是「觉醒-睡眠」训练循环的具体实现,自回归基础模型预训练对应睡眠阶段。模型通过下一个token(此处是下一动作或观察)预测的目标,在大量未标注的行为数据上进行训练。
这个过程正是自监督学习,模型学会了推断智能体的潜在目标(如子目标),并在其残差流激活中形成了时间抽象的表征。
觉醒阶段则是元控制器及其驱动的内部强化学习。它学习如何操控基础模型(世界模型)的内部残差流激活,从而生成有意义的、持续多个时间步的抽象动作(如「前往蓝色位置」)。
这相当于在世界模型的内部状态空间中进行规划和控制。
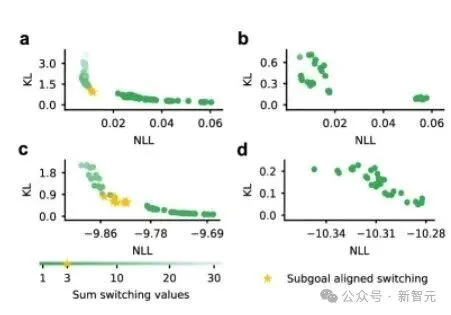
图6:在发现时序抽象动作时,预训练的自回归模型被冻结的重要性。
而只有如图6所示,当基础自回归模型在元控制器训练期间被冻结时,才会涌现出与子目标对齐的正确切换表征。
这一发现强烈支持了「觉醒-睡眠」循环的分阶段迭代思想:首先通过预训练建立一个高质量、稳定的世界模型(基础模型)。
然后,在此基础上,再通过元控制器学习驱动内部强化学习,从而学到控制策略。
如果两者同时训练(共训练),模型会收敛到一个退化的解决方案,无法发现有意义的时间抽象。
这印证了分阶段、迭代式训练的理论优越性。而这符合Jürgen Schmidhuber提出的「先睡眠(构建模型)、后觉醒(学习控制)」的循环训练方案。
终结随机鹦鹉争论
在大模型研究中,一直有批评人士认为自回归模型无论参数量多大,都不过是「随机鹦鹉」,难以形成一致的时间抽象和规划。
而该研究表明,预测下一个词的训练方式,只要结合元控制器,就能够诱导出层次化的时间抽象,这与人类的问题解决方式高度相似。
在不依赖手动奖励塑形的情况下解决需要多步才能完成的任务,是迈向能够导航复杂、开放式搜索空间的自主智能体的关键一步,在这些空间中,中间进度的定义往往未知。
谷歌团队的这项研究标志着AI研究从单纯优化模型输出,转向理解和操控模型内部认知过程,为开发具有真正层次化推理能力的通用AI系统提供了坚实的实践基础,说明了模仿人类睡眠,才能够实现复杂时间序列任务的高效学习。
与稀疏自编码器(SAEs)等解释性方法相比,元控制器具有显著优势。它直接通过残差流干预降低预测误差,具有内部记忆,支持长时间跨度的干预,且能够发现可解释的、长时间持续的干预策略。
这项技术的潜在应用极其广泛。
在机器人控制中,可让机器人执行需要多步协调的复杂任务;对于数学推理,能自主将复杂问题分解为可管理的推理步骤;对于科学发现,也可让智能体在稀疏奖励环境中进行高效探索和假设检验。
谷歌提出的内部强化学习范式,尤其适合需要长期规划和组合推理的场景,为实现真正通用的智能系统提供了新路径。
参考资料:
https://arxiv.org/abs/2512.20605
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
