# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
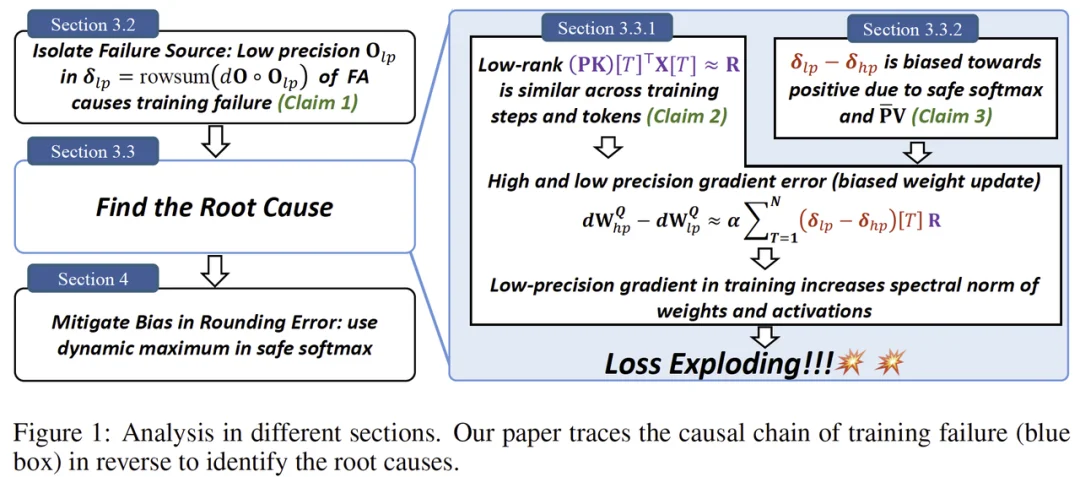
因果链总览(论文 Figure 1)

大模型训练的现实是:显存和吞吐决定一切。工业界普遍在混合精度里使用 BF16/FP16,甚至把 FFN 推到 FP8,以换取更高的训练效率。但工程实践同样残酷:越接近 “极限精度”,训练越容易出现难以解释的不稳定。
Flash Attention 是长上下文训练的关键加速组件,几乎成了标配。问题在于,社区长期存在一个可复现却难以解释的失败案例:
这类问题被报告了多年(相关 issue 在多个开源项目里反复出现),却一直缺少一条能 “从数值误差一路解释到 loss 爆炸” 的机制链。

作者的做法很工程,且足够 “可复现”:
1. 严格复现失败:GPT-2(12 层、12 头、d=768、context=1024),OpenWebText 预训练;并且通过记录并重放相同的数据 batch 序列,把数据顺序带来的随机性排除掉。
2.定位到层、头:用谱范数(spectral norm)等指标快速缩小范围,发现异常主要来自某一层注意力模块,甚至少数几个 attention head。

结果就是:权重更新被 “带偏”,谱范数和激活异常增长,最终把训练推到 loss 爆炸。
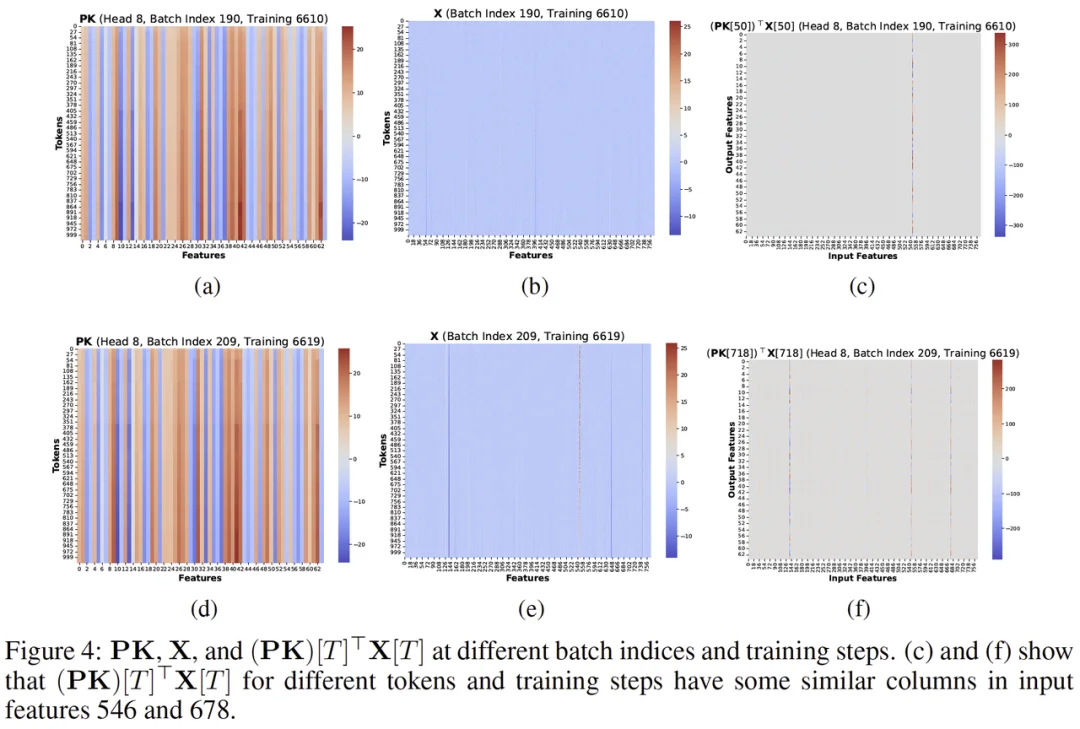
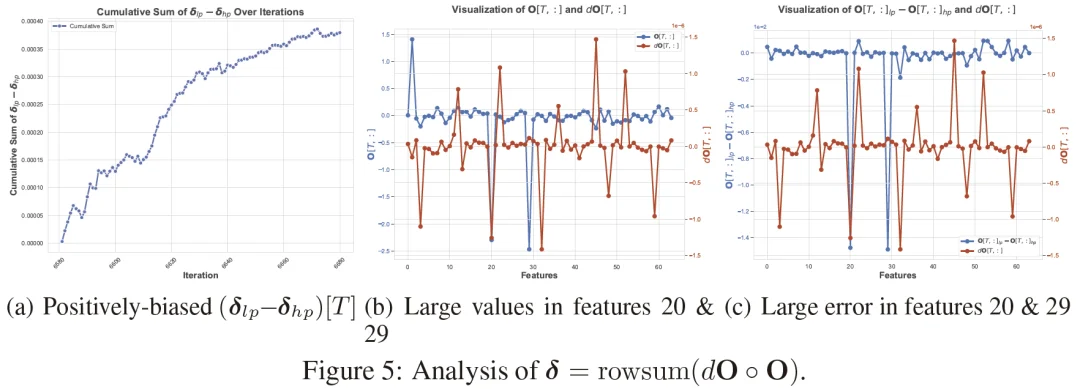
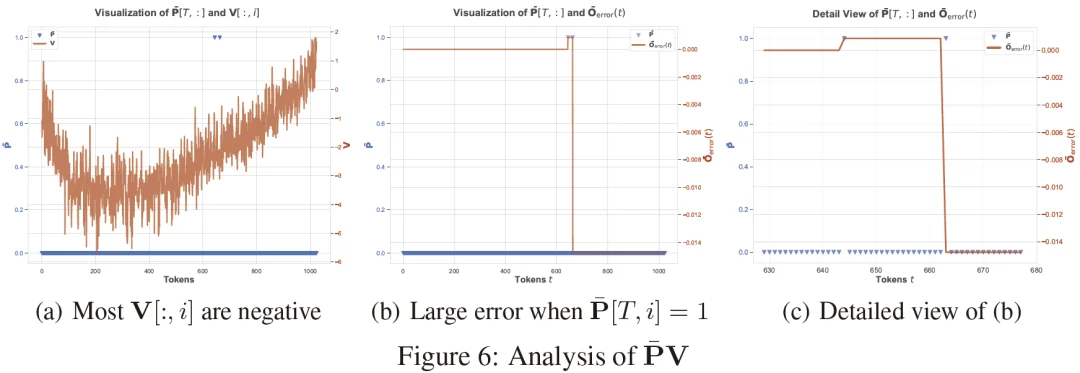
低秩结构相似性与偏置累积(论文 Figure 4/5)



论文给出的实现(概念上)如下:
rm = rowmax (S)
rs = rowsum (S == rm) # 最大值出现次数
if rs > 1 and rm > 0: m = β * rm (β > 1)
if rs > 1 and rm < 0: m = 0
else: m = rm
Pbar = exp (S - m) # 从而 max (Pbar) < 1

论文在 BF16 设置下验证了上述分析与修复:
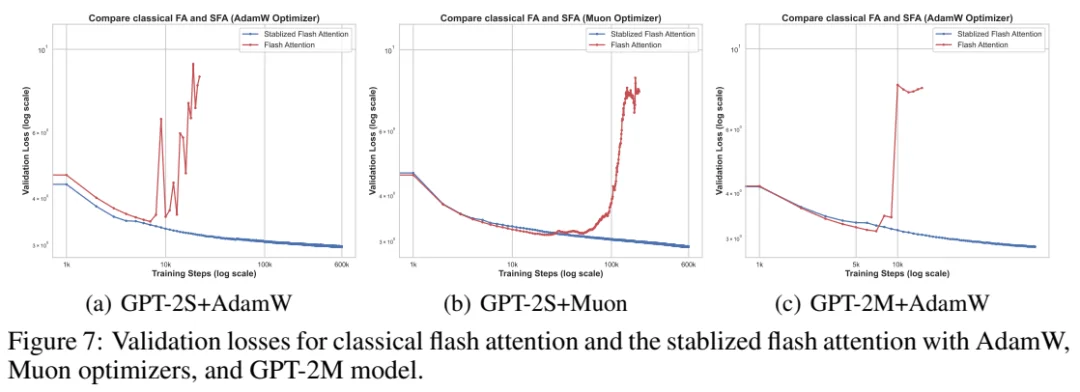
验证集 loss 曲线对比(论文 Figure 7)
这篇论文的价值不只在 “修了一个 bug”,更在于给出了一个可迁移的诊断范式:
邱海权是清华大学在读博士研究生,研究方向涵盖机器学习理论、表示学习与大模型机制分析。他的研究围绕模型表达能力、结构归纳偏置以及参数空间几何与优化动力学之间的内在联系展开,关注模型在不同结构约束与训练条件下的泛化行为与可组合性问题。整体上,他强调以可分析的理论框架刻画模型的能力边界与机制来源,从结构与原理层面理解深度模型为何有效、何时失效。
姚权铭,清华大学电子工程系副教授。长期致力于数据高效学习与智能体系统研究,在少样本学习、图学习、知识图谱与生物医药智能等方向取得系统性成果。发表 Nature 子刊、TPAMI、JMLR、ICML、NeurIPS、ICLR 等论文 130 余篇,被引 1.4 万余次。代表性工作包括抗噪学习算法 Co-teaching、小样本学习综述、自动化图学习方法及新药物相互作用预测模型。现任 TPAMI、TMLR 编委及 Neural Networks 资深编委,多次担任 ICML、NeurIPS、ICLR 领域主席,入选 IEEE Computing Top 30、IET Fellow 等。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
