# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效?
别急,丰田研究院(TRI)和清华大学刚刚发布了一份「保姆级」教程。为了搞清楚这些问题,他们真的「拼了」—— 这项研究使用了 4000 小时的机器人与人类操作数据,5000 万个视觉 - 语言样本,训练了 89 个不同的策略模型,并在 58000 次仿真评估和 2835 次真机测试中进行了验证。
这不仅仅是一篇论文,更是一份关于大型行为模型(Large Behavior Model,LBM)训练数据与策略的避坑指南。
先来看看这个 Demo:得益于 Co-training 打下的坚实基础,这是模型在解锁从未见过的长程、灵巧操作任务时的表现:

本研究的核心聚焦于 Co-training(协同训练)。简单来说,就是别只盯着昂贵的机器人数据薅羊毛。Co-training 主张让机器人「博采众长」,同时从目标机器人的数据和其他异构数据模态(比如互联网上的图文数据、人类视频、其他机器人的数据、离散动作表征)中学习。
这听起来很完美,但在 TRI 这篇论文出来之前,并没有人系统性地告诉我们:到底哪种「外援」数据最好用?怎么用才最有效?

五大模态,三种策略:地毯式搜索「最佳配方」
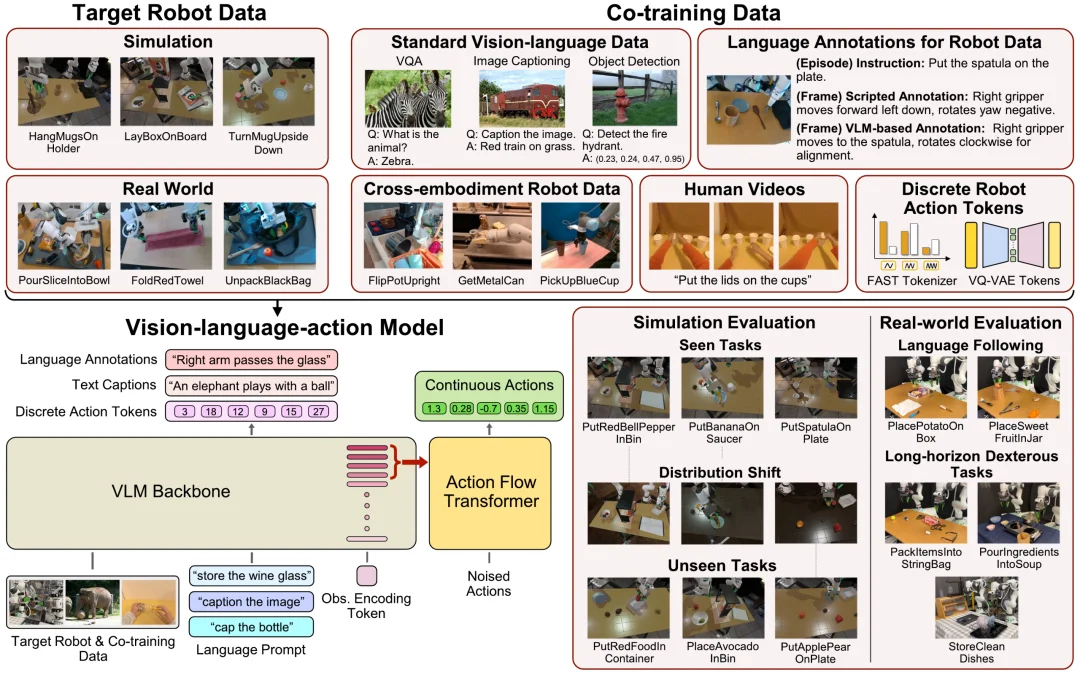
为了找到训练 VLA 的「圣杯」,研究团队系统地研究了以下五种 Co-training 数据模态:
团队也对比了三种训练策略:
精巧的模型架构
TRI 采用了 VLM + Action Flow Transformer 的架构。与 π0 等架构不同,本文并没有使用所有层的 KV,而是通过一个特殊的 Observation Encoding Token 来压缩视觉语言特征。实验证明,这种压缩的单 token 的表征方式,比复杂的全量特征在泛化性上更强!
实验结果:谁是「真大腿」,谁是「伪概念」?
为了验证上述模态与策略的有效性,研究团队进行了史上最大规模的系统评估,涵盖了分布内任务、分布外场景、未见任务以及真机环境下的语言指令跟随能力。
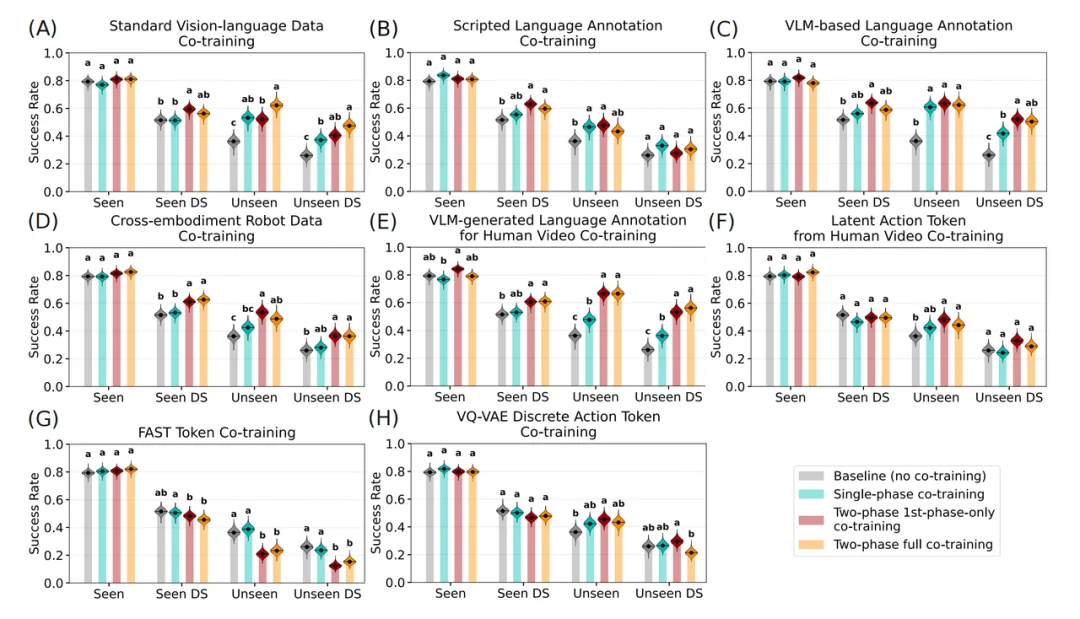
对所有模态的模拟器实验
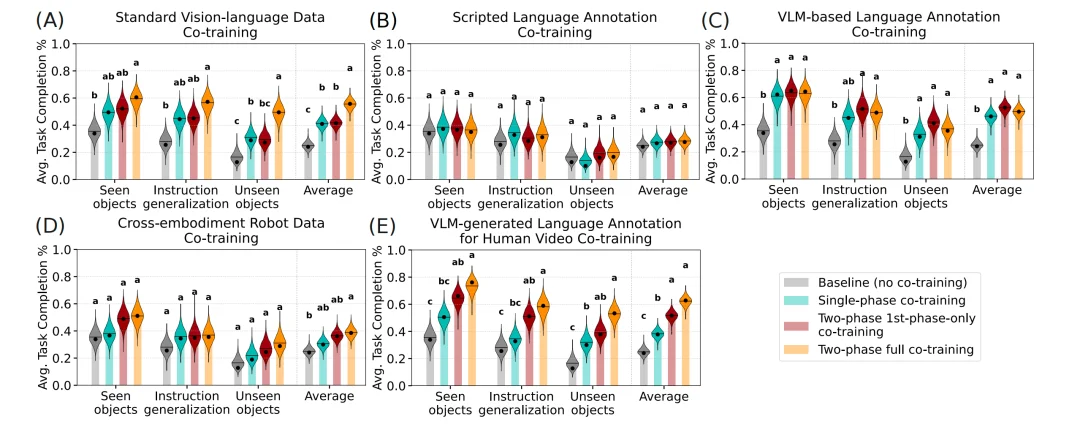
对有效模态的真机实验
红榜:泛化能力的「硬通货」
1.引入「多样的视觉 - 语言数据」和「跨具身机器人数据」,能显著提升模型对分布外场景、未见任务以及语言指令跟随的适应能力。
2. 不同模态的「最佳打开方式」不同:
3. 「三巨头」揭示了 VLM 的本质:在所有有效的协同训练模态中,「标准视觉 - 语言数据」「VLM 生成的机器人数据标注」,以及「人类视频的语言标注」效果最为显著。 这三者本质上都属于多样的视觉 - 语言数据,这有力地证明了:增强 VLM 基座的视觉 - 语言理解能力,能够直接转化为更强的机器人策略。
黑榜:离散动作 Token 的「祛魅」时刻
尽管「动作 Token 化」是近期的研究热点,但本研究发现:
值得注意的是,无论引入何种协同训练数据,对于训练集中已经见过的任务,性能基本维持不变。Co-training 的核心价值在于提升「泛化性」。
组合模态的威力与模型表征的质变
既然明确了有效模态,将它们组合起来是否有累积效应?答案是肯定的。
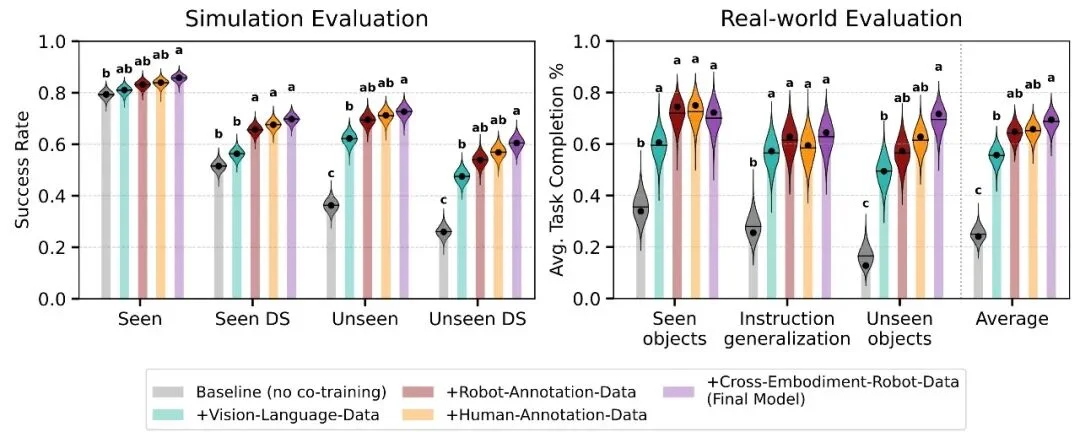
研究团队将所有有效模态组合训练得到的模型,在各项指标上全面超越了仅用机器人数据训练的模型。特别是在真实世界的语言指令跟随任务中,平均完成率提升了 45.3%;在仿真环境的未见任务中,成功率提升了 36.4%。
Co-training 的价值远不止于此,它还极大提升了模型的表征质量与快速适应能力。在微调实验中,仅使用 200 条演示数据,经过 Co-training 的模型就能迅速掌握全新的长程灵巧操作任务(如收纳袋子、整理碗碟),展现出远超无 Co-training 模型的动作精度与稳定性。


除了下游的机器人操作性能,研究团队还深入分析了 Co-training 如何重塑 VLM 主干网络。团队在涵盖语义理解、空间推理和长程推理的一系列标准视觉 - 语言基准上,对策略模型中提取出的 VLM 进行了评测。
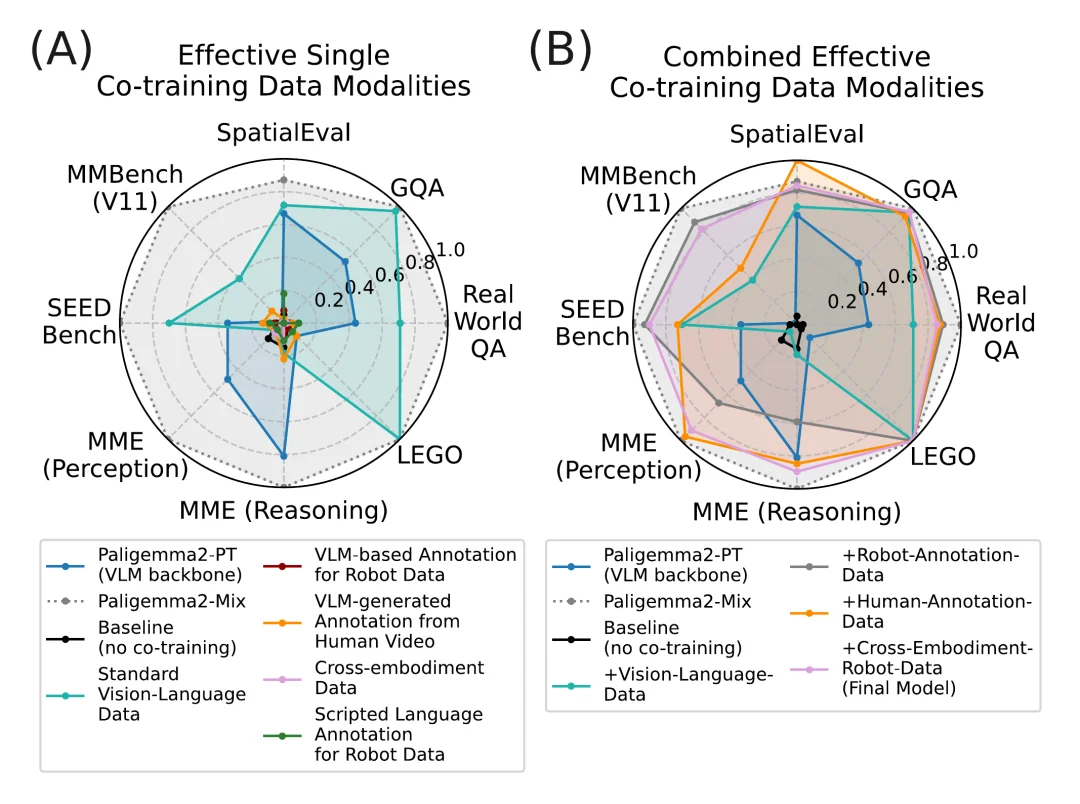
实验结果显示,未经过 Co-training 的模型在通用视觉语言基准上分数大幅下降,而有效的 Co-training 能够帮助模型保留这些理解能力。经过 Co-training 的模型不仅保留了通用的视觉语言能力,甚至在空间推理等维度上优于原始的 VLM 权重。
这证明:一个保持了世界理解能力的 VLM Backbone,是构建高性能机器人策略的基础。
CoT (思维链) 失灵了?
鉴于 VLM 强大的推理能力,显式地进行「思维链(CoT)」推理是否能提升性能?
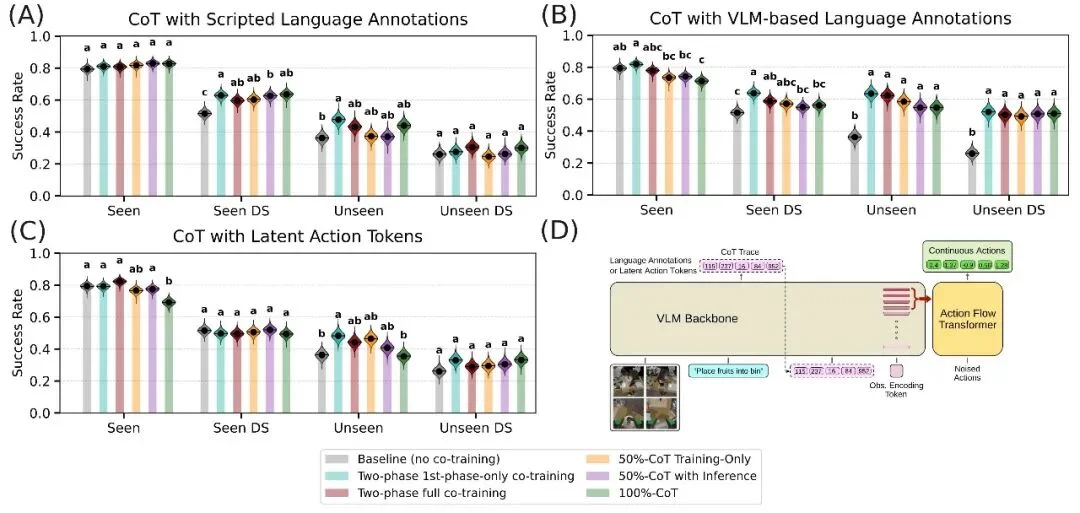
研究团队尝试让模型在输出动作前,先显式生成从 Co-training 数据中学到的中间推理步骤。
结果令人意外:与仅将 CoT 内容作为辅助训练目标相比,显式 CoT 条件化并没有带来性能提升。可见对于目标明确、反馈即时的物理操作任务,Co-training 带来的隐式推理已经足够。
这篇论文的内容远不止于此。除了上述结论,文中还包含了大量关于:
如果你正致力于训练通用的机器人大脑,这篇论文绝对值得加入你的必读列表!
关于作者

本研究的第一作者是林凡淇,清华大学交叉信息研究院二年级博士生,师从高阳教授。该工作是他在丰田研究院(TRI)LBM 团队实习期间完成的。
他的研究聚焦于具身智能与机器人学习,致力于利用大规模数据与基础模型,使机器人获得人类水平的操作能力。他的多篇论文发表于 ICLR、CoRL、ICRA、IROS 等顶级会议,并多次获得 Best Paper 或 Oral 荣誉。其代表性工作包括 Co-training LBMs、OneTwoVLA、Data Scaling Laws 等,主要围绕大规模具身模型(如 VLA)与数据的构建展开。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
